 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Debiasing for Unbiased Parameter Recovery
Feb 17, 2025



Advances in machine learning and the increasing availability of high-dimensional data have led to the proliferation of social science research that uses the predictions of machine learning models as proxies for measures of human activity or environmental outcomes. However, prediction errors from machine learning models can lead to bias in the estimates of regression coefficients. In this paper, we show how this bias can arise, propose a test for detecting bias, and demonstrate the use of an adversarial machine learning algorithm in order to de-bias predictions. These methods are applicable to any setting where machine-learned predictions are the dependent variable in a regression. We conduct simulations and empirical exercises using ground truth and satellite data on forest cover in Africa. Using the predictions from a naive machine learning model leads to biased parameter estimates, while the predictions from the adversarial model recover the true coefficients.
Discovering influential text using convolutional neural networks
Jun 14, 2024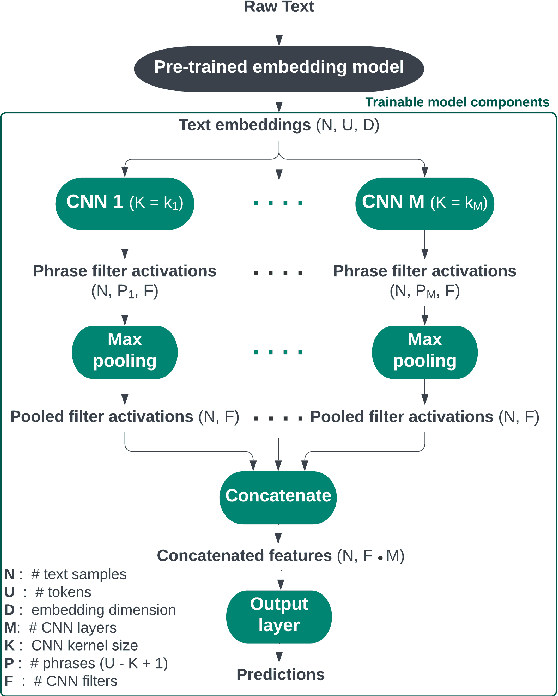

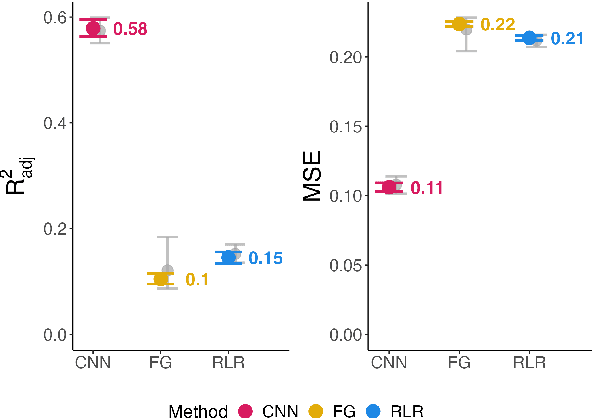
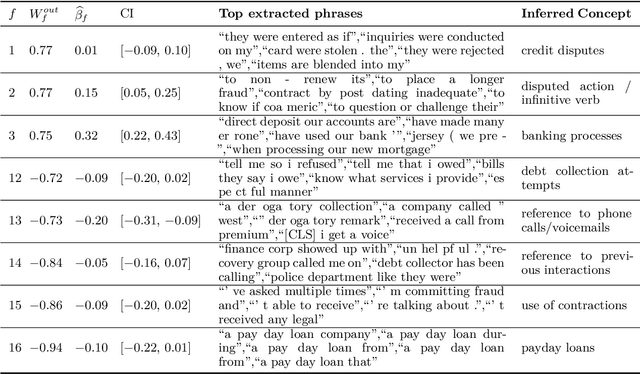
Experimental methods for estimating the impacts of text on human evaluation have been widely used in the social sciences. However, researchers in experimental settings are usually limited to testing a small number of pre-specified text treatments. While efforts to mine unstructured texts for features that causally affect outcomes have been ongoing in recent years, these models have primarily focused on the topics or specific words of text, which may not always be the mechanism of the effect. We connect these efforts with NLP interpretability techniques and present a method for flexibly discovering clusters of similar text phrases that are predictive of human reactions to texts using convolutional neural networks. When used in an experimental setting, this method can identify text treatments and their effects under certain assumptions. We apply the method to two datasets. The first enables direct validation of the model's ability to detect phrases known to cause the outcome. The second demonstrates its ability to flexibly discover text treatments with varying textual structures. In both cases, the model learns a greater variety of text treatments compared to benchmark methods, and these text features quantitatively meet or exceed the ability of benchmark methods to predict the outcome.