 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering influential text using convolutional neural networks
Jun 14, 2024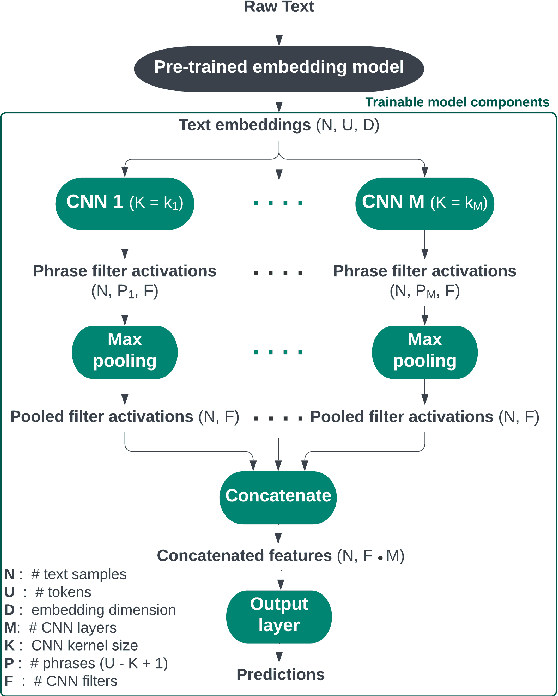

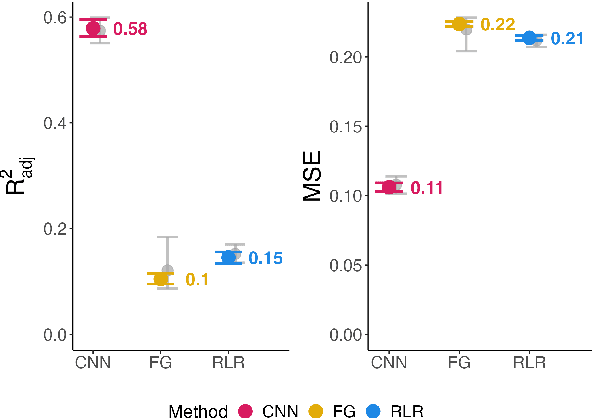
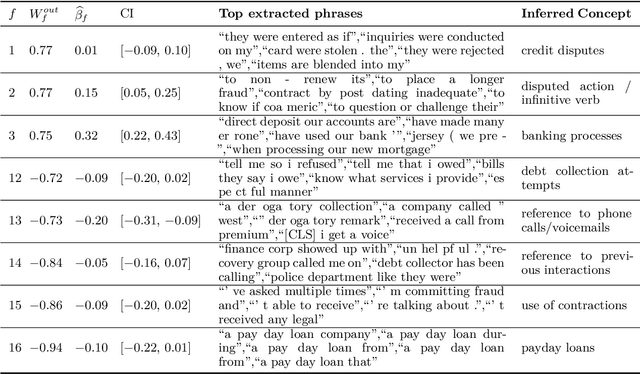
Experimental methods for estimating the impacts of text on human evaluation have been widely used in the social sciences. However, researchers in experimental settings are usually limited to testing a small number of pre-specified text treatments. While efforts to mine unstructured texts for features that causally affect outcomes have been ongoing in recent years, these models have primarily focused on the topics or specific words of text, which may not always be the mechanism of the effect. We connect these efforts with NLP interpretability techniques and present a method for flexibly discovering clusters of similar text phrases that are predictive of human reactions to texts using convolutional neural networks. When used in an experimental setting, this method can identify text treatments and their effects under certain assumptions. We apply the method to two datasets. The first enables direct validation of the model's ability to detect phrases known to cause the outcome. The second demonstrates its ability to flexibly discover text treatments with varying textual structures. In both cases, the model learns a greater variety of text treatments compared to benchmark methods, and these text features quantitatively meet or exceed the ability of benchmark methods to predict the outcome.
Algorithmic Censoring in Dynamic Learning Systems
May 15, 2023



Dynamic learning systems subject to selective labeling exhibit censoring, i.e. persistent negative predictions assigned to one or more subgroups of points. In applications like consumer finance, this results in groups of applicants that are persistently denied and thus never enter into the training data. In this work, we formalize censoring, demonstrate how it can arise, and highlight difficulties in detection. We consider safeguards against censoring - recourse and randomized-exploration - both of which ensure we collect labels for points that would otherwise go unobserved. The resulting techniques allow examples from censored groups to enter into the training data and correct the model. Our results highlight the otherwise unmeasured harms of censoring and demonstrate the effectiveness of mitigation strategies across a range of data generating processes.