 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring What Matters: Synthetic Benchmarks for Concept Bottleneck Models
Jun 03, 2026Concept bottleneck models predict outcomes from high-level concepts detected in inputs. Although concepts provide a simple way to reap benefits from interpretability, very few datasets include concept labels. This limits researchers' ability to determine which problems are suitable for these models, isolate the factors that drive their performance or lead to failures, or uncover which algorithms perform well. In this paper, we develop synthetic benchmarks for concept-bottleneck models, focusing on their two main use cases: decision support, in which models assist humans in making better decisions, and automation, in which models handle routine tasks without supervision. Our benchmarks can generate labeled datasets while controlling for properties that affect performance, including data modality, concept choice, annotation quality, and completeness. We demonstrate how the benchmarks can be used to evaluate representative classes of concept bottleneck models. Our demonstrations show how the benchmarks can diagnose failure modes and guide follow-up testing.
Statistical Inference for Responsiveness Verification
Jul 02, 2025Many safety failures in machine learning arise when models are used to assign predictions to people (often in settings like lending, hiring, or content moderation) without accounting for how individuals can change their inputs. In this work, we introduce a formal validation procedure for the responsiveness of predictions with respect to interventions on their features. Our procedure frames responsiveness as a type of sensitivity analysis in which practitioners control a set of changes by specifying constraints over interventions and distributions over downstream effects. We describe how to estimate responsiveness for the predictions of any model and any dataset using only black-box access, and how to use these estimates to support tasks such as falsification and failure probability estimation. We develop algorithms that construct these estimates by generating a uniform sample of reachable points, and demonstrate how they can promote safety in real-world applications such as recidivism prediction, organ transplant prioritization, and content moderation.
Regretful Decisions under Label Noise
Apr 12, 2025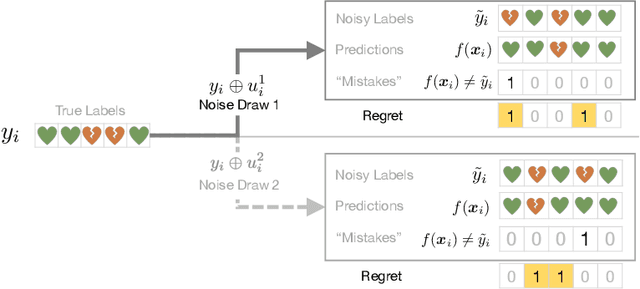


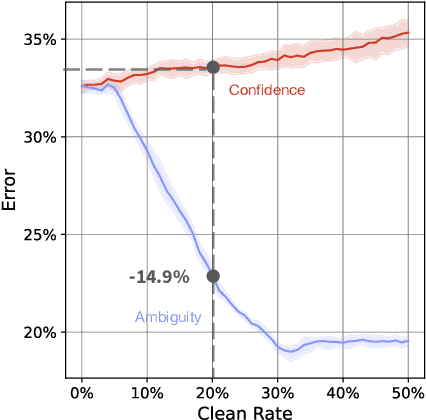
Machine learning models are routinely used to support decisions that affect individuals -- be it to screen a patient for a serious illness or to gauge their response to treatment. In these tasks, we are limited to learning models from datasets with noisy labels. In this paper, we study the instance-level impact of learning under label noise. We introduce a notion of regret for this regime which measures the number of unforeseen mistakes due to noisy labels. We show that standard approaches to learning under label noise can return models that perform well at a population level while subjecting individuals to a lottery of mistakes. We present a versatile approach to estimate the likelihood of mistakes at the individual level from a noisy dataset by training models over plausible realizations of datasets without label noise. This is supported by a comprehensive empirical study of label noise in clinical prediction tasks. Our results reveal how failure to anticipate mistakes can compromise model reliability and adoption, and demonstrate how we can address these challenges by anticipating and avoiding regretful decisions.
Understanding Fixed Predictions via Confined Regions
Feb 22, 2025Machine learning models are designed to predict outcomes using features about an individual, but fail to take into account how individuals can change them. Consequently, models can assign fixed predictions that deny individuals recourse to change their outcome. This work develops a new paradigm to identify fixed predictions by finding confined regions in which all individuals receive fixed predictions. We introduce the first method, ReVer, for this task, using tools from mixed-integer quadratically constrained programming. Our approach certifies recourse for out-of-sample data, provides interpretable descriptions of confined regions, and runs in seconds on real world datasets. We conduct a comprehensive empirical study of confined regions across diverse applications. Our results highlight that existing point-wise verification methods fail to discover confined regions, while ReVer provably succeeds.
Concept Bottleneck Large Language Models
Dec 11, 2024



We introduce the Concept Bottleneck Large Language Model (CB-LLM), a pioneering approach to creating inherently interpretable Large Language Models (LLMs). Unlike traditional black-box LLMs that rely on post-hoc interpretation methods with limited neuron function insights, CB-LLM sets a new standard with its built-in interpretability, scalability, and ability to provide clear, accurate explanations. We investigate two essential tasks in the NLP domain: text classification and text generation. In text classification, CB-LLM narrows the performance gap with traditional black-box models and provides clear interpretability. In text generation, we show how interpretable neurons in CB-LLM can be used for concept detection and steering text generation. Our CB-LLMs enable greater interaction between humans and LLMs across a variety of tasks -- a feature notably absent in existing LLMs. Our code is available at https://github.com/Trustworthy-ML-Lab/CB-LLMs.
Classification with Conceptual Safeguards
Nov 07, 2024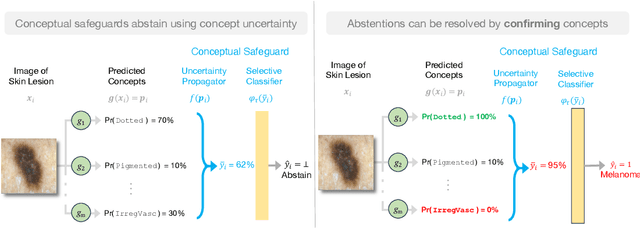
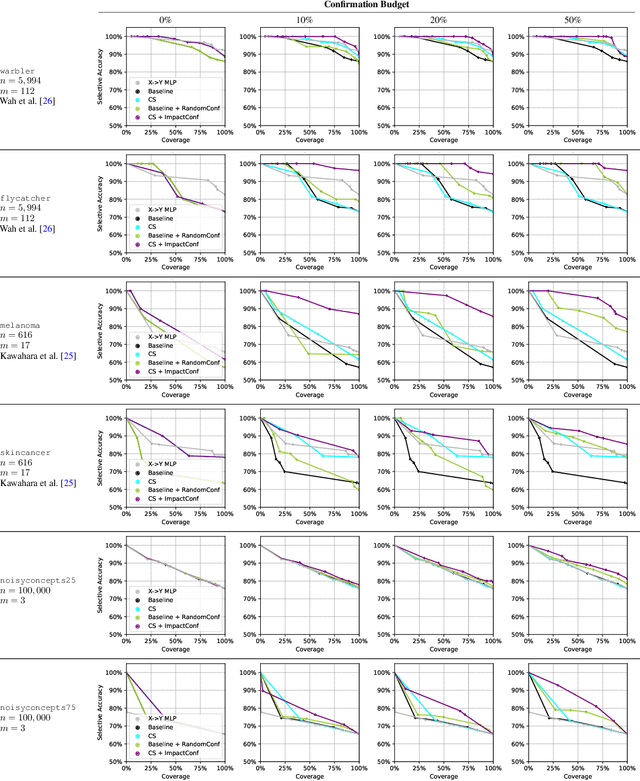
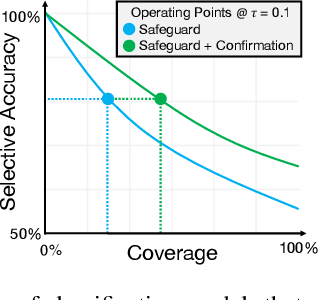
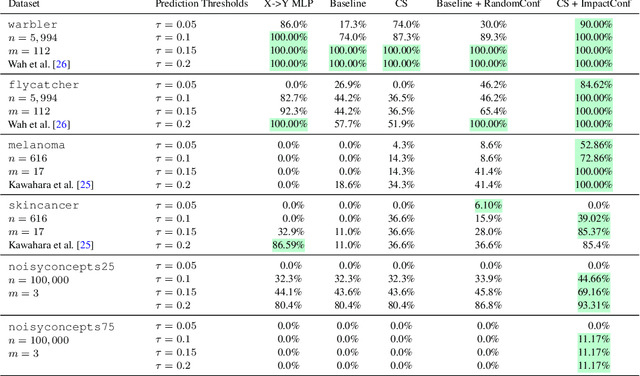
We propose a new approach to promote safety in classification tasks with established concepts. Our approach -- called a conceptual safeguard -- acts as a verification layer for models that predict a target outcome by first predicting the presence of intermediate concepts. Given this architecture, a safeguard ensures that a model meets a minimal level of accuracy by abstaining from uncertain predictions. In contrast to a standard selective classifier, a safeguard provides an avenue to improve coverage by allowing a human to confirm the presence of uncertain concepts on instances on which it abstains. We develop methods to build safeguards that maximize coverage without compromising safety, namely techniques to propagate the uncertainty in concept predictions and to flag salient concepts for human review. We benchmark our approach on a collection of real-world and synthetic datasets, showing that it can improve performance and coverage in deep learning tasks.
Feature Responsiveness Scores: Model-Agnostic Explanations for Recourse
Oct 29, 2024
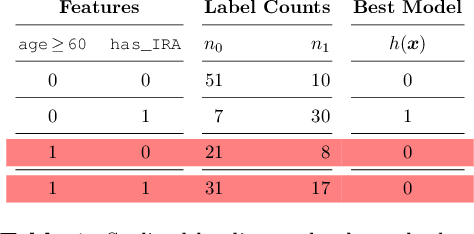
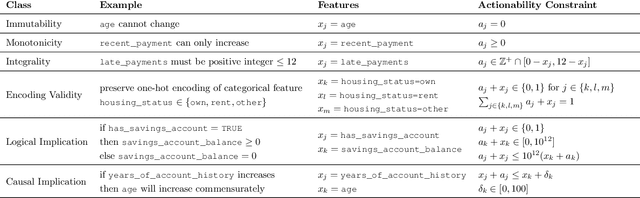

Machine learning models are often used to automate or support decisions in applications such as lending and hiring. In such settings, consumer protection rules mandate that we provide a list of "principal reasons" to consumers who receive adverse decisions. In practice, lenders and employers identify principal reasons by returning the top-scoring features from a feature attribution method. In this work, we study how such practices align with one of the underlying goals of consumer protection - recourse - i.e., educating individuals on how they can attain a desired outcome. We show that standard attribution methods can mislead individuals by highlighting reasons without recourse - i.e., by presenting consumers with features that cannot be changed to achieve recourse. We propose to address these issues by scoring features on the basis of responsiveness - i.e., the probability that an individual can attain a desired outcome by changing a specific feature. We develop efficient methods to compute responsiveness scores for any model and any dataset under complex actionability constraints. We present an extensive empirical study on the responsiveness of explanations in lending and demonstrate how responsiveness scores can be used to construct feature-highlighting explanations that lead to recourse and mitigate harm by flagging instances with fixed predictions.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Predictive Churn with the Set of Good Models
Feb 12, 2024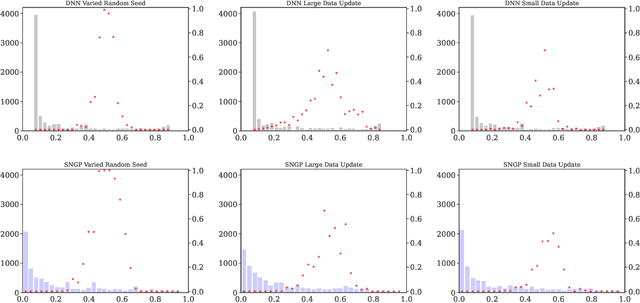

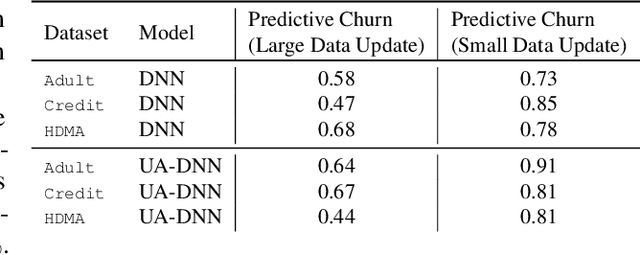
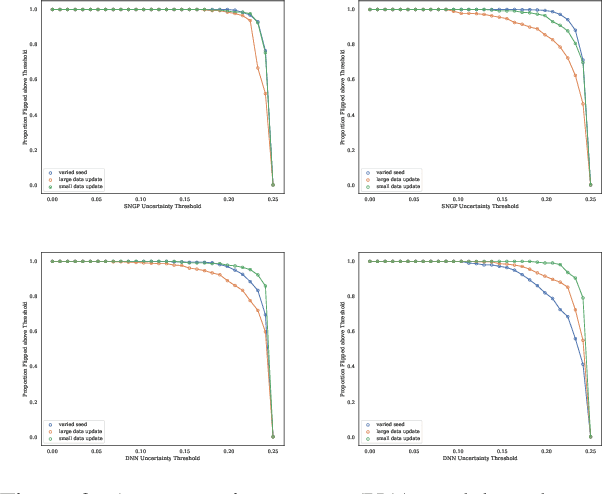
Machine learning models in modern mass-market applications are often updated over time. One of the foremost challenges faced is that, despite increasing overall performance, these updates may flip specific model predictions in unpredictable ways. In practice, researchers quantify the number of unstable predictions between models pre and post update -- i.e., predictive churn. In this paper, we study this effect through the lens of predictive multiplicity -- i.e., the prevalence of conflicting predictions over the set of near-optimal models (the Rashomon set). We show how traditional measures of predictive multiplicity can be used to examine expected churn over this set of prospective models -- i.e., the set of models that may be used to replace a baseline model in deployment. We present theoretical results on the expected churn between models within the Rashomon set from different perspectives. And we characterize expected churn over model updates via the Rashomon set, pairing our analysis with empirical results on real-world datasets -- showing how our approach can be used to better anticipate, reduce, and avoid churn in consumer-facing applications. Further, we show that our approach is useful even for models enhanced with uncertainty awareness.
Learning from Time Series under Temporal Label Noise
Feb 06, 2024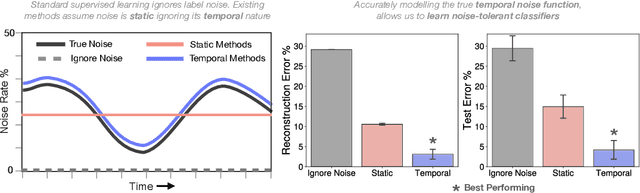

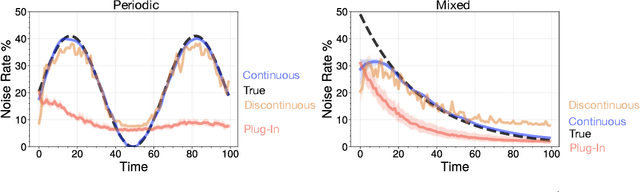
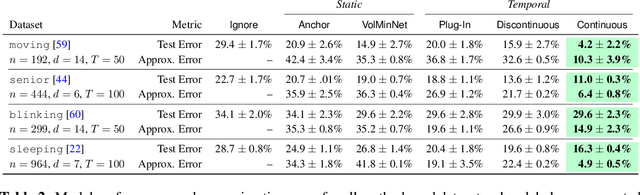
Many sequential classification tasks are affected by label noise that varies over time. Such noise can cause label quality to improve, worsen, or periodically change over time. We first propose and formalize temporal label noise, an unstudied problem for sequential classification of time series. In this setting, multiple labels are recorded in sequence while being corrupted by a time-dependent noise function. We first demonstrate the importance of modelling the temporal nature of the label noise function and how existing methods will consistently underperform. We then propose methods that can train noise-tolerant classifiers by estimating the temporal label noise function directly from data. We show that our methods lead to state-of-the-art performance in the presence of diverse temporal label noise functions using real and synthetic data.