 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification with Conceptual Safeguards
Paper and Code
Nov 07, 2024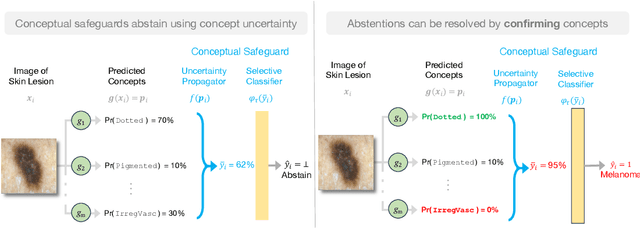
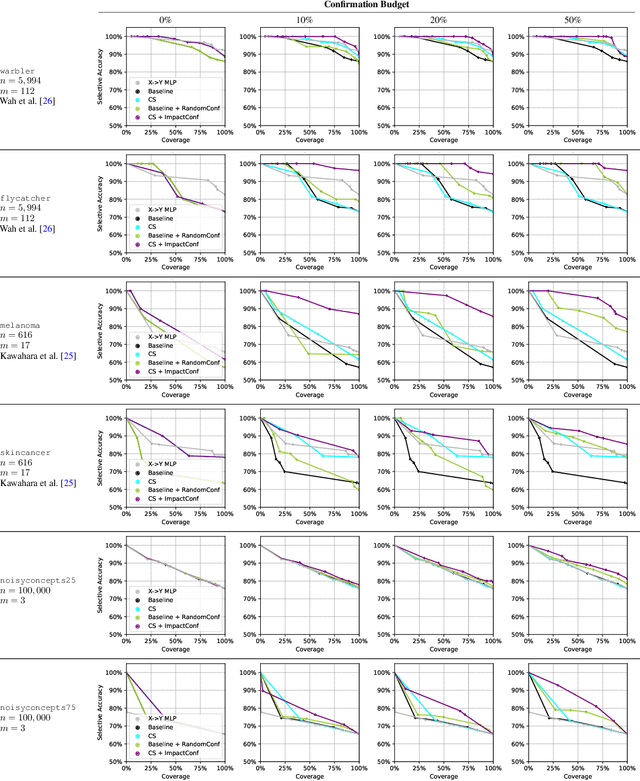
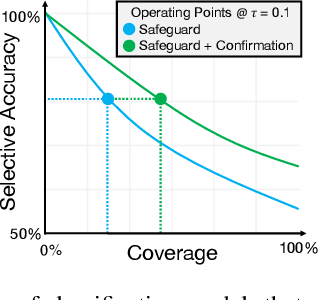
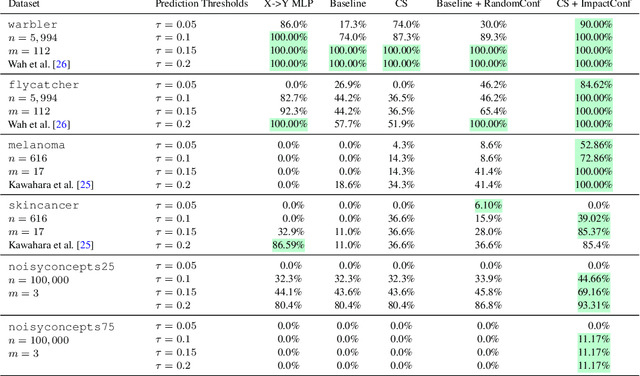
We propose a new approach to promote safety in classification tasks with established concepts. Our approach -- called a conceptual safeguard -- acts as a verification layer for models that predict a target outcome by first predicting the presence of intermediate concepts. Given this architecture, a safeguard ensures that a model meets a minimal level of accuracy by abstaining from uncertain predictions. In contrast to a standard selective classifier, a safeguard provides an avenue to improve coverage by allowing a human to confirm the presence of uncertain concepts on instances on which it abstains. We develop methods to build safeguards that maximize coverage without compromising safety, namely techniques to propagate the uncertainty in concept predictions and to flag salient concepts for human review. We benchmark our approach on a collection of real-world and synthetic datasets, showing that it can improve performance and coverage in deep learning tasks.