 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcess Description Length of Learning Generalizable Predictors
Jan 08, 2026Understanding whether fine-tuning elicits latent capabilities or teaches new ones is a fundamental question for language model evaluation and safety. We develop a formal information-theoretic framework for quantifying how much predictive structure fine-tuning extracts from the train dataset and writes into a model's parameters. Our central quantity, Excess Description Length (EDL), is defined via prequential coding and measures the gap between the bits required to encode training labels sequentially using an evolving model (trained online) and the residual encoding cost under the final trained model. We establish that EDL is non-negative in expectation, converges to surplus description length in the infinite-data limit, and provides bounds on expected generalization gain. Through a series of toy models, we clarify common confusions about information in learning: why random labels yield EDL near zero, how a single example can eliminate many bits of uncertainty about the underlying rule(s) that describe the data distribution, why structure learned on rare inputs contributes proportionally little to expected generalization, and how format learning creates early transients distinct from capability acquisition. This framework provides rigorous foundations for the empirical observation that capability elicitation and teaching exhibit qualitatively distinct scaling signatures.
Sufficient Context: A New Lens on Retrieval Augmented Generation Systems
Nov 09, 2024



Augmenting LLMs with context leads to improved performance across many applications. Despite much research on Retrieval Augmented Generation (RAG) systems, an open question is whether errors arise because LLMs fail to utilize the context from retrieval or the context itself is insufficient to answer the query. To shed light on this, we develop a new notion of sufficient context, along with a way to classify instances that have enough information to answer the query. We then use sufficient context to analyze several models and datasets. By stratifying errors based on context sufficiency, we find that proprietary LLMs (Gemini, GPT, Claude) excel at answering queries when the context is sufficient, but often output incorrect answers instead of abstaining when the context is not. On the other hand, open-source LLMs (Llama, Mistral, Gemma) hallucinate or abstain often, even with sufficient context. We further categorize cases when the context is useful, and improves accuracy, even though it does not fully answer the query and the model errs without the context. Building on our findings, we explore ways to reduce hallucinations in RAG systems, including a new selective generation method that leverages sufficient context information for guided abstention. Our method improves the fraction of correct answers among times where the model responds by 2-10% for Gemini, GPT, and Gemma.
Classification with Conceptual Safeguards
Nov 07, 2024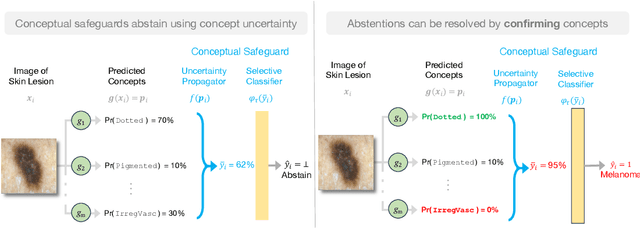
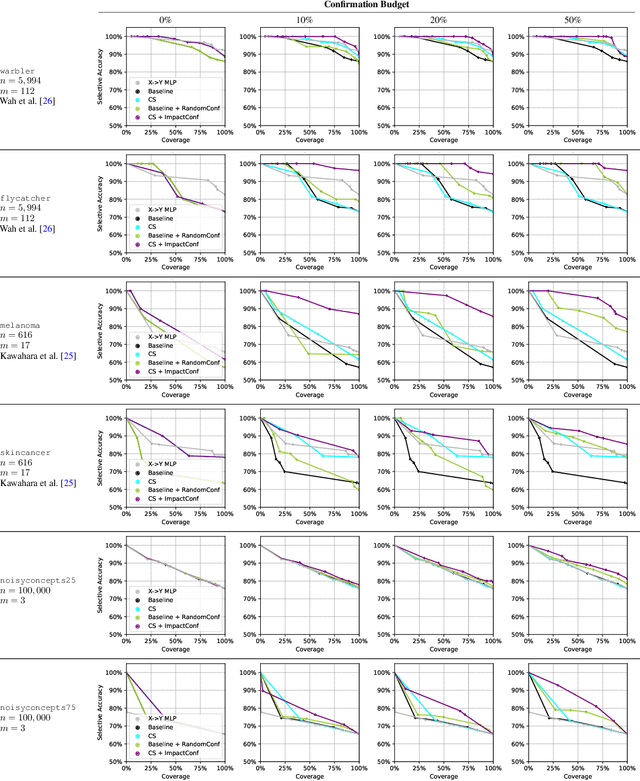
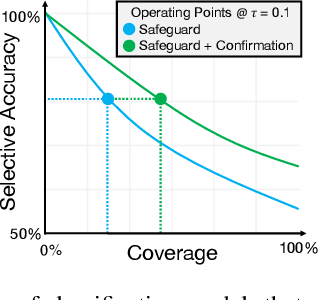
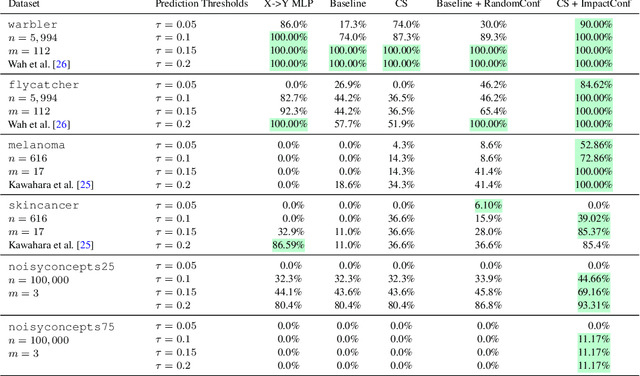
We propose a new approach to promote safety in classification tasks with established concepts. Our approach -- called a conceptual safeguard -- acts as a verification layer for models that predict a target outcome by first predicting the presence of intermediate concepts. Given this architecture, a safeguard ensures that a model meets a minimal level of accuracy by abstaining from uncertain predictions. In contrast to a standard selective classifier, a safeguard provides an avenue to improve coverage by allowing a human to confirm the presence of uncertain concepts on instances on which it abstains. We develop methods to build safeguards that maximize coverage without compromising safety, namely techniques to propagate the uncertainty in concept predictions and to flag salient concepts for human review. We benchmark our approach on a collection of real-world and synthetic datasets, showing that it can improve performance and coverage in deep learning tasks.