 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Context: A New Lens on Retrieval Augmented Generation Systems
Nov 09, 2024



Augmenting LLMs with context leads to improved performance across many applications. Despite much research on Retrieval Augmented Generation (RAG) systems, an open question is whether errors arise because LLMs fail to utilize the context from retrieval or the context itself is insufficient to answer the query. To shed light on this, we develop a new notion of sufficient context, along with a way to classify instances that have enough information to answer the query. We then use sufficient context to analyze several models and datasets. By stratifying errors based on context sufficiency, we find that proprietary LLMs (Gemini, GPT, Claude) excel at answering queries when the context is sufficient, but often output incorrect answers instead of abstaining when the context is not. On the other hand, open-source LLMs (Llama, Mistral, Gemma) hallucinate or abstain often, even with sufficient context. We further categorize cases when the context is useful, and improves accuracy, even though it does not fully answer the query and the model errs without the context. Building on our findings, we explore ways to reduce hallucinations in RAG systems, including a new selective generation method that leverages sufficient context information for guided abstention. Our method improves the fraction of correct answers among times where the model responds by 2-10% for Gemini, GPT, and Gemma.
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
Jul 11, 2024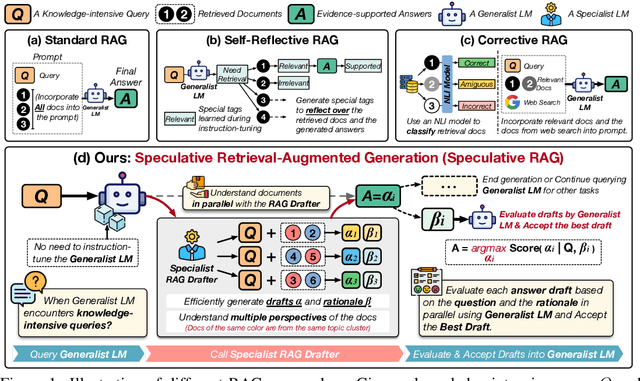
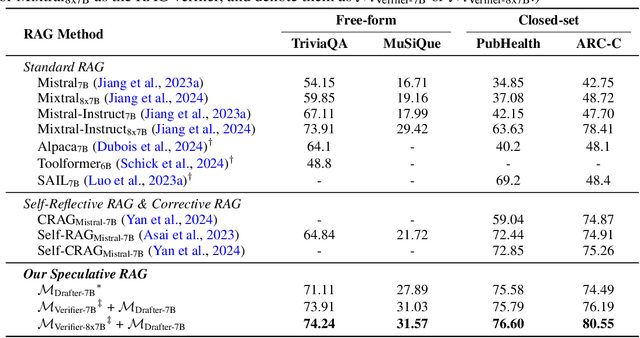
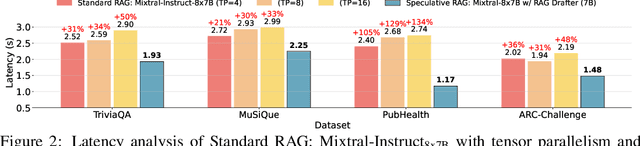
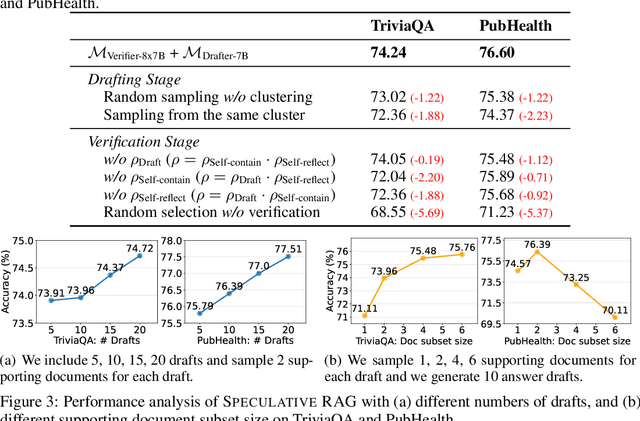
Retrieval augmented generation (RAG) combines the generative abilities of large language models (LLMs) with external knowledge sources to provide more accurate and up-to-date responses. Recent RAG advancements focus on improving retrieval outcomes through iterative LLM refinement or self-critique capabilities acquired through additional instruction tuning of LLMs. In this work, we introduce Speculative RAG - a framework that leverages a larger generalist LM to efficiently verify multiple RAG drafts produced in parallel by a smaller, distilled specialist LM. Each draft is generated from a distinct subset of retrieved documents, offering diverse perspectives on the evidence while reducing input token counts per draft. This approach enhances comprehension of each subset and mitigates potential position bias over long context. Our method accelerates RAG by delegating drafting to the smaller specialist LM, with the larger generalist LM performing a single verification pass over the drafts. Extensive experiments demonstrate that Speculative RAG achieves state-of-the-art performance with reduced latency on TriviaQA, MuSiQue, PubHealth, and ARC-Challenge benchmarks. It notably enhances accuracy by up to 12.97% while reducing latency by 51% compared to conventional RAG systems on PubHealth.
Which Pretrain Samples to Rehearse when Finetuning Pretrained Models?
Feb 12, 2024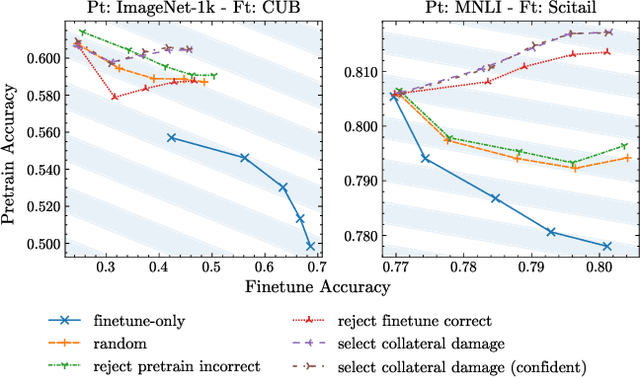
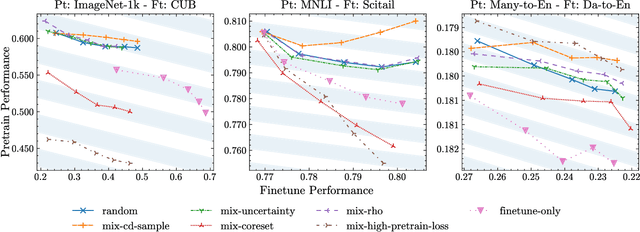
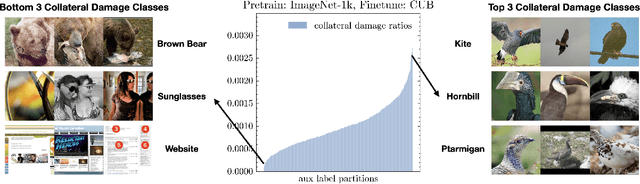
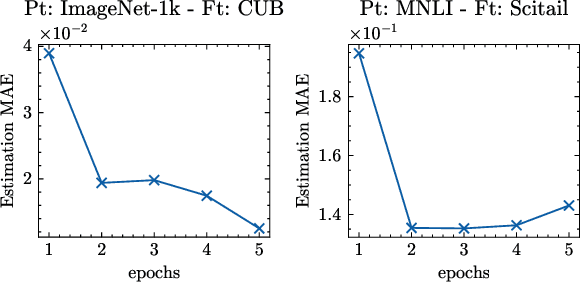
Fine-tuning pretrained foundational models on specific tasks is now the de facto approach for text and vision tasks. A known pitfall of this approach is the forgetting of pretraining knowledge that happens during finetuning. Rehearsing samples randomly from the pretrain dataset is a common approach to alleviate such forgetting. However, we find that random mixing unintentionally includes samples which are not (yet) forgotten or unlearnable by the model. We propose a novel sampling scheme, mix-cd, that identifies and prioritizes samples that actually face forgetting, which we call collateral damage. Since directly identifying collateral damage samples is computationally expensive, we propose a procedure to estimate the distribution of such samples by tracking the statistics of finetuned samples. Our approach is lightweight, easy to implement, and can be seamlessly integrated into existing models, offering an effective means to retain pretrain performance without additional computational costs.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023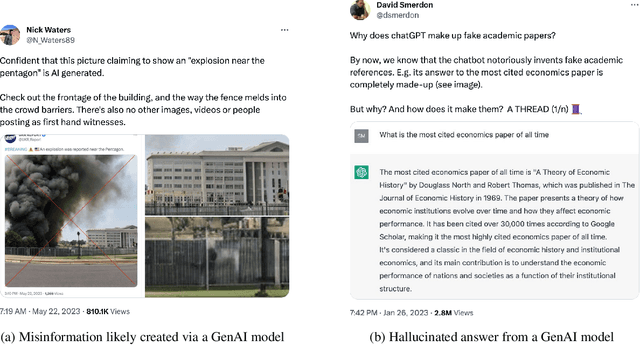
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
Interpretable Mixture of Experts for Structured Data
Jun 05, 2022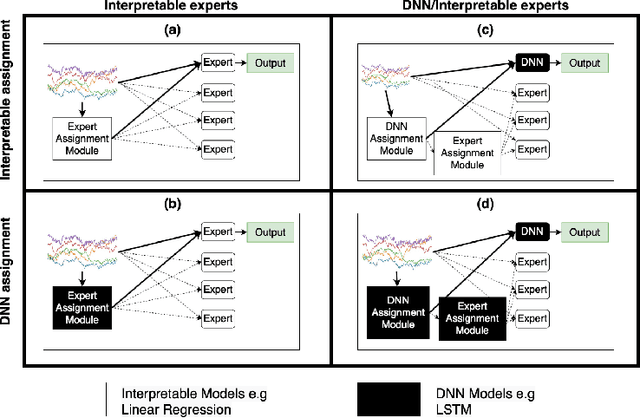
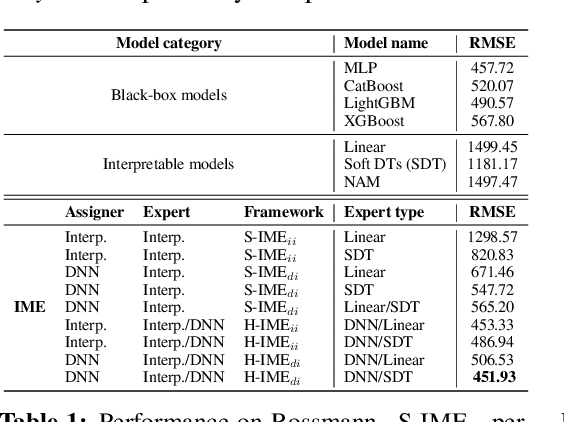
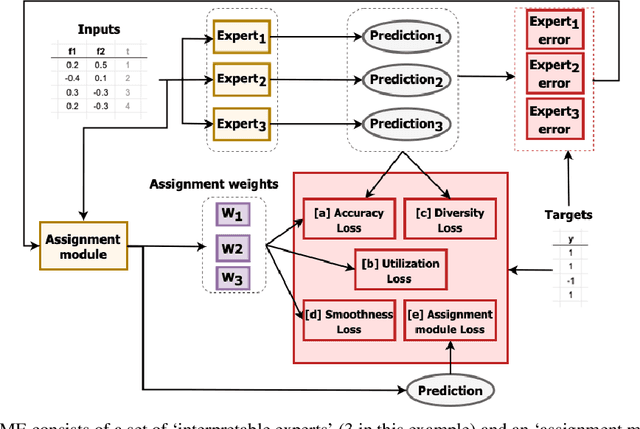
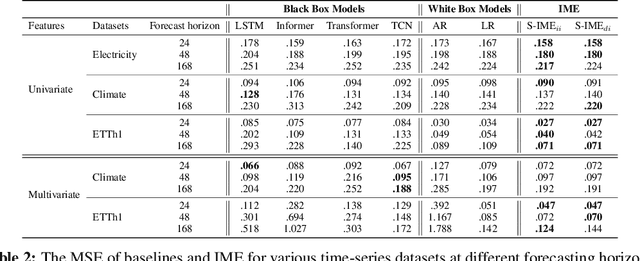
With the growth of machine learning for structured data, the need for reliable model explanations is essential, especially in high-stakes applications. We introduce a novel framework, Interpretable Mixture of Experts (IME), that provides interpretability for structured data while preserving accuracy. IME consists of an assignment module and a mixture of interpretable experts such as linear models where each sample is assigned to a single interpretable expert. This results in an inherently-interpretable architecture where the explanations produced by IME are the exact descriptions of how the prediction is computed. In addition to constituting a standalone inherently-interpretable architecture, an additional IME capability is that it can be integrated with existing Deep Neural Networks (DNNs) to offer interpretability to a subset of samples while maintaining the accuracy of the DNNs. Experiments on various structured datasets demonstrate that IME is more accurate than a single interpretable model and performs comparably to existing state-of-the-art deep learning models in terms of accuracy while providing faithful explanations.
First is Better Than Last for Training Data Influence
Feb 24, 2022
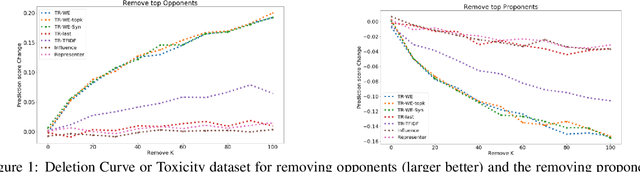

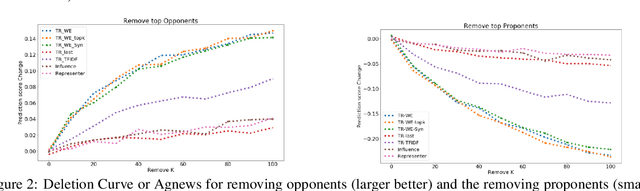
The ability to identify influential training examples enables us to debug training data and explain model behavior. Existing techniques are based on the flow of influence through the model parameters. For large models in NLP applications, it is often computationally infeasible to study this flow through all model parameters, therefore techniques usually pick the last layer of weights. Our first observation is that for classification problems, the last layer is reductive and does not encode sufficient input level information. Deleting influential examples, according to this measure, typically does not change the model's behavior much. We propose a technique called TracIn-WE that modifies a method called TracIn to operate on the word embedding layer instead of the last layer. This could potentially have the opposite concern, that the word embedding layer does not encode sufficient high level information. However, we find that gradients (unlike embeddings) do not suffer from this, possibly because they chain through higher layers. We show that TracIn-WE significantly outperforms other data influence methods applied on the last layer by 4-10 times on the case deletion evaluation on three language classification tasks. In addition, TracIn-WE can produce scores not just at the training data level, but at the word training data level, a further aid in debugging.
Local Explanations via Necessity and Sufficiency: Unifying Theory and Practice
Mar 27, 2021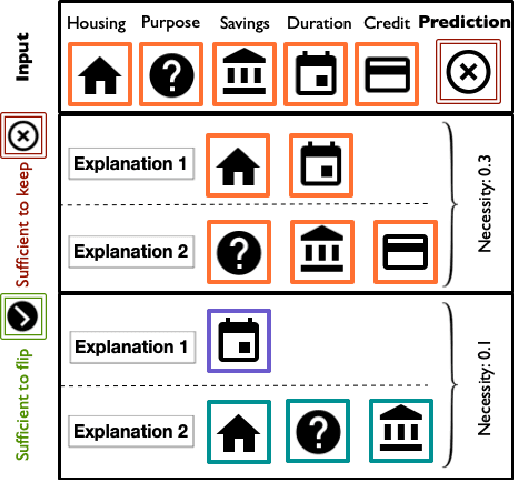

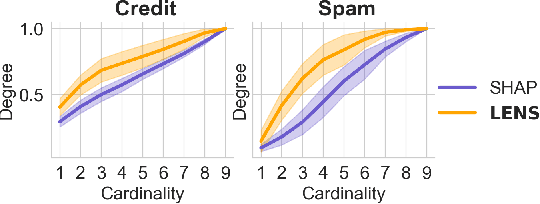

Necessity and sufficiency are the building blocks of all successful explanations. Yet despite their importance, these notions have been conceptually underdeveloped and inconsistently applied in explainable artificial intelligence (XAI), a fast-growing research area that is so far lacking in firm theoretical foundations. Building on work in logic, probability, and causality, we establish the central role of necessity and sufficiency in XAI, unifying seemingly disparate methods in a single formal framework. We provide a sound and complete algorithm for computing explanatory factors with respect to a given context, and demonstrate its flexibility and competitive performance against state of the art alternatives on various tasks.
The Explanation Game: Explaining Machine Learning Models with Cooperative Game Theory
Sep 17, 2019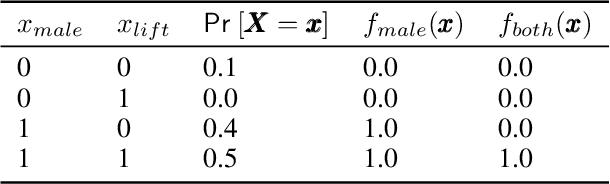
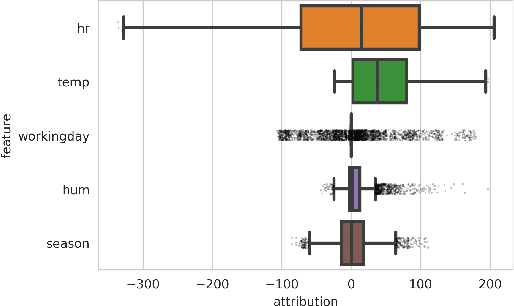

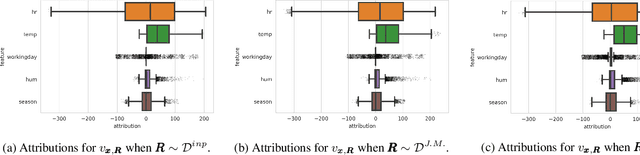
Recently, a number of techniques have been proposed to explain a machine learning (ML) model's prediction by attributing it to the corresponding input features. Popular among these are techniques that apply the Shapley value method from cooperative game theory. While existing papers focus on the axiomatic motivation of Shapley values, and efficient techniques for computing them, they do not justify the game formulations used. For instance, we find that the SHAP algorithm's formulation (Lundberg and Lee 2017) may give substantial attributions to features that play no role in a model. In this work, we study the game formulations underpinning several existing methods. Using a series of simple models, we illustrate how their subtle differences can yield large differences in attribution for the same prediction. We then present a general game formulation that unifies existing methods. After discussing the primitive of single-reference games, we decompose the Shapley values of the general game formulation into Shapley values of single-reference games. This is instructive in several ways. First, it enables confidence intervals on estimated attributions, which are not offered by previous works. Second, it enables different contrastive explanations of a prediction through comparison with different groups of reference inputs. We tie this idea to classic work on Norm Theory (Kahneman and Miller 1986) in cognitive psychology, and propose a general framework for generating explanations for ML models, called formulate, approximate, and explain (FAE). We apply this framework to explaining black-box models trained on two UCI datasets and a Lending Club dataset.
Explainable Machine Learning in Deployment
Sep 13, 2019
Explainable machine learning seeks to provide various stakeholders with insights into model behavior via feature importance scores, counterfactual explanations, and influential samples, among other techniques. Recent advances in this line of work, however, have gone without surveys of how organizations are using these techniques in practice. This study explores how organizations view and use explainability for stakeholder consumption. We find that the majority of deployments are not for end users affected by the model but for machine learning engineers, who use explainability to debug the model itself. There is a gap between explainability in practice and the goal of public transparency, since explanations primarily serve internal stakeholders rather than external ones. Our study synthesizes the limitations with current explainability techniques that hamper their use for end users. To facilitate end user interaction, we develop a framework for establishing clear goals for explainability, including a focus on normative desiderata.
Finding Invariants in Deep Neural Networks
Apr 29, 2019


We present techniques for automatically inferring invariant properties of feed-forward neural networks. Our insight is that feed forward networks should be able to learn a decision logic that is captured in the activation patterns of its neurons. We propose to extract such decision patterns that can be considered as invariants of the network with respect to a certain output behavior. We present techniques to extract input invariants as convex predicates on the input space, and layer invariants that represent features captured in the hidden layers. We apply the techniques on the networks for the MNIST and ACASXU applications. Our experiments highlight the use of invariants in a variety of applications, such as explainability, providing robustness guarantees, detecting adversaries, simplifying proofs and network distillation.