 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribution-by-design: Ensuring Inference-Time Provenance in Generative Music Systems
Oct 09, 2025



The rise of AI-generated music is diluting royalty pools and revealing structural flaws in existing remuneration frameworks, challenging the well-established artist compensation systems in the music industry. Existing compensation solutions, such as piecemeal licensing agreements, lack scalability and technical rigour, while current data attribution mechanisms provide only uncertain estimates and are rarely implemented in practice. This paper introduces a framework for a generative music infrastructure centred on direct attribution, transparent royalty distribution, and granular control for artists and rights' holders. We distinguish ontologically between the training set and the inference set, which allows us to propose two complementary forms of attribution: training-time attribution and inference-time attribution. We here favour inference-time attribution, as it enables direct, verifiable compensation whenever an artist's catalogue is used to condition a generated output. Besides, users benefit from the ability to condition generations on specific songs and receive transparent information about attribution and permitted usage. Our approach offers an ethical and practical solution to the pressing need for robust compensation mechanisms in the era of AI-generated music, ensuring that provenance and fairness are embedded at the core of generative systems.
TEDI: Trustworthy and Ethical Dataset Indicators to Analyze and Compare Dataset Documentation
May 23, 2025



Dataset transparency is a key enabler of responsible AI, but insights into multimodal dataset attributes that impact trustworthy and ethical aspects of AI applications remain scarce and are difficult to compare across datasets. To address this challenge, we introduce Trustworthy and Ethical Dataset Indicators (TEDI) that facilitate the systematic, empirical analysis of dataset documentation. TEDI encompasses 143 fine-grained indicators that characterize trustworthy and ethical attributes of multimodal datasets and their collection processes. The indicators are framed to extract verifiable information from dataset documentation. Using TEDI, we manually annotated and analyzed over 100 multimodal datasets that include human voices. We further annotated data sourcing, size, and modality details to gain insights into the factors that shape trustworthy and ethical dimensions across datasets. We find that only a select few datasets have documented attributes and practices pertaining to consent, privacy, and harmful content indicators. The extent to which these and other ethical indicators are addressed varies based on the data collection method, with documentation of datasets collected via crowdsourced and direct collection approaches being more likely to mention them. Scraping dominates scale at the cost of ethical indicators, but is not the only viable collection method. Our approach and empirical insights contribute to increasing dataset transparency along trustworthy and ethical dimensions and pave the way for automating the tedious task of extracting information from dataset documentation in future.
Efficient Bias Mitigation Without Privileged Information
Sep 26, 2024Deep neural networks trained via empirical risk minimisation often exhibit significant performance disparities across groups, particularly when group and task labels are spuriously correlated (e.g., "grassy background" and "cows"). Existing bias mitigation methods that aim to address this issue often either rely on group labels for training or validation, or require an extensive hyperparameter search. Such data and computational requirements hinder the practical deployment of these methods, especially when datasets are too large to be group-annotated, computational resources are limited, and models are trained through already complex pipelines. In this paper, we propose Targeted Augmentations for Bias Mitigation (TAB), a simple hyperparameter-free framework that leverages the entire training history of a helper model to identify spurious samples, and generate a group-balanced training set from which a robust model can be trained. We show that TAB improves worst-group performance without any group information or model selection, outperforming existing methods while maintaining overall accuracy.
Position: Measure Dataset Diversity, Don't Just Claim It
Jul 11, 2024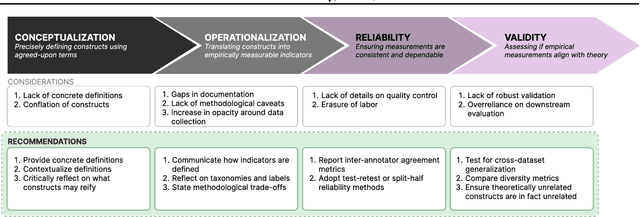
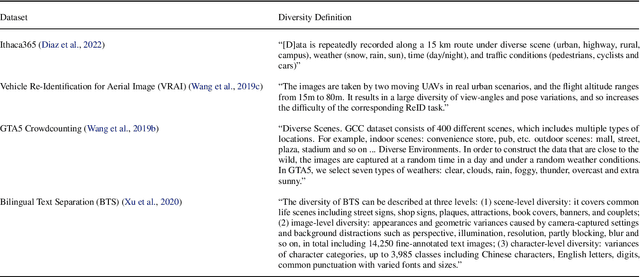
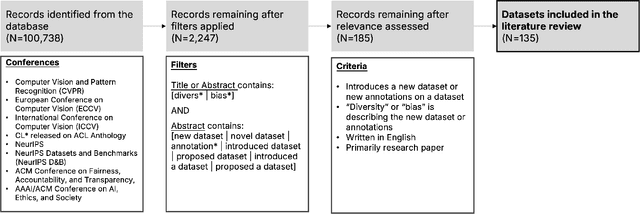
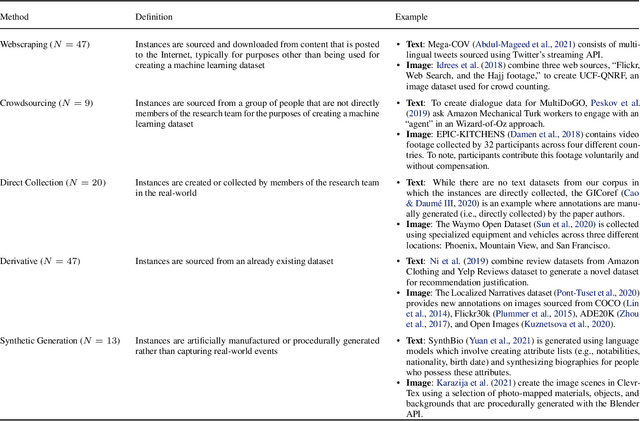
Machine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing "diversity" across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction.
Resampled Datasets Are Not Enough: Mitigating Societal Bias Beyond Single Attributes
Jul 04, 2024
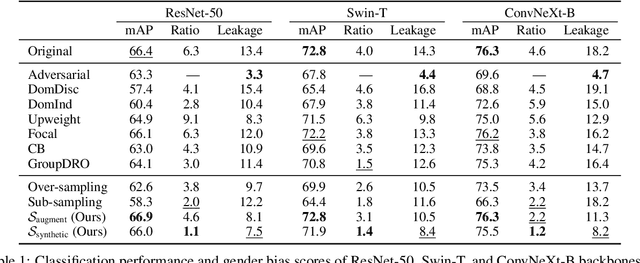
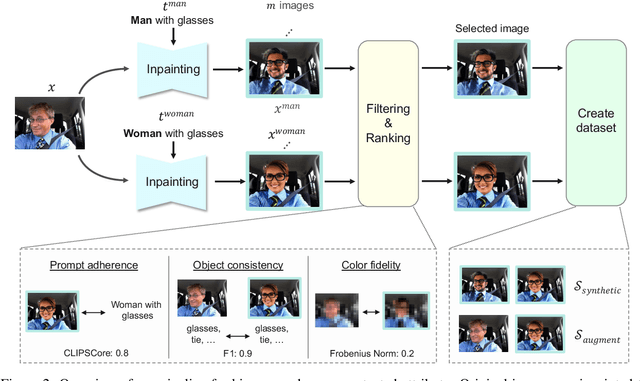
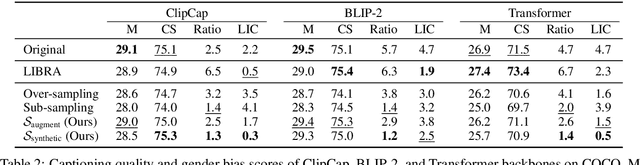
We tackle societal bias in image-text datasets by removing spurious correlations between protected groups and image attributes. Traditional methods only target labeled attributes, ignoring biases from unlabeled ones. Using text-guided inpainting models, our approach ensures protected group independence from all attributes and mitigates inpainting biases through data filtering. Evaluations on multi-label image classification and image captioning tasks show our method effectively reduces bias without compromising performance across various models.
A Taxonomy of Challenges to Curating Fair Datasets
Jun 10, 2024Despite extensive efforts to create fairer machine learning (ML) datasets, there remains a limited understanding of the practical aspects of dataset curation. Drawing from interviews with 30 ML dataset curators, we present a comprehensive taxonomy of the challenges and trade-offs encountered throughout the dataset curation lifecycle. Our findings underscore overarching issues within the broader fairness landscape that impact data curation. We conclude with recommendations aimed at fostering systemic changes to better facilitate fair dataset curation practices.
Not My Voice! A Taxonomy of Ethical and Safety Harms of Speech Generators
Jan 25, 2024



The rapid and wide-scale adoption of AI to generate human speech poses a range of significant ethical and safety risks to society that need to be addressed. For example, a growing number of speech generation incidents are associated with swatting attacks in the United States, where anonymous perpetrators create synthetic voices that call police officers to close down schools and hospitals, or to violently gain access to innocent citizens' homes. Incidents like this demonstrate that multimodal generative AI risks and harms do not exist in isolation, but arise from the interactions of multiple stakeholders and technical AI systems. In this paper we analyse speech generation incidents to study how patterns of specific harms arise. We find that specific harms can be categorised according to the exposure of affected individuals, that is to say whether they are a subject of, interact with, suffer due to, or are excluded from speech generation systems. Similarly, specific harms are also a consequence of the motives of the creators and deployers of the systems. Based on these insights we propose a conceptual framework for modelling pathways to ethical and safety harms of AI, which we use to develop a taxonomy of harms of speech generators. Our relational approach captures the complexity of risks and harms in sociotechnical AI systems, and yields an extensible taxonomy that can support appropriate policy interventions and decision making for responsible multimodal model development and release of speech generators.
Beyond Skin Tone: A Multidimensional Measure of Apparent Skin Color
Sep 10, 2023
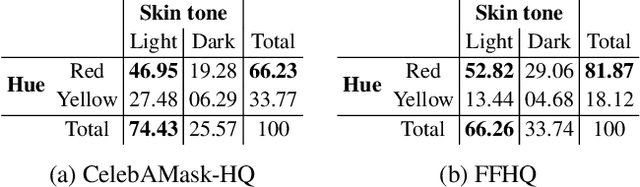

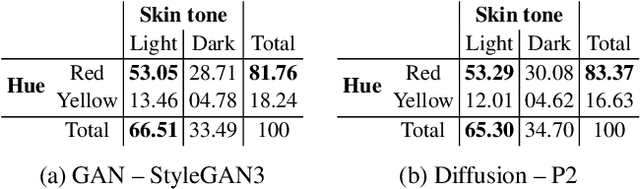
This paper strives to measure apparent skin color in computer vision, beyond a unidimensional scale on skin tone. In their seminal paper Gender Shades, Buolamwini and Gebru have shown how gender classification systems can be biased against women with darker skin tones. Subsequently, fairness researchers and practitioners have adopted the Fitzpatrick skin type classification as a common measure to assess skin color bias in computer vision systems. While effective, the Fitzpatrick scale only focuses on the skin tone ranging from light to dark. Towards a more comprehensive measure of skin color, we introduce the hue angle ranging from red to yellow. When applied to images, the hue dimension reveals additional biases related to skin color in both computer vision datasets and models. We then recommend multidimensional skin color scales, relying on both skin tone and hue, for fairness assessments.
Flickr Africa: Examining Geo-Diversity in Large-Scale, Human-Centric Visual Data
Aug 16, 2023Biases in large-scale image datasets are known to influence the performance of computer vision models as a function of geographic context. To investigate the limitations of standard Internet data collection methods in low- and middle-income countries, we analyze human-centric image geo-diversity on a massive scale using geotagged Flickr images associated with each nation in Africa. We report the quantity and content of available data with comparisons to population-matched nations in Europe as well as the distribution of data according to fine-grained intra-national wealth estimates. Temporal analyses are performed at two-year intervals to expose emerging data trends. Furthermore, we present findings for an ``othering'' phenomenon as evidenced by a substantial number of images from Africa being taken by non-local photographers. The results of our study suggest that further work is required to capture image data representative of African people and their environments and, ultimately, to improve the applicability of computer vision models in a global context.
Considerations for Ethical Speech Recognition Datasets
May 03, 2023Speech AI Technologies are largely trained on publicly available datasets or by the massive web-crawling of speech. In both cases, data acquisition focuses on minimizing collection effort, without necessarily taking the data subjects' protection or user needs into consideration. This results to models that are not robust when used on users who deviate from the dominant demographics in the training set, discriminating individuals having different dialects, accents, speaking styles, and disfluencies. In this talk, we use automatic speech recognition as a case study and examine the properties that ethical speech datasets should possess towards responsible AI applications. We showcase diversity issues, inclusion practices, and necessary considerations that can improve trained models, while facilitating model explainability and protecting users and data subjects. We argue for the legal & privacy protection of data subjects, targeted data sampling corresponding to user demographics & needs, appropriate meta data that ensure explainability & accountability in cases of model failure, and the sociotechnical \& situated model design. We hope this talk can inspire researchers \& practitioners to design and use more human-centric datasets in speech technologies and other domains, in ways that empower and respect users, while improving machine learning models' robustness and utility.