 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYes, But Not Always. Generative AI Needs Nuanced Opt-in
Apr 10, 2026This paper argues that a one-size-fits-all approach to specifying consent for the use of creative works in generative AI is insufficient. Real-world ownership and rights holder structures, the imitation of artistic styles and likeness, and the limitless contexts of use of AI outputs make the status quo of binary consent with opt-in by default untenable. To move beyond the current impasse, we consider levers of control in generative AI workflows at training, inference, and dissemination. Based on these insights, we position inference-time opt-in as an overlooked opportunity for nuanced consent verification. We conceptualize nuanced consent conditions for opt-in and propose an agent-based inference-time opt-in architecture to verify if user intent requests meet conditional consent granted by rights holders. In a case study for music, we demonstrate that nuanced opt-in at inference can account for established rights and re-establish a balance of power between rights holders and AI developers.
Ethical Considerations for Collecting Human-Centric Image Datasets
Feb 07, 2023
Human-centric image datasets are critical to the development of computer vision technologies. However, recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction, or modification, of several prominent datasets. Recent works have tried to reverse this trend, for example, by proposing analytical frameworks for ethically evaluating datasets, the standardization of dataset documentation and curation practices, privacy preservation methodologies, as well as tools for surfacing and mitigating representational biases. Little attention, however, has been paid to the realities of operationalizing ethical data collection. To fill this gap, we present a set of key ethical considerations and practical recommendations for collecting more ethically-minded human-centric image data. Our research directly addresses issues of privacy and bias by contributing to the research community best practices for ethical data collection, covering purpose, privacy and consent, as well as diversity. We motivate each consideration by drawing on lessons from current practices, dataset withdrawals and audits, and analytical ethical frameworks. Our research is intended to augment recent scholarship, representing an important step toward more responsible data curation practices.
Enhancing Fine-Grained Classification for Low Resolution Images
May 01, 2021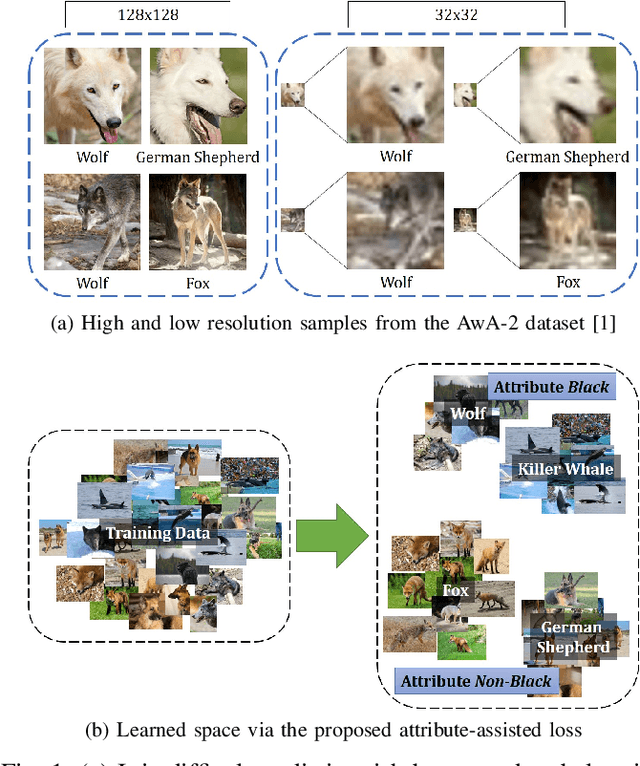
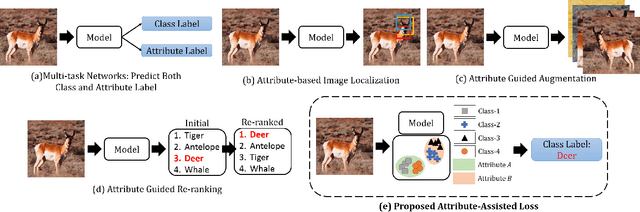

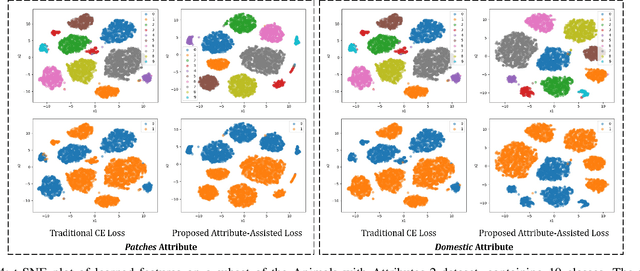
Low resolution fine-grained classification has widespread applicability for applications where data is captured at a distance such as surveillance and mobile photography. While fine-grained classification with high resolution images has received significant attention, limited attention has been given to low resolution images. These images suffer from the inherent challenge of limited information content and the absence of fine details useful for sub-category classification. This results in low inter-class variations across samples of visually similar classes. In order to address these challenges, this research proposes a novel attribute-assisted loss, which utilizes ancillary information to learn discriminative features for classification. The proposed loss function enables a model to learn class-specific discriminative features, while incorporating attribute-level separability. Evaluation is performed on multiple datasets with different models, for four resolutions varying from 32x32 to 224x224. Different experiments demonstrate the efficacy of the proposed attributeassisted loss for low resolution fine-grained classification.
On the Robustness of Face Recognition Algorithms Against Attacks and Bias
Feb 07, 2020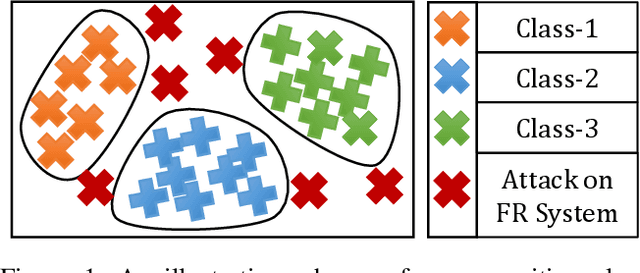



Face recognition algorithms have demonstrated very high recognition performance, suggesting suitability for real world applications. Despite the enhanced accuracies, robustness of these algorithms against attacks and bias has been challenged. This paper summarizes different ways in which the robustness of a face recognition algorithm is challenged, which can severely affect its intended working. Different types of attacks such as physical presentation attacks, disguise/makeup, digital adversarial attacks, and morphing/tampering using GANs have been discussed. We also present a discussion on the effect of bias on face recognition models and showcase that factors such as age and gender variations affect the performance of modern algorithms. The paper also presents the potential reasons for these challenges and some of the future research directions for increasing the robustness of face recognition models.
Dual Directed Capsule Network for Very Low Resolution Image Recognition
Aug 27, 2019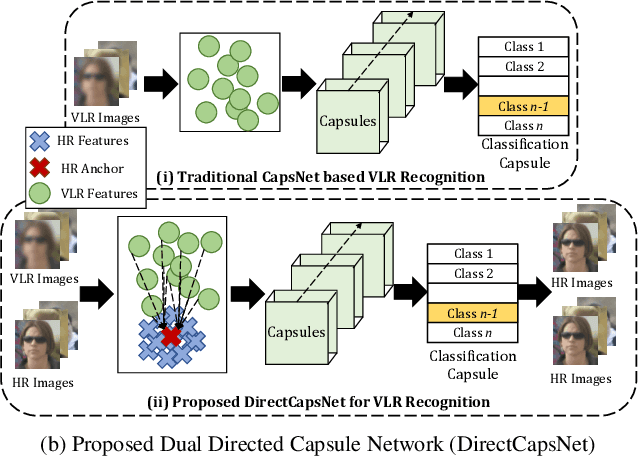
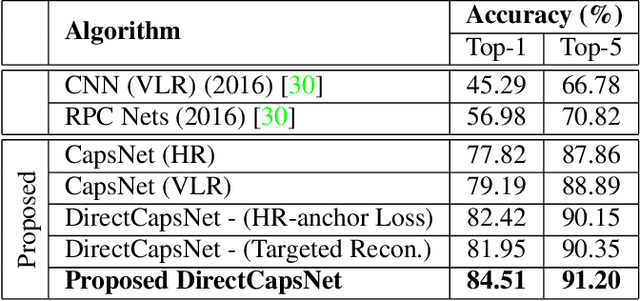

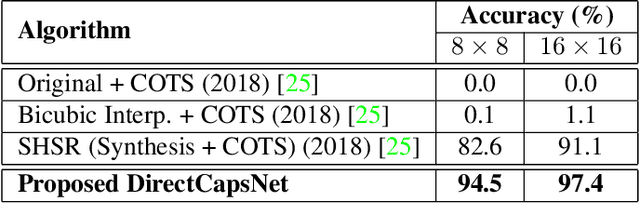
Very low resolution (VLR) image recognition corresponds to classifying images with resolution 16x16 or less. Though it has widespread applicability when objects are captured at a very large stand-off distance (e.g. surveillance scenario) or from wide angle mobile cameras, it has received limited attention. This research presents a novel Dual Directed Capsule Network model, termed as DirectCapsNet, for addressing VLR digit and face recognition. The proposed architecture utilizes a combination of capsule and convolutional layers for learning an effective VLR recognition model. The architecture also incorporates two novel loss functions: (i) the proposed HR-anchor loss and (ii) the proposed targeted reconstruction loss, in order to overcome the challenges of limited information content in VLR images. The proposed losses use high resolution images as auxiliary data during training to "direct" discriminative feature learning. Multiple experiments for VLR digit classification and VLR face recognition are performed along with comparisons with state-of-the-art algorithms. The proposed DirectCapsNet consistently showcases state-of-the-art results; for example, on the UCCS face database, it shows over 95\% face recognition accuracy when 16x16 images are matched with 80x80 images.
Deep Learning for Face Recognition: Pride or Prejudiced?
Apr 02, 2019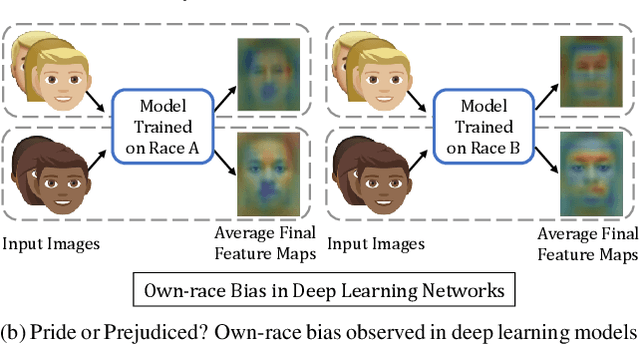
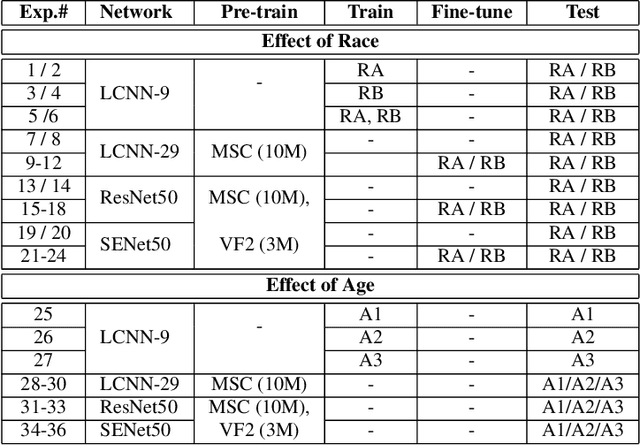


Do very high accuracies of deep networks suggest pride of effective AI or are deep networks prejudiced? Do they suffer from in-group biases (own-race-bias and own-age-bias), and mimic the human behavior? Is in-group specific information being encoded sub-consciously by the deep networks? This research attempts to answer these questions and presents an in-depth analysis of `bias' in deep learning based face recognition systems. This is the first work which decodes if and where bias is encoded for face recognition. Taking cues from cognitive studies, we inspect if deep networks are also affected by social in- and out-group effect. Networks are analyzed for own-race and own-age bias, both of which have been well established in human beings. The sub-conscious behavior of face recognition models is examined to understand if they encode race or age specific features for face recognition. Analysis is performed based on 36 experiments conducted on multiple datasets. Four deep learning networks either trained from scratch or pre-trained on over 10M images are used. Variations across class activation maps and feature visualizations provide novel insights into the functioning of deep learning systems, suggesting behavior similar to humans. It is our belief that a better understanding of state-of-the-art deep learning networks would enable researchers to address the given challenge of bias in AI, and develop fairer systems.
Supervised COSMOS Autoencoder: Learning Beyond the Euclidean Loss!
Oct 15, 2018

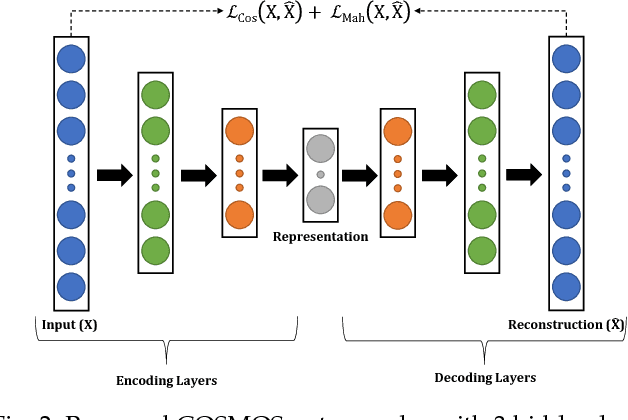
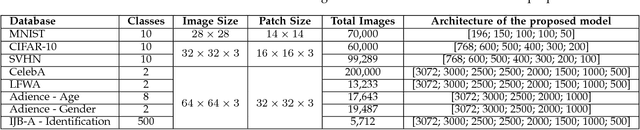
Autoencoders are unsupervised deep learning models used for learning representations. In literature, autoencoders have shown to perform well on a variety of tasks spread across multiple domains, thereby establishing widespread applicability. Typically, an autoencoder is trained to generate a model that minimizes the reconstruction error between the input and the reconstructed output, computed in terms of the Euclidean distance. While this can be useful for applications related to unsupervised reconstruction, it may not be optimal for classification. In this paper, we propose a novel Supervised COSMOS Autoencoder which utilizes a multi-objective loss function to learn representations that simultaneously encode the (i) "similarity" between the input and reconstructed vectors in terms of their direction, (ii) "distribution" of pixel values of the reconstruction with respect to the input sample, while also incorporating (iii) "discriminability" in the feature learning pipeline. The proposed autoencoder model incorporates a Cosine similarity and Mahalanobis distance based loss function, along with supervision via Mutual Information based loss. Detailed analysis of each component of the proposed model motivates its applicability for feature learning in different classification tasks. The efficacy of Supervised COSMOS autoencoder is demonstrated via extensive experimental evaluations on different image datasets. The proposed model outperforms existing algorithms on MNIST, CIFAR-10, and SVHN databases. It also yields state-of-the-art results on CelebA, LFWA, Adience, and IJB-A databases for attribute prediction and face recognition, respectively.
Learning A Shared Transform Model for Skull to Digital Face Image Matching
Aug 14, 2018
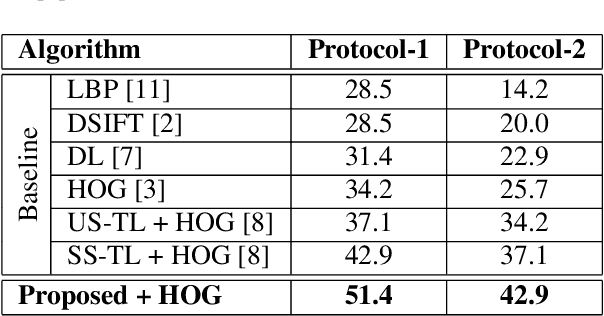
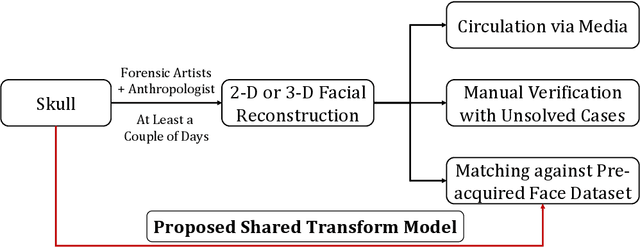
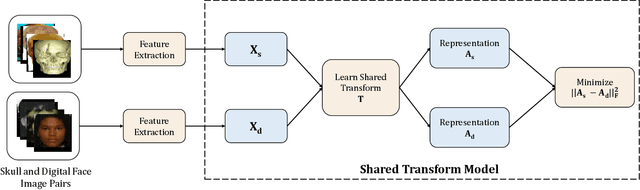
Human skull identification is an arduous task, traditionally requiring the expertise of forensic artists and anthropologists. This paper is an effort to automate the process of matching skull images to digital face images, thereby establishing an identity of the skeletal remains. In order to achieve this, a novel Shared Transform Model is proposed for learning discriminative representations. The model learns robust features while reducing the intra-class variations between skulls and digital face images. Such a model can assist law enforcement agencies by speeding up the process of skull identification, and reducing the manual load. Experimental evaluation performed on two pre-defined protocols of the publicly available IdentifyMe dataset demonstrates the efficacy of the proposed model.
Class Representative Autoencoder for Low Resolution Multi-Spectral Gender Classification
May 21, 2018

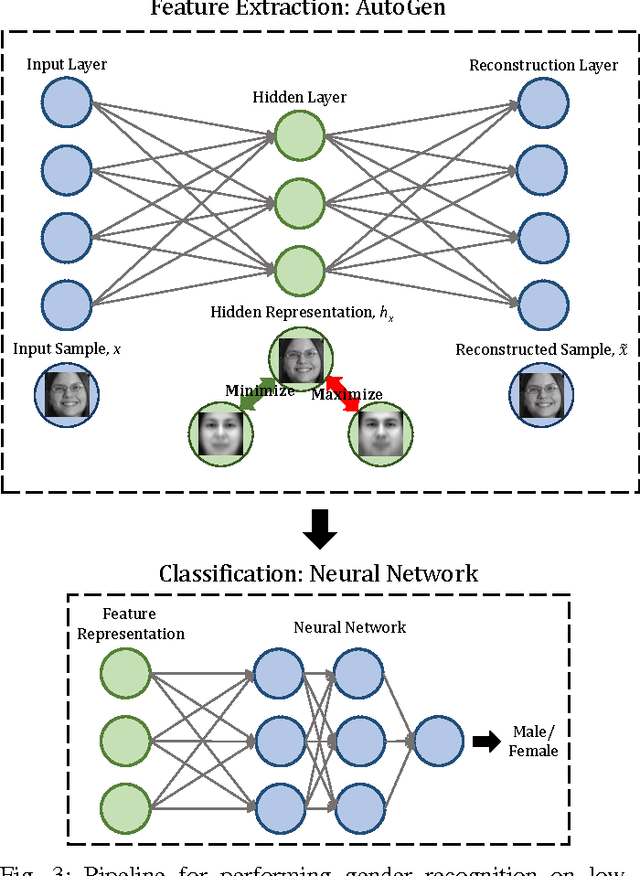

Gender is one of the most common attributes used to describe an individual. It is used in multiple domains such as human computer interaction, marketing, security, and demographic reports. Research has been performed to automate the task of gender recognition in constrained environment using face images, however, limited attention has been given to gender classification in unconstrained scenarios. This work attempts to address the challenging problem of gender classification in multi-spectral low resolution face images. We propose a robust Class Representative Autoencoder model, termed as AutoGen for the same. The proposed model aims to minimize the intra-class variations while maximizing the inter-class variations for the learned feature representations. Results on visible as well as near infrared spectrum data for different resolutions and multiple databases depict the efficacy of the proposed model. Comparative results with existing approaches and two commercial off-the-shelf systems further motivate the use of class representative features for classification.
Are you eligible? Predicting adulthood from face images via class specific mean autoencoder
Mar 20, 2018



Predicting if a person is an adult or a minor has several applications such as inspecting underage driving, preventing purchase of alcohol and tobacco by minors, and granting restricted access. The challenging nature of this problem arises due to the complex and unique physiological changes that are observed with age progression. This paper presents a novel deep learning based formulation, termed as Class Specific Mean Autoencoder, to learn the intra-class similarity and extract class-specific features. We propose that the feature of a particular class if brought similar/closer to the mean feature of that class can help in learning class-specific representations. The proposed formulation is applied for the task of adulthood classification which predicts whether the given face image is of an adult or not. Experiments are performed on two large databases and the results show that the proposed algorithm yields higher classification accuracy compared to existing algorithms and a Commercial-Off-The-Shelf system.