 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Bias Mitigation Without Privileged Information
Sep 26, 2024Deep neural networks trained via empirical risk minimisation often exhibit significant performance disparities across groups, particularly when group and task labels are spuriously correlated (e.g., "grassy background" and "cows"). Existing bias mitigation methods that aim to address this issue often either rely on group labels for training or validation, or require an extensive hyperparameter search. Such data and computational requirements hinder the practical deployment of these methods, especially when datasets are too large to be group-annotated, computational resources are limited, and models are trained through already complex pipelines. In this paper, we propose Targeted Augmentations for Bias Mitigation (TAB), a simple hyperparameter-free framework that leverages the entire training history of a helper model to identify spurious samples, and generate a group-balanced training set from which a robust model can be trained. We show that TAB improves worst-group performance without any group information or model selection, outperforming existing methods while maintaining overall accuracy.
Position: Measure Dataset Diversity, Don't Just Claim It
Jul 11, 2024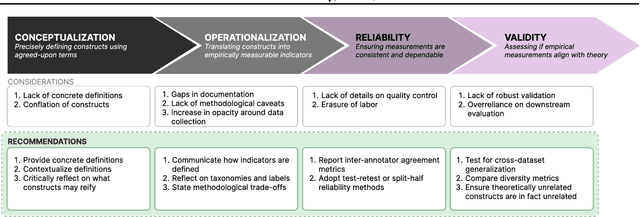
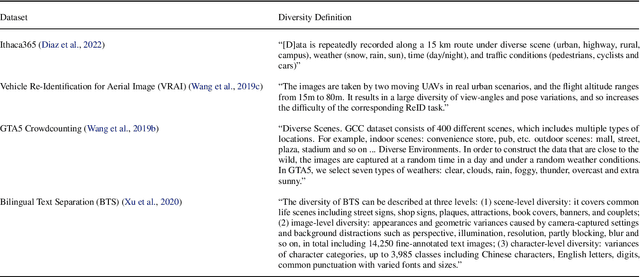
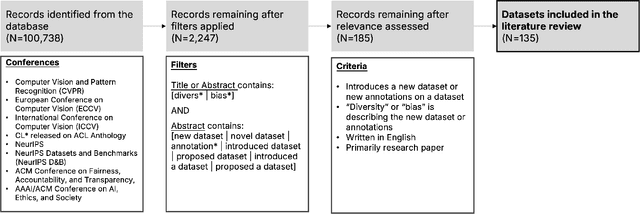
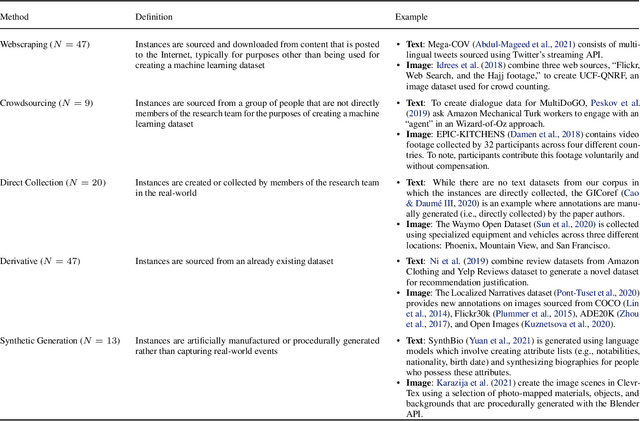
Machine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing "diversity" across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction.
A Taxonomy of Challenges to Curating Fair Datasets
Jun 10, 2024Despite extensive efforts to create fairer machine learning (ML) datasets, there remains a limited understanding of the practical aspects of dataset curation. Drawing from interviews with 30 ML dataset curators, we present a comprehensive taxonomy of the challenges and trade-offs encountered throughout the dataset curation lifecycle. Our findings underscore overarching issues within the broader fairness landscape that impact data curation. We conclude with recommendations aimed at fostering systemic changes to better facilitate fair dataset curation practices.
A View From Somewhere: Human-Centric Face Representations
Mar 30, 2023



Few datasets contain self-identified sensitive attributes, inferring attributes risks introducing additional biases, and collecting attributes can carry legal risks. Besides, categorical labels can fail to reflect the continuous nature of human phenotypic diversity, making it difficult to compare the similarity between same-labeled faces. To address these issues, we present A View From Somewhere (AVFS) -- a dataset of 638,180 human judgments of face similarity. We demonstrate the utility of AVFS for learning a continuous, low-dimensional embedding space aligned with human perception. Our embedding space, induced under a novel conditional framework, not only enables the accurate prediction of face similarity, but also provides a human-interpretable decomposition of the dimensions used in the human-decision making process, and the importance distinct annotators place on each dimension. We additionally show the practicality of the dimensions for collecting continuous attributes, performing classification, and comparing dataset attribute disparities.
Ethical Considerations for Collecting Human-Centric Image Datasets
Feb 07, 2023
Human-centric image datasets are critical to the development of computer vision technologies. However, recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction, or modification, of several prominent datasets. Recent works have tried to reverse this trend, for example, by proposing analytical frameworks for ethically evaluating datasets, the standardization of dataset documentation and curation practices, privacy preservation methodologies, as well as tools for surfacing and mitigating representational biases. Little attention, however, has been paid to the realities of operationalizing ethical data collection. To fill this gap, we present a set of key ethical considerations and practical recommendations for collecting more ethically-minded human-centric image data. Our research directly addresses issues of privacy and bias by contributing to the research community best practices for ethical data collection, covering purpose, privacy and consent, as well as diversity. We motivate each consideration by drawing on lessons from current practices, dataset withdrawals and audits, and analytical ethical frameworks. Our research is intended to augment recent scholarship, representing an important step toward more responsible data curation practices.
I call BS: Fraud Detection in Crowdfunding Campaigns
Jun 30, 2020
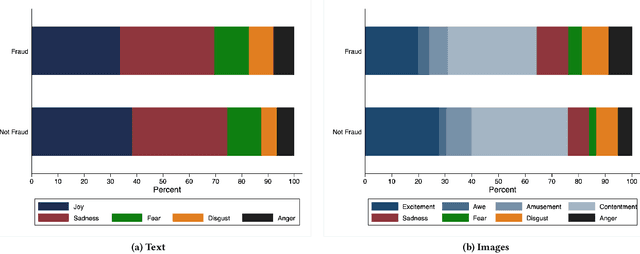

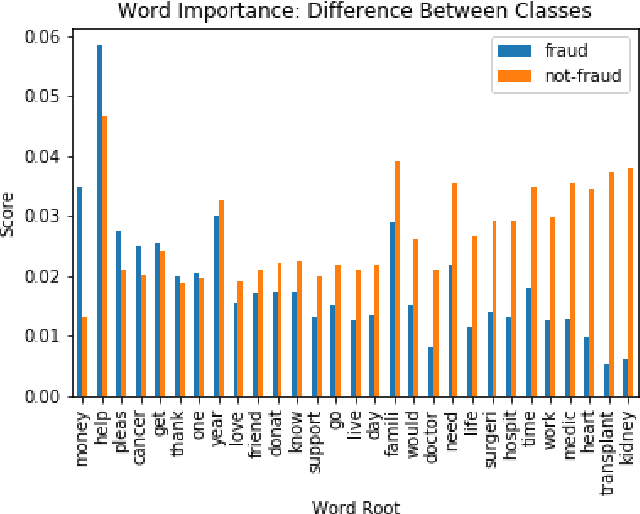
Donations to charity-based crowdfunding environments have been on the rise in the last few years. Unsurprisingly, deception and fraud in such platforms have also increased, but have not been thoroughly studied to understand what characteristics can expose such behavior and allow its automatic detection and blocking. Indeed, crowdfunding platforms are the only ones typically performing oversight for the campaigns launched in each service. However, they are not properly incentivized to combat fraud among users and the campaigns they launch: on the one hand, a platform's revenue is directly proportional to the number of transactions performed (since the platform charges a fixed amount per donation); on the other hand, if a platform is transparent with respect to how much fraud it has, it may discourage potential donors from participating. In this paper, we take the first step in studying fraud in crowdfunding campaigns. We analyze data collected from different crowdfunding platforms, and annotate 700 campaigns as fraud or not. We compute various textual and image-based features and study their distributions and how they associate with campaign fraud. Using these attributes, we build machine learning classifiers, and show that it is possible to automatically classify such fraudulent behavior with up to 90.14% accuracy and 96.01% AUC, only using features available from the campaign's description at the moment of publication (i.e., with no user or money activity), making our method applicable for real-time operation on a user browser.
Camera Model Anonymisation with Augmented cGANs
Feb 18, 2020



The model of camera that was used to capture a particular photographic image (model attribution) can be inferred from model-specific artefacts present within the image. Typically these artefacts are found in high-frequency pixel patterns, rather than image content. Model anonymisation is the process of transforming these artefacts such that the apparent capture model is changed. Improved methods for attribution and anonymisation are important for improving digital forensics, and understanding its limits. Through conditional adversarial training, we present an approach for learning these transformations. Significantly, we augment the objective with the losses from pre-trained auxiliary model attribution classifiers that constrain the generator to not only synthesise discriminative high-frequency artefacts, but also salient image-based artefacts lost during image content suppression. Quantitative comparisons against a recent representative approach demonstrate the efficacy of our framework in a non-interactive black-box setting.
Multiple-Identity Image Attacks Against Face-based Identity Verification
Jun 20, 2019

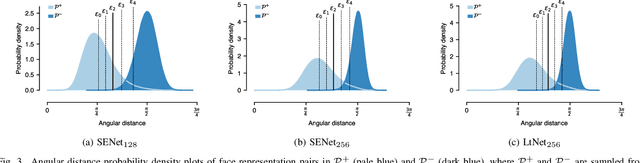

Facial verification systems are vulnerable to poisoning attacks that make use of multiple-identity images (MIIs)---face images stored in a database that resemble multiple persons, such that novel images of any of the constituent persons are verified as matching the identity of the MII. Research on this mode of attack has focused on defence by detection, with no explanation as to why the vulnerability exists. New quantitative results are presented that support an explanation in terms of the geometry of the representations spaces used by the verification systems. In the spherical geometry of those spaces, the angular distance distributions of matching and non-matching pairs of face representations are only modestly separated, approximately centred at 90 and 40-60 degrees, respectively. This is sufficient for open-set verification on normal data but provides an opportunity for MII attacks. Our analysis considers ideal MII algorithms, demonstrating that, if realisable, they would deliver faces roughly 45 degrees from their constituent faces, thus classed as matching them. We study the performance of three methods for MII generation---gallery search, image space morphing, and representation space inversion---and show that the latter two realise the ideal well enough to produce effective attacks, while the former could succeed but only with an implausibly large gallery to search. Gallery search and inversion MIIs depend on having access to a facial comparator, for optimisation, but our results show that these attacks can still be effective when attacking disparate comparators, thus securing a deployed comparator is an insufficient defence.
Built-in Vulnerabilities to Imperceptible Adversarial Perturbations
Jun 19, 2018



Designing models that are robust to small adversarial perturbations of their inputs has proven remarkably difficult. In this work we show that the reverse problem---making models more vulnerable---is surprisingly easy. After presenting some proofs of concept on MNIST, we introduce a generic tilting attack that injects vulnerabilities into the linear layers of pre-trained networks without affecting their performance on natural data. We illustrate this attack on a multilayer perceptron trained on SVHN and use it to design a stand-alone adversarial module which we call a steganogram decoder. Finally, we show on CIFAR-10 that a state-of-the-art network can be trained to misclassify images in the presence of imperceptible backdoor signals. These different results suggest that adversarial perturbations are not always informative of the true features used by a model.