 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Skin Tone: A Multidimensional Measure of Apparent Skin Color
Sep 10, 2023
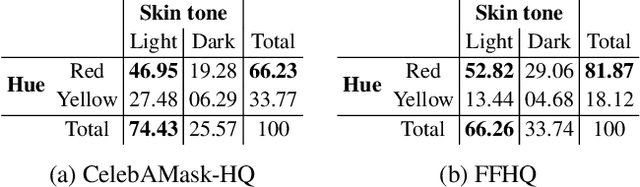

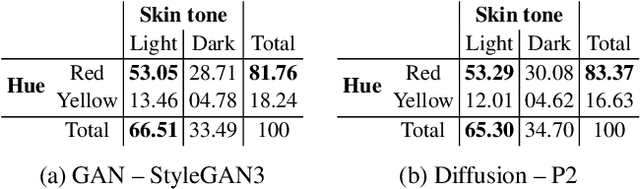
This paper strives to measure apparent skin color in computer vision, beyond a unidimensional scale on skin tone. In their seminal paper Gender Shades, Buolamwini and Gebru have shown how gender classification systems can be biased against women with darker skin tones. Subsequently, fairness researchers and practitioners have adopted the Fitzpatrick skin type classification as a common measure to assess skin color bias in computer vision systems. While effective, the Fitzpatrick scale only focuses on the skin tone ranging from light to dark. Towards a more comprehensive measure of skin color, we introduce the hue angle ranging from red to yellow. When applied to images, the hue dimension reveals additional biases related to skin color in both computer vision datasets and models. We then recommend multidimensional skin color scales, relying on both skin tone and hue, for fairness assessments.
A View From Somewhere: Human-Centric Face Representations
Mar 30, 2023



Few datasets contain self-identified sensitive attributes, inferring attributes risks introducing additional biases, and collecting attributes can carry legal risks. Besides, categorical labels can fail to reflect the continuous nature of human phenotypic diversity, making it difficult to compare the similarity between same-labeled faces. To address these issues, we present A View From Somewhere (AVFS) -- a dataset of 638,180 human judgments of face similarity. We demonstrate the utility of AVFS for learning a continuous, low-dimensional embedding space aligned with human perception. Our embedding space, induced under a novel conditional framework, not only enables the accurate prediction of face similarity, but also provides a human-interpretable decomposition of the dimensions used in the human-decision making process, and the importance distinct annotators place on each dimension. We additionally show the practicality of the dimensions for collecting continuous attributes, performing classification, and comparing dataset attribute disparities.
Gender Biases and Where to Find Them: Exploring Gender Bias in Pre-Trained Transformer-based Language Models Using Movement Pruning
Jul 06, 2022



Language model debiasing has emerged as an important field of study in the NLP community. Numerous debiasing techniques were proposed, but bias ablation remains an unaddressed issue. We demonstrate a novel framework for inspecting bias in pre-trained transformer-based language models via movement pruning. Given a model and a debiasing objective, our framework finds a subset of the model containing less bias than the original model. We implement our framework by pruning the model while fine-tuning it on the debiasing objective. Optimized are only the pruning scores - parameters coupled with the model's weights that act as gates. We experiment with pruning attention heads, an important building block of transformers: we prune square blocks, as well as establish a new way of pruning the entire heads. Lastly, we demonstrate the usage of our framework using gender bias, and based on our findings, we propose an improvement to an existing debiasing method. Additionally, we re-discover a bias-performance trade-off: the better the model performs, the more bias it contains.