 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time augmentation improves efficiency in conformal prediction
May 28, 2025A conformal classifier produces a set of predicted classes and provides a probabilistic guarantee that the set includes the true class. Unfortunately, it is often the case that conformal classifiers produce uninformatively large sets. In this work, we show that test-time augmentation (TTA)--a technique that introduces inductive biases during inference--reduces the size of the sets produced by conformal classifiers. Our approach is flexible, computationally efficient, and effective. It can be combined with any conformal score, requires no model retraining, and reduces prediction set sizes by 10%-14% on average. We conduct an evaluation of the approach spanning three datasets, three models, two established conformal scoring methods, different guarantee strengths, and several distribution shifts to show when and why test-time augmentation is a useful addition to the conformal pipeline.
Efficient Bias Mitigation Without Privileged Information
Sep 26, 2024Deep neural networks trained via empirical risk minimisation often exhibit significant performance disparities across groups, particularly when group and task labels are spuriously correlated (e.g., "grassy background" and "cows"). Existing bias mitigation methods that aim to address this issue often either rely on group labels for training or validation, or require an extensive hyperparameter search. Such data and computational requirements hinder the practical deployment of these methods, especially when datasets are too large to be group-annotated, computational resources are limited, and models are trained through already complex pipelines. In this paper, we propose Targeted Augmentations for Bias Mitigation (TAB), a simple hyperparameter-free framework that leverages the entire training history of a helper model to identify spurious samples, and generate a group-balanced training set from which a robust model can be trained. We show that TAB improves worst-group performance without any group information or model selection, outperforming existing methods while maintaining overall accuracy.
Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors
Nov 20, 2022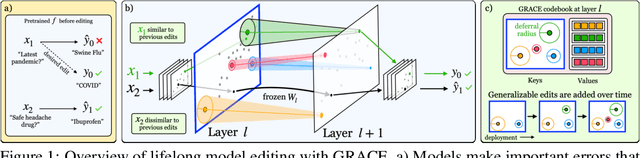

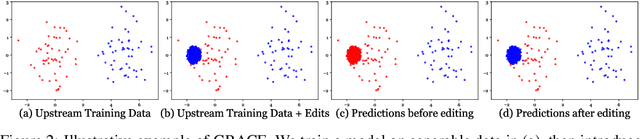
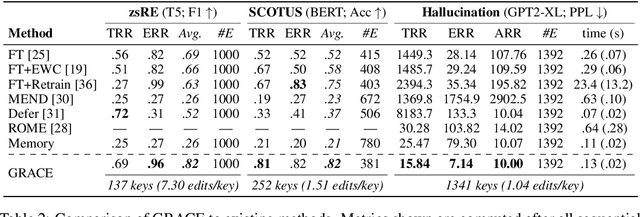
Large pre-trained models decay over long-term deployment as input distributions shift, user requirements change, or crucial knowledge gaps are discovered. Recently, model editors have been proposed to modify a model's behavior by adjusting its weights during deployment. However, when editing the same model multiple times, these approaches quickly decay a model's performance on upstream data and forget how to fix previous errors. We propose and study a novel Lifelong Model Editing setting, where streaming errors are identified for a deployed model and we update the model to correct its predictions without influencing unrelated inputs without access to training edits, exogenous datasets, or any upstream data for the edited model. To approach this problem, we introduce General Retrieval Adaptors for Continual Editing, or GRACE, which learns to cache a chosen layer's activations in an adaptive codebook as edits stream in, leaving original model weights frozen. GRACE can thus edit models thousands of times in a row using only streaming errors, while minimally influencing unrelated inputs. Experimentally, we show that GRACE improves over recent model editors and generalizes to unseen inputs. Our code is available at https://www.github.com/thartvigsen/grace.
Semantic uncertainty intervals for disentangled latent spaces
Jul 20, 2022

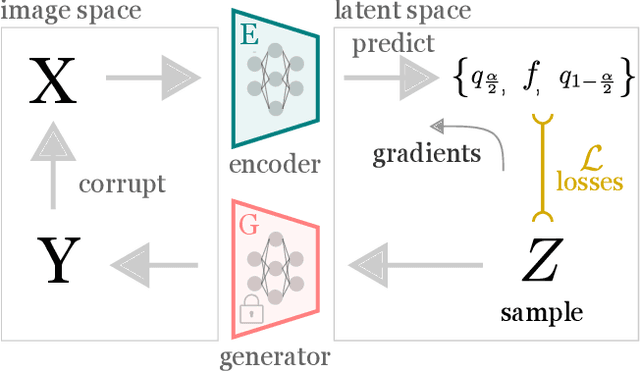
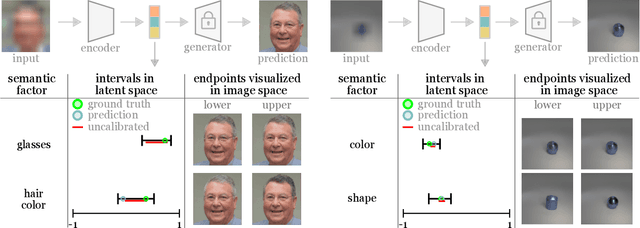
Meaningful uncertainty quantification in computer vision requires reasoning about semantic information -- say, the hair color of the person in a photo or the location of a car on the street. To this end, recent breakthroughs in generative modeling allow us to represent semantic information in disentangled latent spaces, but providing uncertainties on the semantic latent variables has remained challenging. In this work, we provide principled uncertainty intervals that are guaranteed to contain the true semantic factors for any underlying generative model. The method does the following: (1) it uses quantile regression to output a heuristic uncertainty interval for each element in the latent space (2) calibrates these uncertainties such that they contain the true value of the latent for a new, unseen input. The endpoints of these calibrated intervals can then be propagated through the generator to produce interpretable uncertainty visualizations for each semantic factor. This technique reliably communicates semantically meaningful, principled, and instance-adaptive uncertainty in inverse problems like image super-resolution and image completion.
Visual Prompting: Modifying Pixel Space to Adapt Pre-trained Models
Mar 31, 2022

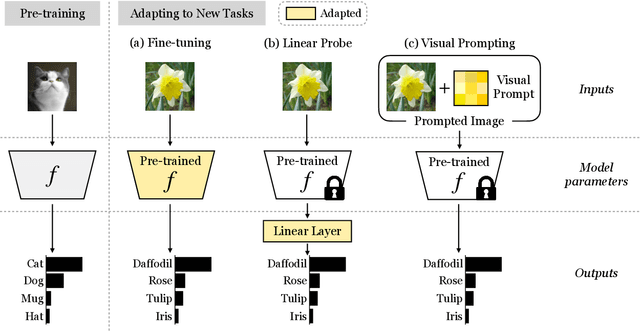
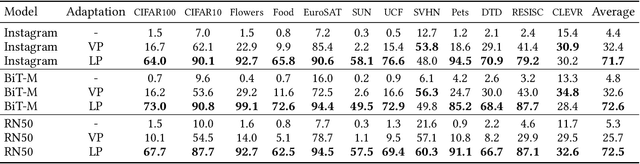
Prompting has recently become a popular paradigm for adapting language models to downstream tasks. Rather than fine-tuning model parameters or adding task-specific heads, this approach steers a model to perform a new task simply by adding a text prompt to the model's inputs. In this paper, we explore the question: can we create prompts with pixels instead? In other words, can pre-trained vision models be adapted to a new task solely by adding pixels to their inputs? We introduce visual prompting, which learns a task-specific image perturbation such that a frozen pre-trained model prompted with this perturbation performs a new task. We discover that changing only a few pixels is enough to adapt models to new tasks and datasets, and performs on par with linear probing, the current de facto approach to lightweight adaptation. The surprising effectiveness of visual prompting provides a new perspective on how to adapt pre-trained models in vision, and opens up the possibility of adapting models solely through their inputs, which, unlike model parameters or outputs, are typically under an end-user's control. Code is available at http://hjbahng.github.io/visual_prompting .
Learning From Noisy Labels By Regularized Estimation Of Annotator Confusion
Feb 10, 2019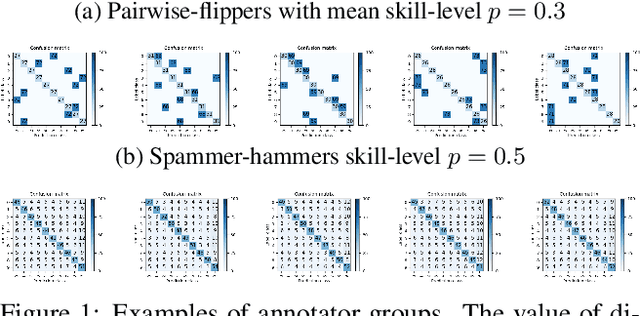
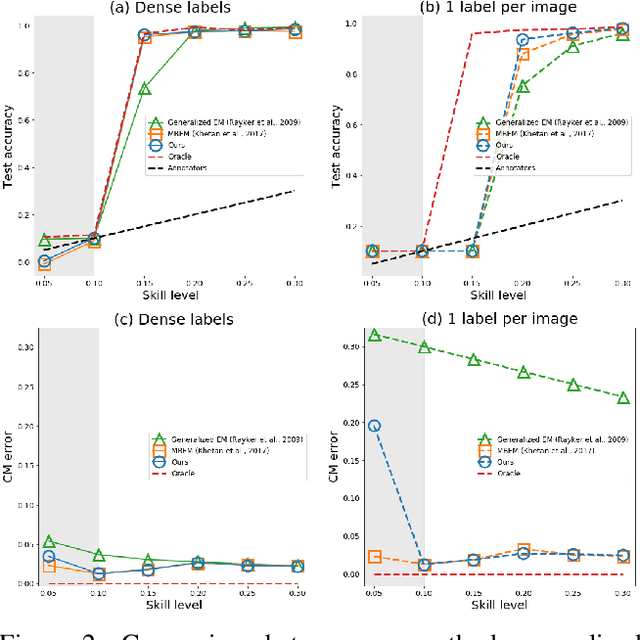
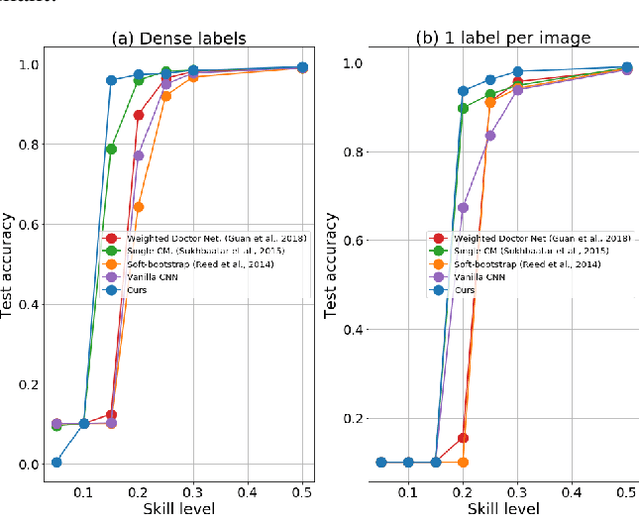
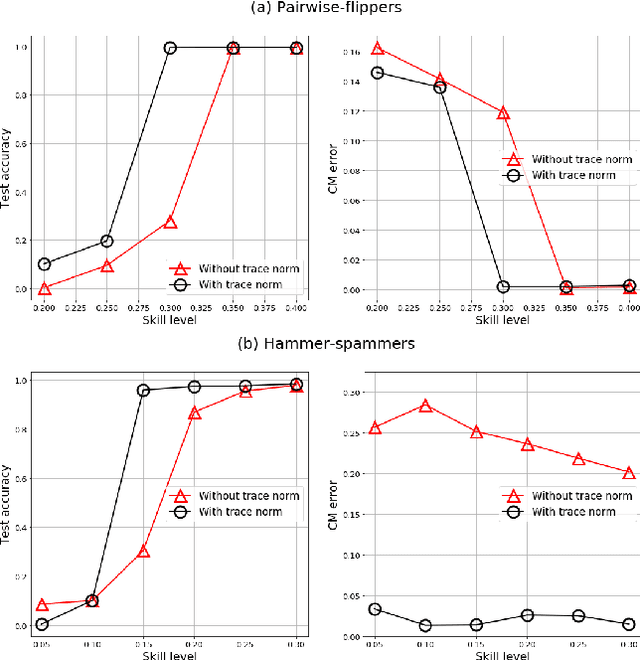
The predictive performance of supervised learning algorithms depends on the quality of labels. In a typical label collection process, multiple annotators provide subjective noisy estimates of the "truth" under the influence of their varying skill-levels and biases. Blindly treating these noisy labels as the ground truth limits the accuracy of learning algorithms in the presence of strong disagreement. This problem is critical for applications in domains such as medical imaging where both the annotation cost and inter-observer variability are high. In this work, we present a method for simultaneously learning the individual annotator model and the underlying true label distribution, using only noisy observations. Each annotator is modeled by a confusion matrix that is jointly estimated along with the classifier predictions. We propose to add a regularization term to the loss function that encourages convergence to the true annotator confusion matrix. We provide a theoretical argument as to how the regularization is essential to our approach both for the case of single annotator and multiple annotators. Despite the simplicity of the idea, experiments on image classification tasks with both simulated and real labels show that our method either outperforms or performs on par with the state-of-the-art methods and is capable of estimating the skills of annotators even with a single label available per image.
Regularizing deep networks using efficient layerwise adversarial training
May 29, 2018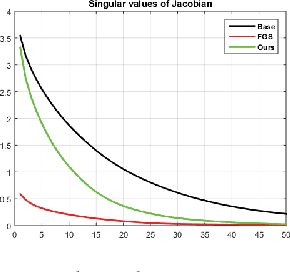
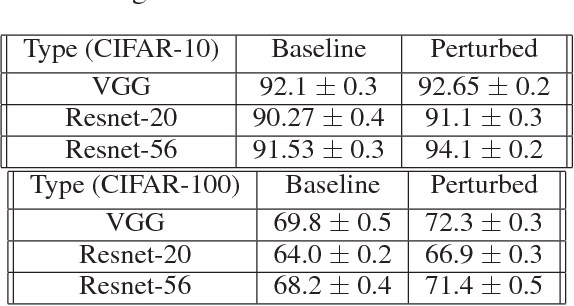
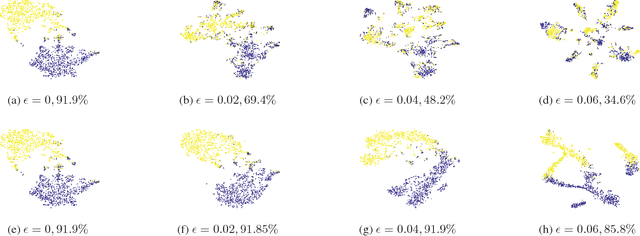
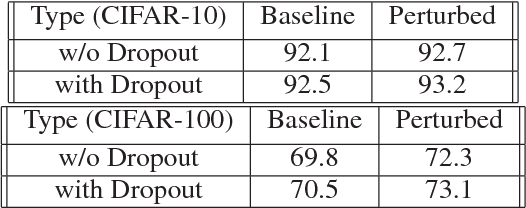
Adversarial training has been shown to regularize deep neural networks in addition to increasing their robustness to adversarial examples. However, its impact on very deep state of the art networks has not been fully investigated. In this paper, we present an efficient approach to perform adversarial training by perturbing intermediate layer activations and study the use of such perturbations as a regularizer during training. We use these perturbations to train very deep models such as ResNets and show improvement in performance both on adversarial and original test data. Our experiments highlight the benefits of perturbing intermediate layer activations compared to perturbing only the inputs. The results on CIFAR-10 and CIFAR-100 datasets show the merits of the proposed adversarial training approach. Additional results on WideResNets show that our approach provides significant improvement in classification accuracy for a given base model, outperforming dropout and other base models of larger size.
Generate To Adapt: Aligning Domains using Generative Adversarial Networks
Apr 12, 2018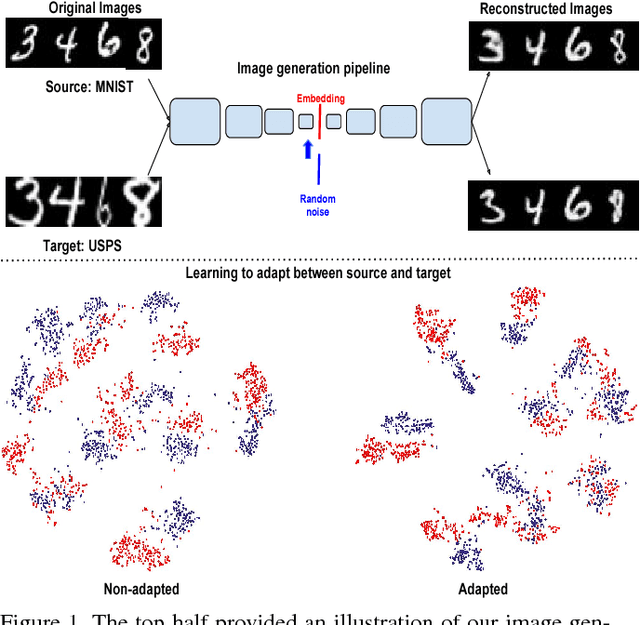

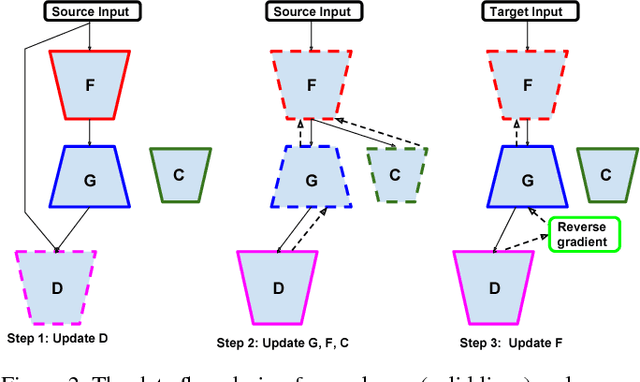
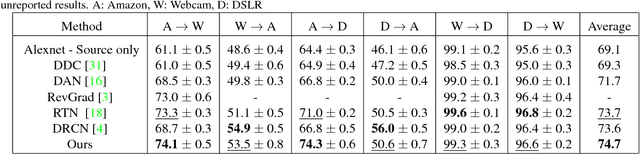
Domain Adaptation is an actively researched problem in Computer Vision. In this work, we propose an approach that leverages unsupervised data to bring the source and target distributions closer in a learned joint feature space. We accomplish this by inducing a symbiotic relationship between the learned embedding and a generative adversarial network. This is in contrast to methods which use the adversarial framework for realistic data generation and retraining deep models with such data. We demonstrate the strength and generality of our approach by performing experiments on three different tasks with varying levels of difficulty: (1) Digit classification (MNIST, SVHN and USPS datasets) (2) Object recognition using OFFICE dataset and (3) Domain adaptation from synthetic to real data. Our method achieves state-of-the art performance in most experimental settings and by far the only GAN-based method that has been shown to work well across different datasets such as OFFICE and DIGITS.
Crystal Loss and Quality Pooling for Unconstrained Face Verification and Recognition
Apr 03, 2018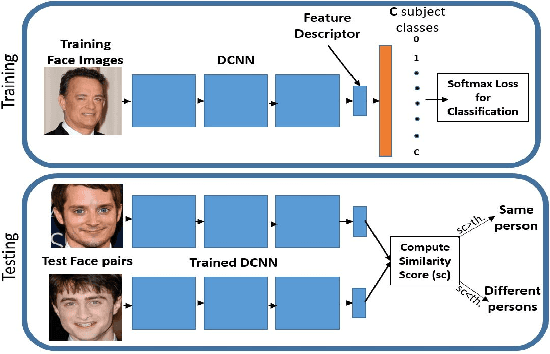

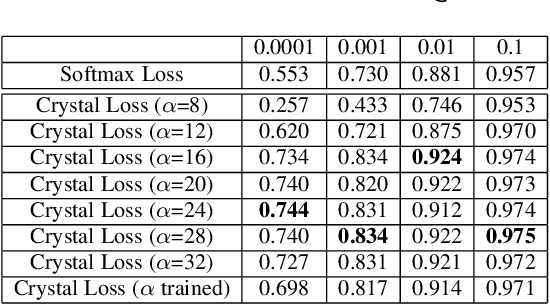
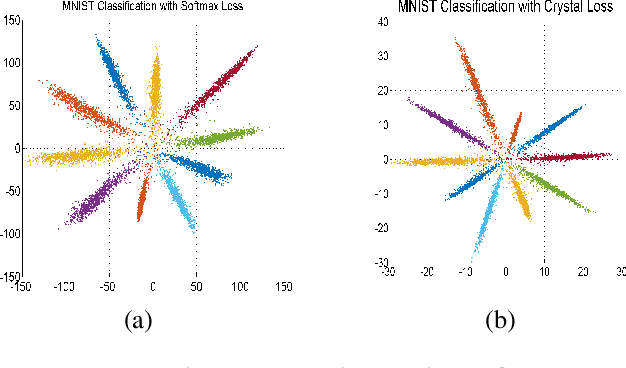
In recent years, the performance of face verification and recognition systems based on deep convolutional neural networks (DCNNs) has significantly improved. A typical pipeline for face verification includes training a deep network for subject classification with softmax loss, using the penultimate layer output as the feature descriptor, and generating a cosine similarity score given a pair of face images or videos. The softmax loss function does not optimize the features to have higher similarity score for positive pairs and lower similarity score for negative pairs, which leads to a performance gap. In this paper, we propose a new loss function, called Crystal Loss, that restricts the features to lie on a hypersphere of a fixed radius. The loss can be easily implemented using existing deep learning frameworks. We show that integrating this simple step in the training pipeline significantly improves the performance of face verification and recognition systems. We achieve state-of-the-art performance for face verification and recognition on challenging LFW, IJB-A, IJB-B and IJB-C datasets over a large range of false alarm rates (10-1 to 10-7).
Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation
Apr 01, 2018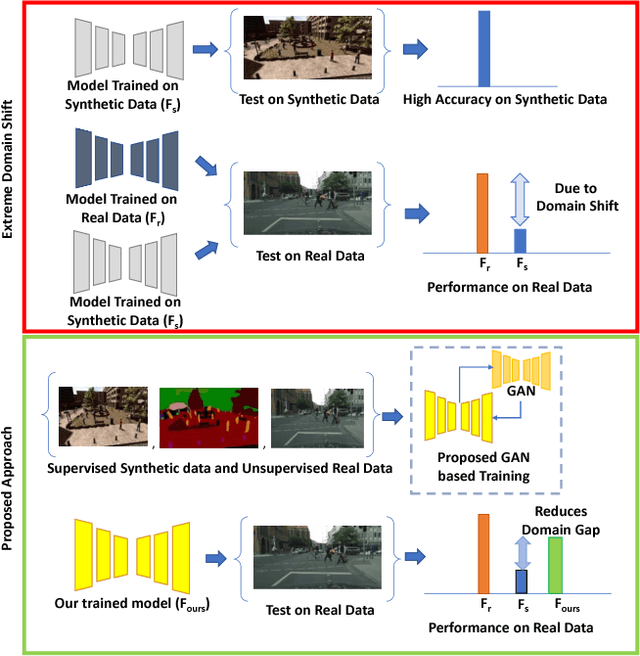

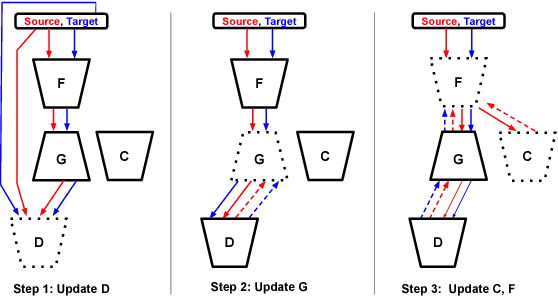
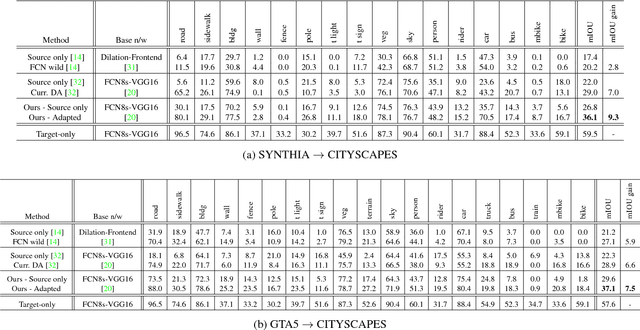
Visual Domain Adaptation is a problem of immense importance in computer vision. Previous approaches showcase the inability of even deep neural networks to learn informative representations across domain shift. This problem is more severe for tasks where acquiring hand labeled data is extremely hard and tedious. In this work, we focus on adapting the representations learned by segmentation networks across synthetic and real domains. Contrary to previous approaches that use a simple adversarial objective or superpixel information to aid the process, we propose an approach based on Generative Adversarial Networks (GANs) that brings the embeddings closer in the learned feature space. To showcase the generality and scalability of our approach, we show that we can achieve state of the art results on two challenging scenarios of synthetic to real domain adaptation. Additional exploratory experiments show that our approach: (1) generalizes to unseen domains and (2) results in improved alignment of source and target distributions.