 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-estimation under Two-Phase Multiwave Sampling with Applications to Prediction-Powered Inference
Feb 18, 2026In two-phase multiwave sampling, inexpensive measurements are collected on a large sample and expensive, more informative measurements are adaptively obtained on subsets of units across multiple waves. Adaptively collecting the expensive measurements can increase efficiency but complicates statistical inference. We give valid estimators and confidence intervals for M-estimation under adaptive two-phase multiwave sampling. We focus on the case where proxies for the expensive variables -- such as predictions from pretrained machine learning models -- are available for all units and propose a Multiwave Predict-Then-Debias estimator that combines proxy information with the expensive, higher-quality measurements to improve efficiency while removing bias. We establish asymptotic linearity and normality and propose asymptotically valid confidence intervals. We also develop an approximately greedy sampling strategy that improves efficiency relative to uniform sampling. Data-based simulation studies support the theoretical results and demonstrate efficiency gains.
Rethinking Diffusion Models with Symmetries through Canonicalization with Applications to Molecular Graph Generation
Feb 16, 2026Many generative tasks in chemistry and science involve distributions invariant to group symmetries (e.g., permutation and rotation). A common strategy enforces invariance and equivariance through architectural constraints such as equivariant denoisers and invariant priors. In this paper, we challenge this tradition through the alternative canonicalization perspective: first map each sample to an orbit representative with a canonical pose or order, train an unconstrained (non-equivariant) diffusion or flow model on the canonical slice, and finally recover the invariant distribution by sampling a random symmetry transform at generation time. Building on a formal quotient-space perspective, our work provides a comprehensive theory of canonical diffusion by proving: (i) the correctness, universality and superior expressivity of canonical generative models over invariant targets; (ii) canonicalization accelerates training by removing diffusion score complexity induced by group mixtures and reducing conditional variance in flow matching. We then show that aligned priors and optimal transport act complementarily with canonicalization and further improves training efficiency. We instantiate the framework for molecular graph generation under $S_n \times SE(3)$ symmetries. By leveraging geometric spectra-based canonicalization and mild positional encodings, canonical diffusion significantly outperforms equivariant baselines in 3D molecule generation tasks, with similar or even less computation. Moreover, with a novel architecture Canon, CanonFlow achieves state-of-the-art performance on the challenging GEOM-DRUG dataset, and the advantage remains large in few-step generation.
Conformal Prediction Sets for Instance Segmentation
Feb 10, 2026Current instance segmentation models achieve high performance on average predictions, but lack principled uncertainty quantification: their outputs are not calibrated, and there is no guarantee that a predicted mask is close to the ground truth. To address this limitation, we introduce a conformal prediction algorithm to generate adaptive confidence sets for instance segmentation. Given an image and a pixel coordinate query, our algorithm generates a confidence set of instance predictions for that pixel, with a provable guarantee for the probability that at least one of the predictions has high Intersection-Over-Union (IoU) with the true object instance mask. We apply our algorithm to instance segmentation examples in agricultural field delineation, cell segmentation, and vehicle detection. Empirically, we find that our prediction sets vary in size based on query difficulty and attain the target coverage, outperforming existing baselines such as Learn Then Test, Conformal Risk Control, and morphological dilation-based methods. We provide versions of the algorithm with asymptotic and finite sample guarantees.
Conformal Prediction for Generative Models via Adaptive Cluster-Based Density Estimation
Jan 29, 2026Conditional generative models map input variables to complex, high-dimensional distributions, enabling realistic sample generation in a diverse set of domains. A critical challenge with these models is the absence of calibrated uncertainty, which undermines trust in individual outputs for high-stakes applications. To address this issue, we propose a systematic conformal prediction approach tailored to conditional generative models, leveraging density estimation on model-generated samples. We introduce a novel method called CP4Gen, which utilizes clustering-based density estimation to construct prediction sets that are less sensitive to outliers, more interpretable, and of lower structural complexity than existing methods. Extensive experiments on synthetic datasets and real-world applications, including climate emulation tasks, demonstrate that CP4Gen consistently achieves superior performance in terms of prediction set volume and structural simplicity. Our approach offers practitioners a powerful tool for uncertainty estimation associated with conditional generative models, particularly in scenarios demanding rigorous and interpretable prediction sets.
Thought calibration: Efficient and confident test-time scaling
May 23, 2025Reasoning large language models achieve impressive test-time scaling by thinking for longer, but this performance gain comes at significant compute cost. Directly limiting test-time budget hurts overall performance, but not all problems are equally difficult. We propose thought calibration to decide dynamically when thinking can be terminated. To calibrate our decision rule, we view a language model's growing body of thoughts as a nested sequence of reasoning trees, where the goal is to identify the point at which novel reasoning plateaus. We realize this framework through lightweight probes that operate on top of the language model's hidden representations, which are informative of both the reasoning structure and overall consistency of response. Based on three reasoning language models and four datasets, thought calibration preserves model performance with up to a 60% reduction in thinking tokens on in-distribution data, and up to 20% in out-of-distribution data.
Conformal Prediction with Corrupted Labels: Uncertain Imputation and Robust Re-weighting
May 07, 2025We introduce a framework for robust uncertainty quantification in situations where labeled training data are corrupted, through noisy or missing labels. We build on conformal prediction, a statistical tool for generating prediction sets that cover the test label with a pre-specified probability. The validity of conformal prediction, however, holds under the i.i.d assumption, which does not hold in our setting due to the corruptions in the data. To account for this distribution shift, the privileged conformal prediction (PCP) method proposed leveraging privileged information (PI) -- additional features available only during training -- to re-weight the data distribution, yielding valid prediction sets under the assumption that the weights are accurate. In this work, we analyze the robustness of PCP to inaccuracies in the weights. Our analysis indicates that PCP can still yield valid uncertainty estimates even when the weights are poorly estimated. Furthermore, we introduce uncertain imputation (UI), a new conformal method that does not rely on weight estimation. Instead, we impute corrupted labels in a way that preserves their uncertainty. Our approach is supported by theoretical guarantees and validated empirically on both synthetic and real benchmarks. Finally, we show that these techniques can be integrated into a triply robust framework, ensuring statistically valid predictions as long as at least one underlying method is valid.
Lipschitz-Driven Inference: Bias-corrected Confidence Intervals for Spatial Linear Models
Feb 09, 2025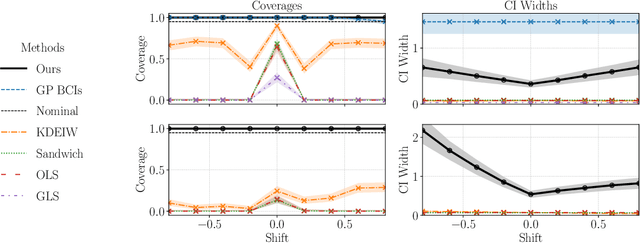
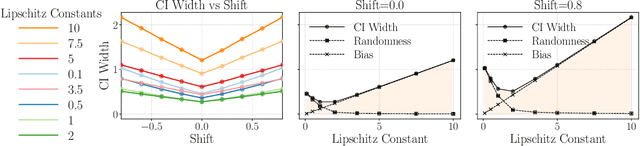
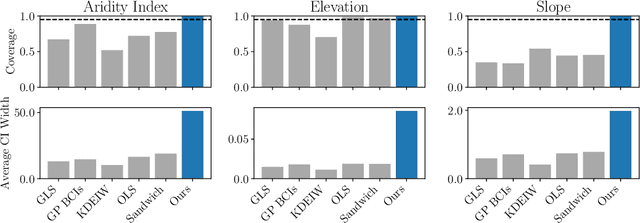
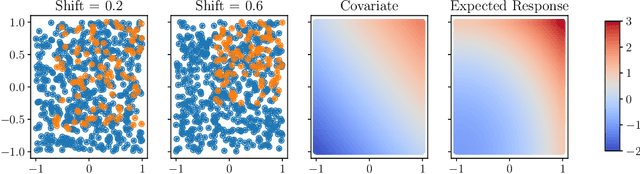
Linear models remain ubiquitous in modern spatial applications - including climate science, public health, and economics - due to their interpretability, speed, and reproducibility. While practitioners generally report a form of uncertainty, popular spatial uncertainty quantification methods do not jointly handle model misspecification and distribution shift - despite both being essentially always present in spatial problems. In the present paper, we show that existing methods for constructing confidence (or credible) intervals in spatial linear models fail to provide correct coverage due to unaccounted-for bias. In contrast to classical methods that rely on an i.i.d. assumption that is inappropriate in spatial problems, in the present work we instead make a spatial smoothness (Lipschitz) assumption. We are then able to propose a new confidence-interval construction that accounts for bias in the estimation procedure. We demonstrate that our new method achieves nominal coverage via both theory and experiments. Code to reproduce experiments is available at https://github.com/DavidRBurt/Lipschitz-Driven-Inference.
Contextual Online Decision Making with Infinite-Dimensional Functional Regression
Jan 30, 2025
Contextual sequential decision-making problems play a crucial role in machine learning, encompassing a wide range of downstream applications such as bandits, sequential hypothesis testing and online risk control. These applications often require different statistical measures, including expectation, variance and quantiles. In this paper, we provide a universal admissible algorithm framework for dealing with all kinds of contextual online decision-making problems that directly learns the whole underlying unknown distribution instead of focusing on individual statistics. This is much more difficult because the dimension of the regression is uncountably infinite, and any existing linear contextual bandits algorithm will result in infinite regret. To overcome this issue, we propose an efficient infinite-dimensional functional regression oracle for contextual cumulative distribution functions (CDFs), where each data point is modeled as a combination of context-dependent CDF basis functions. Our analysis reveals that the decay rate of the eigenvalue sequence of the design integral operator governs the regression error rate and, consequently, the utility regret rate. Specifically, when the eigenvalue sequence exhibits a polynomial decay of order $\frac{1}{\gamma}\ge 1$, the utility regret is bounded by $\tilde{\mathcal{O}}\Big(T^{\frac{3\gamma+2}{2(\gamma+2)}}\Big)$. By setting $\gamma=0$, this recovers the existing optimal regret rate for contextual bandits with finite-dimensional regression and is optimal under a stronger exponential decay assumption. Additionally, we provide a numerical method to compute the eigenvalue sequence of the integral operator, enabling the practical implementation of our framework.
Prediction-Powered Inference with Imputed Covariates and Nonuniform Sampling
Jan 30, 2025



Machine learning models are increasingly used to produce predictions that serve as input data in subsequent statistical analyses. For example, computer vision predictions of economic and environmental indicators based on satellite imagery are used in downstream regressions; similarly, language models are widely used to approximate human ratings and opinions in social science research. However, failure to properly account for errors in the machine learning predictions renders standard statistical procedures invalid. Prior work uses what we call the Predict-Then-Debias estimator to give valid confidence intervals when machine learning algorithms impute missing variables, assuming a small complete sample from the population of interest. We expand the scope by introducing bootstrap confidence intervals that apply when the complete data is a nonuniform (i.e., weighted, stratified, or clustered) sample and to settings where an arbitrary subset of features is imputed. Importantly, the method can be applied to many settings without requiring additional calculations. We prove that these confidence intervals are valid under no assumptions on the quality of the machine learning model and are no wider than the intervals obtained by methods that do not use machine learning predictions.
Sharp Results for Hypothesis Testing with Risk-Sensitive Agents
Dec 21, 2024Statistical protocols are often used for decision-making involving multiple parties, each with their own incentives, private information, and ability to influence the distributional properties of the data. We study a game-theoretic version of hypothesis testing in which a statistician, also known as a principal, interacts with strategic agents that can generate data. The statistician seeks to design a testing protocol with controlled error, while the data-generating agents, guided by their utility and prior information, choose whether or not to opt in based on expected utility maximization. This strategic behavior affects the data observed by the statistician and, consequently, the associated testing error. We analyze this problem for general concave and monotonic utility functions and prove an upper bound on the Bayes false discovery rate (FDR). Underlying this bound is a form of prior elicitation: we show how an agent's choice to opt in implies a certain upper bound on their prior null probability. Our FDR bound is unimprovable in a strong sense, achieving equality at a single point for an individual agent and at any countable number of points for a population of agents. We also demonstrate that our testing protocols exhibit a desirable maximin property when the principal's utility is considered. To illustrate the qualitative predictions of our theory, we examine the effects of risk aversion, reward stochasticity, and signal-to-noise ratio, as well as the implications for the Food and Drug Administration's testing protocols.