 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOh SnapMMD! Forecasting Stochastic Dynamics Beyond the Schrödinger Bridge's End
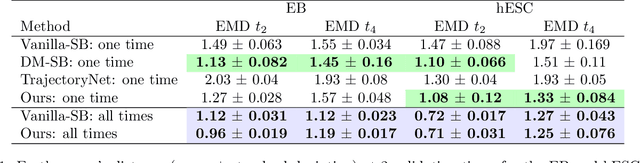
May 21, 2025Scientists often want to make predictions beyond the observed time horizon of "snapshot" data following latent stochastic dynamics. For example, in time course single-cell mRNA profiling, scientists have access to cellular transcriptional state measurements (snapshots) from different biological replicates at different time points, but they cannot access the trajectory of any one cell because measurement destroys the cell. Researchers want to forecast (e.g.) differentiation outcomes from early state measurements of stem cells. Recent Schr\"odinger-bridge (SB) methods are natural for interpolating between snapshots. But past SB papers have not addressed forecasting -- likely since existing methods either (1) reduce to following pre-set reference dynamics (chosen before seeing data) or (2) require the user to choose a fixed, state-independent volatility since they minimize a Kullback-Leibler divergence. Either case can lead to poor forecasting quality. In the present work, we propose a new framework, SnapMMD, that learns dynamics by directly fitting the joint distribution of both state measurements and observation time with a maximum mean discrepancy (MMD) loss. Unlike past work, our method allows us to infer unknown and state-dependent volatilities from the observed data. We show in a variety of real and synthetic experiments that our method delivers accurate forecasts. Moreover, our approach allows us to learn in the presence of incomplete state measurements and yields an $R^2$-style statistic that diagnoses fit. We also find that our method's performance at interpolation (and general velocity-field reconstruction) is at least as good as (and often better than) state-of-the-art in almost all of our experiments.
Lipschitz-Driven Inference: Bias-corrected Confidence Intervals for Spatial Linear Models
Feb 09, 2025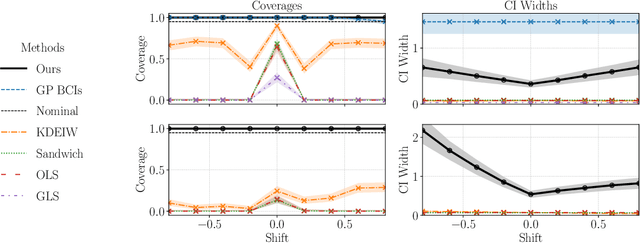
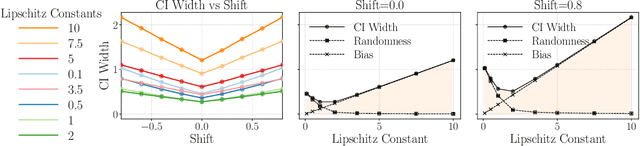
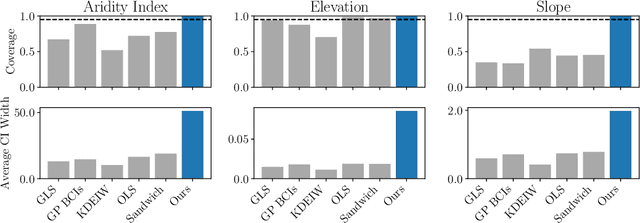
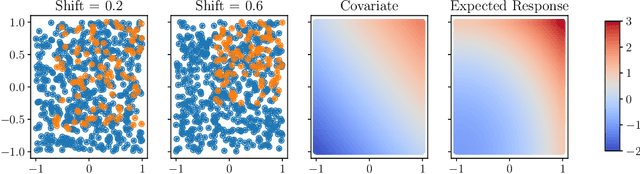
Linear models remain ubiquitous in modern spatial applications - including climate science, public health, and economics - due to their interpretability, speed, and reproducibility. While practitioners generally report a form of uncertainty, popular spatial uncertainty quantification methods do not jointly handle model misspecification and distribution shift - despite both being essentially always present in spatial problems. In the present paper, we show that existing methods for constructing confidence (or credible) intervals in spatial linear models fail to provide correct coverage due to unaccounted-for bias. In contrast to classical methods that rely on an i.i.d. assumption that is inappropriate in spatial problems, in the present work we instead make a spatial smoothness (Lipschitz) assumption. We are then able to propose a new confidence-interval construction that accounts for bias in the estimation procedure. We demonstrate that our new method achieves nominal coverage via both theory and experiments. Code to reproduce experiments is available at https://github.com/DavidRBurt/Lipschitz-Driven-Inference.
A Framework for Evaluating PM2.5 Forecasts from the Perspective of Individual Decision Making
Sep 09, 2024



Wildfire frequency is increasing as the climate changes, and the resulting air pollution poses health risks. Just as people routinely use weather forecasts to plan their activities around precipitation, reliable air quality forecasts could help individuals reduce their exposure to air pollution. In the present work, we evaluate several existing forecasts of fine particular matter (PM2.5) within the continental United States in the context of individual decision-making. Our comparison suggests there is meaningful room for improvement in air pollution forecasting, which might be realized by incorporating more data sources and using machine learning tools. To facilitate future machine learning development and benchmarking, we set up a framework to evaluate and compare air pollution forecasts for individual decision making. We introduce a new loss to capture decisions about when to use mitigation measures. We highlight the importance of visualizations when comparing forecasts. Finally, we provide code to download and compare archived forecast predictions.
Multi-marginal Schrödinger Bridges with Iterative Reference
Aug 12, 2024


Practitioners frequently aim to infer an unobserved population trajectory using sample snapshots at multiple time points. For instance, in single-cell sequencing, scientists would like to learn how gene expression evolves over time. But sequencing any cell destroys that cell. So we cannot access any cell's full trajectory, but we can access snapshot samples from many cells. Stochastic differential equations are commonly used to analyze systems with full individual-trajectory access; since here we have only sample snapshots, these methods are inapplicable. The deep learning community has recently explored using Schr\"odinger bridges (SBs) and their extensions to estimate these dynamics. However, these methods either (1) interpolate between just two time points or (2) require a single fixed reference dynamic within the SB, which is often just set to be Brownian motion. But learning piecewise from adjacent time points can fail to capture long-term dependencies. And practitioners are typically able to specify a model class for the reference dynamic but not the exact values of the parameters within it. So we propose a new method that (1) learns the unobserved trajectories from sample snapshots across multiple time points and (2) requires specification only of a class of reference dynamics, not a single fixed one. In particular, we suggest an iterative projection method inspired by Schr\"odinger bridges; we alternate between learning a piecewise SB on the unobserved trajectories and using the learned SB to refine our best guess for the dynamics within the reference class. We demonstrate the advantages of our method via a well-known simulated parametric model from ecology, simulated and real data from systems biology, and real motion-capture data.
Gaussian processes at the Helm: A more fluid model for ocean currents
Feb 20, 2023



Oceanographers are interested in predicting ocean currents and identifying divergences in a current vector field based on sparse observations of buoy velocities. Since we expect current dynamics to be smooth but highly non-linear, Gaussian processes (GPs) offer an attractive model. But we show that applying a GP with a standard stationary kernel directly to buoy data can struggle at both current prediction and divergence identification -- due to some physically unrealistic prior assumptions. To better reflect known physical properties of currents, we propose to instead put a standard stationary kernel on the divergence and curl-free components of a vector field obtained through a Helmholtz decomposition. We show that, because this decomposition relates to the original vector field just via mixed partial derivatives, we can still perform inference given the original data with only a small constant multiple of additional computational expense. We illustrate the benefits of our method on synthetic and real ocean data.
Subspace Diffusion Generative Models
May 03, 2022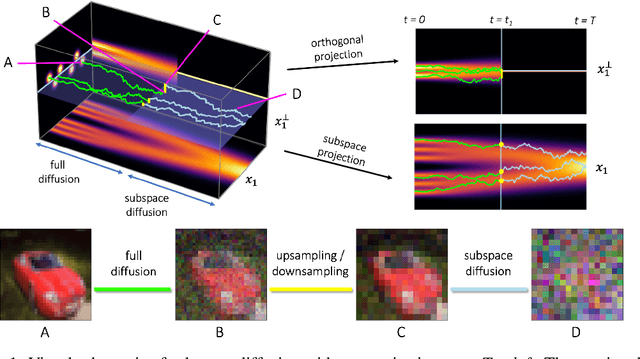
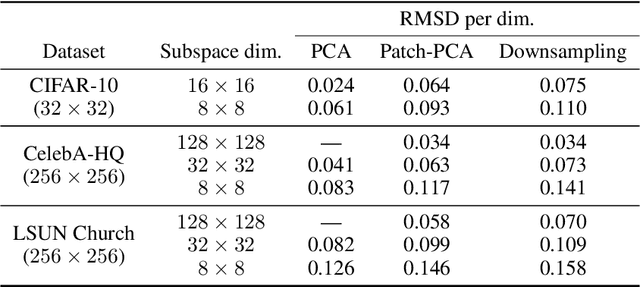
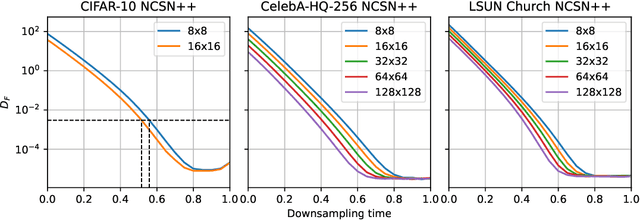

Score-based models generate samples by mapping noise to data (and vice versa) via a high-dimensional diffusion process. We question whether it is necessary to run this entire process at high dimensionality and incur all the inconveniences thereof. Instead, we restrict the diffusion via projections onto subspaces as the data distribution evolves toward noise. When applied to state-of-the-art models, our framework simultaneously improves sample quality -- reaching an FID of 2.17 on unconditional CIFAR-10 -- and reduces the computational cost of inference for the same number of denoising steps. Our framework is fully compatible with continuous-time diffusion and retains its flexible capabilities, including exact log-likelihoods and controllable generation. Code is available at https://github.com/bjing2016/subspace-diffusion.