 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo covariates explain why these groups differ? The choice of reference group can reverse conclusions in the Oaxaca-Blinder decomposition
Mar 31, 2026Scientists often want to explain why an outcome is different in two groups. For instance, differences in patient mortality rates across two hospitals could be due to differences in the patients themselves (covariates) or differences in medical care (outcomes given covariates). The Oaxaca--Blinder decomposition (OBD) is a standard tool to tease apart these factors. It is well known that the OBD requires choosing one of the groups as a reference, and the numerical answer can vary with the reference. To the best of our knowledge, there has not been a systematic investigation into whether the choice of OBD reference can yield different substantive conclusions and how common this issue is. In the present paper, we give existence proofs in real and simulated data that the OBD references can yield substantively different conclusions and that these differences are not entirely driven by model misspecification or small data. We prove that substantively different conclusions occur in up to half of the parameter space, but find these discrepancies rare in the real-data analyses we study. We explain this empirical rarity by examining how realistic data-generating processes can be biased towards parameters that do not change conclusions under the OBD.
Do LLMs Benefit From Their Own Words?
Feb 27, 2026Multi-turn interactions with large language models typically retain the assistant's own past responses in the conversation history. In this work, we revisit this design choice by asking whether large language models benefit from conditioning on their own prior responses. Using in-the-wild, multi-turn conversations, we compare standard (full-context) prompting with a user-turn-only prompting approach that omits all previous assistant responses, across three open reasoning models and one state-of-the-art model. To our surprise, we find that removing prior assistant responses does not affect response quality on a large fraction of turns. Omitting assistant-side history can reduce cumulative context lengths by up to 10x. To explain this result, we find that multi-turn conversations consist of a substantial proportion (36.4%) of self-contained prompts, and that many follow-up prompts provide sufficient instruction to be answered using only the current user turn and prior user turns. When analyzing cases where user-turn-only prompting substantially outperforms full context, we identify instances of context pollution, in which models over-condition on their previous responses, introducing errors, hallucinations, or stylistic artifacts that propagate across turns. Motivated by these findings, we design a context-filtering approach that selectively omits assistant-side context. Our findings suggest that selectively omitting assistant history can improve response quality while reducing memory consumption.
Oh SnapMMD! Forecasting Stochastic Dynamics Beyond the Schrödinger Bridge's End
May 21, 2025Scientists often want to make predictions beyond the observed time horizon of "snapshot" data following latent stochastic dynamics. For example, in time course single-cell mRNA profiling, scientists have access to cellular transcriptional state measurements (snapshots) from different biological replicates at different time points, but they cannot access the trajectory of any one cell because measurement destroys the cell. Researchers want to forecast (e.g.) differentiation outcomes from early state measurements of stem cells. Recent Schr\"odinger-bridge (SB) methods are natural for interpolating between snapshots. But past SB papers have not addressed forecasting -- likely since existing methods either (1) reduce to following pre-set reference dynamics (chosen before seeing data) or (2) require the user to choose a fixed, state-independent volatility since they minimize a Kullback-Leibler divergence. Either case can lead to poor forecasting quality. In the present work, we propose a new framework, SnapMMD, that learns dynamics by directly fitting the joint distribution of both state measurements and observation time with a maximum mean discrepancy (MMD) loss. Unlike past work, our method allows us to infer unknown and state-dependent volatilities from the observed data. We show in a variety of real and synthetic experiments that our method delivers accurate forecasts. Moreover, our approach allows us to learn in the presence of incomplete state measurements and yields an $R^2$-style statistic that diagnoses fit. We also find that our method's performance at interpolation (and general velocity-field reconstruction) is at least as good as (and often better than) state-of-the-art in almost all of our experiments.
Common Functional Decompositions Can Mis-attribute Differences in Outcomes Between Populations
Apr 23, 2025In science and social science, we often wish to explain why an outcome is different in two populations. For instance, if a jobs program benefits members of one city more than another, is that due to differences in program participants (particular covariates) or the local labor markets (outcomes given covariates)? The Kitagawa-Oaxaca-Blinder (KOB) decomposition is a standard tool in econometrics that explains the difference in the mean outcome across two populations. However, the KOB decomposition assumes a linear relationship between covariates and outcomes, while the true relationship may be meaningfully nonlinear. Modern machine learning boasts a variety of nonlinear functional decompositions for the relationship between outcomes and covariates in one population. It seems natural to extend the KOB decomposition using these functional decompositions. We observe that a successful extension should not attribute the differences to covariates -- or, respectively, to outcomes given covariates -- if those are the same in the two populations. Unfortunately, we demonstrate that, even in simple examples, two common decompositions -- functional ANOVA and Accumulated Local Effects -- can attribute differences to outcomes given covariates, even when they are identical in two populations. We provide a characterization of when functional ANOVA misattributes, as well as a general property that any discrete decomposition must satisfy to avoid misattribution. We show that if the decomposition is independent of its input distribution, it does not misattribute. We further conjecture that misattribution arises in any reasonable additive decomposition that depends on the distribution of the covariates.
Lipschitz-Driven Inference: Bias-corrected Confidence Intervals for Spatial Linear Models
Feb 09, 2025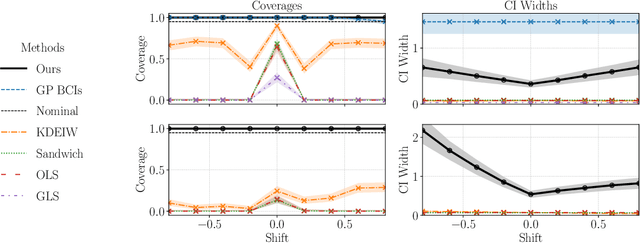
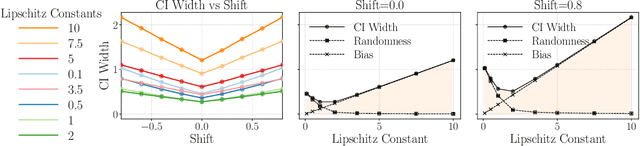
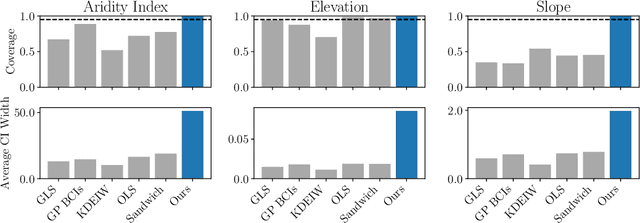
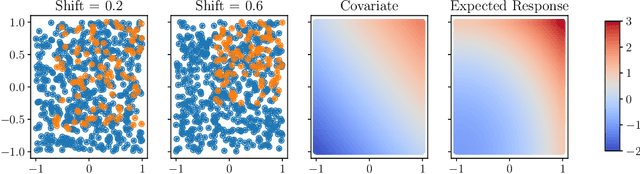
Linear models remain ubiquitous in modern spatial applications - including climate science, public health, and economics - due to their interpretability, speed, and reproducibility. While practitioners generally report a form of uncertainty, popular spatial uncertainty quantification methods do not jointly handle model misspecification and distribution shift - despite both being essentially always present in spatial problems. In the present paper, we show that existing methods for constructing confidence (or credible) intervals in spatial linear models fail to provide correct coverage due to unaccounted-for bias. In contrast to classical methods that rely on an i.i.d. assumption that is inappropriate in spatial problems, in the present work we instead make a spatial smoothness (Lipschitz) assumption. We are then able to propose a new confidence-interval construction that accounts for bias in the estimation procedure. We demonstrate that our new method achieves nominal coverage via both theory and experiments. Code to reproduce experiments is available at https://github.com/DavidRBurt/Lipschitz-Driven-Inference.
A Framework for Evaluating PM2.5 Forecasts from the Perspective of Individual Decision Making
Sep 09, 2024



Wildfire frequency is increasing as the climate changes, and the resulting air pollution poses health risks. Just as people routinely use weather forecasts to plan their activities around precipitation, reliable air quality forecasts could help individuals reduce their exposure to air pollution. In the present work, we evaluate several existing forecasts of fine particular matter (PM2.5) within the continental United States in the context of individual decision-making. Our comparison suggests there is meaningful room for improvement in air pollution forecasting, which might be realized by incorporating more data sources and using machine learning tools. To facilitate future machine learning development and benchmarking, we set up a framework to evaluate and compare air pollution forecasts for individual decision making. We introduce a new loss to capture decisions about when to use mitigation measures. We highlight the importance of visualizations when comparing forecasts. Finally, we provide code to download and compare archived forecast predictions.
Multi-marginal Schrödinger Bridges with Iterative Reference
Aug 12, 2024
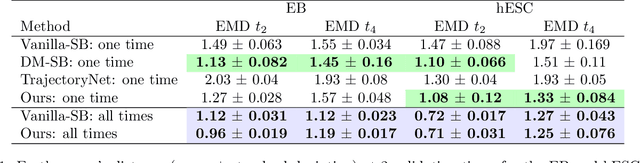


Practitioners frequently aim to infer an unobserved population trajectory using sample snapshots at multiple time points. For instance, in single-cell sequencing, scientists would like to learn how gene expression evolves over time. But sequencing any cell destroys that cell. So we cannot access any cell's full trajectory, but we can access snapshot samples from many cells. Stochastic differential equations are commonly used to analyze systems with full individual-trajectory access; since here we have only sample snapshots, these methods are inapplicable. The deep learning community has recently explored using Schr\"odinger bridges (SBs) and their extensions to estimate these dynamics. However, these methods either (1) interpolate between just two time points or (2) require a single fixed reference dynamic within the SB, which is often just set to be Brownian motion. But learning piecewise from adjacent time points can fail to capture long-term dependencies. And practitioners are typically able to specify a model class for the reference dynamic but not the exact values of the parameters within it. So we propose a new method that (1) learns the unobserved trajectories from sample snapshots across multiple time points and (2) requires specification only of a class of reference dynamics, not a single fixed one. In particular, we suggest an iterative projection method inspired by Schr\"odinger bridges; we alternate between learning a piecewise SB on the unobserved trajectories and using the learned SB to refine our best guess for the dynamics within the reference class. We demonstrate the advantages of our method via a well-known simulated parametric model from ecology, simulated and real data from systems biology, and real motion-capture data.
Consistent Validation for Predictive Methods in Spatial Settings
Feb 05, 2024

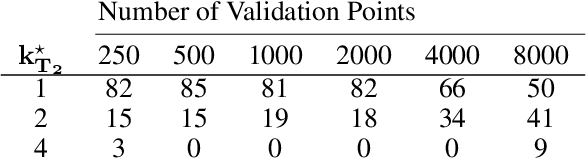

Spatial prediction tasks are key to weather forecasting, studying air pollution, and other scientific endeavors. Determining how much to trust predictions made by statistical or physical methods is essential for the credibility of scientific conclusions. Unfortunately, classical approaches for validation fail to handle mismatch between locations available for validation and (test) locations where we want to make predictions. This mismatch is often not an instance of covariate shift (as commonly formalized) because the validation and test locations are fixed (e.g., on a grid or at select points) rather than i.i.d. from two distributions. In the present work, we formalize a check on validation methods: that they become arbitrarily accurate as validation data becomes arbitrarily dense. We show that classical and covariate-shift methods can fail this check. We instead propose a method that builds from existing ideas in the covariate-shift literature, but adapts them to the validation data at hand. We prove that our proposal passes our check. And we demonstrate its advantages empirically on simulated and real data.
Black Box Variational Inference with a Deterministic Objective: Faster, More Accurate, and Even More Black Box
Apr 11, 2023



Automatic differentiation variational inference (ADVI) offers fast and easy-to-use posterior approximation in multiple modern probabilistic programming languages. However, its stochastic optimizer lacks clear convergence criteria and requires tuning parameters. Moreover, ADVI inherits the poor posterior uncertainty estimates of mean-field variational Bayes (MFVB). We introduce ``deterministic ADVI'' (DADVI) to address these issues. DADVI replaces the intractable MFVB objective with a fixed Monte Carlo approximation, a technique known in the stochastic optimization literature as the ``sample average approximation'' (SAA). By optimizing an approximate but deterministic objective, DADVI can use off-the-shelf second-order optimization, and, unlike standard mean-field ADVI, is amenable to more accurate posterior linear response (LR) covariance estimates. In contrast to existing worst-case theory, we show that, on certain classes of common statistical problems, DADVI and the SAA can perform well with relatively few samples even in very high dimensions, though we also show that such favorable results cannot extend to variational approximations that are too expressive relative to mean-field ADVI. We show on a variety of real-world problems that DADVI reliably finds good solutions with default settings (unlike ADVI) and, together with LR covariances, is typically faster and more accurate than standard ADVI.
Gaussian processes at the Helm: A more fluid model for ocean currents
Feb 20, 2023



Oceanographers are interested in predicting ocean currents and identifying divergences in a current vector field based on sparse observations of buoy velocities. Since we expect current dynamics to be smooth but highly non-linear, Gaussian processes (GPs) offer an attractive model. But we show that applying a GP with a standard stationary kernel directly to buoy data can struggle at both current prediction and divergence identification -- due to some physically unrealistic prior assumptions. To better reflect known physical properties of currents, we propose to instead put a standard stationary kernel on the divergence and curl-free components of a vector field obtained through a Helmholtz decomposition. We show that, because this decomposition relates to the original vector field just via mixed partial derivatives, we can still perform inference given the original data with only a small constant multiple of additional computational expense. We illustrate the benefits of our method on synthetic and real ocean data.