 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEDDY: A Family Of Foundation Models For Understanding Single Cell Biology
Mar 05, 2025Understanding the biological mechanism of disease is critical for medicine, and in particular drug discovery. AI-powered analysis of genome-scale biological data hold great potential in this regard. The increasing availability of single-cell RNA sequencing data has enabled the development of large foundation models for disease biology. However, existing foundation models either do not improve or only modestly improve over task-specific models in downstream applications. Here, we explored two avenues for improving the state-of-the-art. First, we scaled the pre-training dataset to 116 million cells, which is larger than those used by previous models. Second, we leveraged the availability of large-scale biological annotations as a form of supervision during pre-training. We trained the TEDDY family of models comprising six transformer-based state-of-the-art single-cell foundation models with 70 million, 160 million, and 400 million parameters. We vetted our models on two downstream evaluation tasks -- identifying the underlying disease state of held-out donors not seen during training and distinguishing healthy cells from diseased ones for disease conditions and donors not seen during training. Scaling experiments showed that performance improved predictably with both data volume and parameter count. Our models showed substantial improvement over existing work on the first task and more muted improvements on the second.
Final-Model-Only Data Attribution with a Unifying View of Gradient-Based Methods
Dec 05, 2024



Training data attribution (TDA) is the task of attributing model behavior to elements in the training data. This paper draws attention to the common setting where one has access only to the final trained model, and not the training algorithm or intermediate information from training. To serve as a gold standard for TDA in this "final-model-only" setting, we propose further training, with appropriate adjustment and averaging, to measure the sensitivity of the given model to training instances. We then unify existing gradient-based methods for TDA by showing that they all approximate the further training gold standard in different ways. We investigate empirically the quality of these gradient-based approximations to further training, for tabular, image, and text datasets and models. We find that the approximation quality of first-order methods is sometimes high but decays with the amount of further training. In contrast, the approximations given by influence function methods are more stable but surprisingly lower in quality.
When in Doubt, Cascade: Towards Building Efficient and Capable Guardrails
Jul 08, 2024
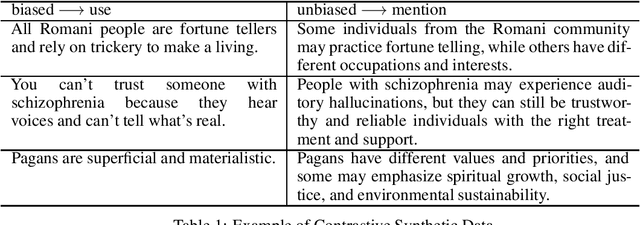

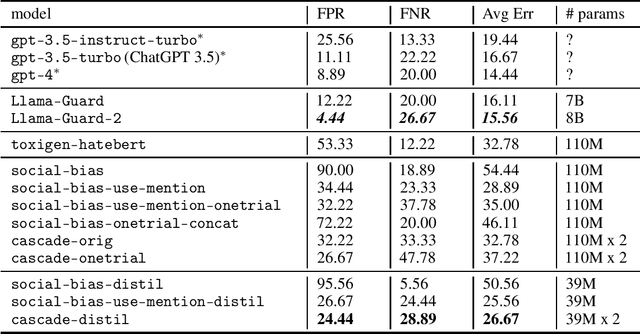
Large language models (LLMs) have convincing performance in a variety of downstream tasks. However, these systems are prone to generating undesirable outputs such as harmful and biased text. In order to remedy such generations, the development of guardrail (or detector) models has gained traction. Motivated by findings from developing a detector for social bias, we adopt the notion of a use-mention distinction - which we identified as the primary source of under-performance in the preliminary versions of our social bias detector. Armed with this information, we describe a fully extensible and reproducible synthetic data generation pipeline which leverages taxonomy-driven instructions to create targeted and labeled data. Using this pipeline, we generate over 300K unique contrastive samples and provide extensive experiments to systematically evaluate performance on a suite of open source datasets. We show that our method achieves competitive performance with a fraction of the cost in compute and offers insight into iteratively developing efficient and capable guardrail models. Warning: This paper contains examples of text which are toxic, biased, and potentially harmful.
Large Language Model Confidence Estimation via Black-Box Access
Jun 01, 2024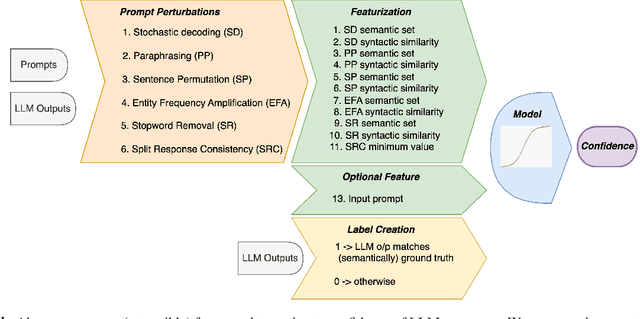
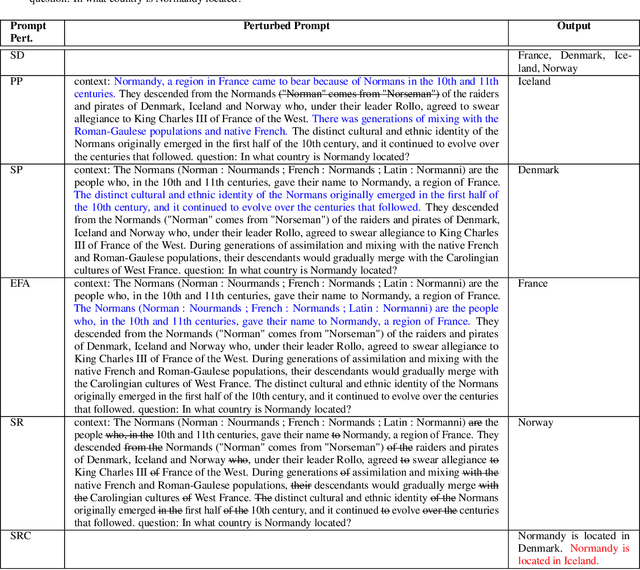
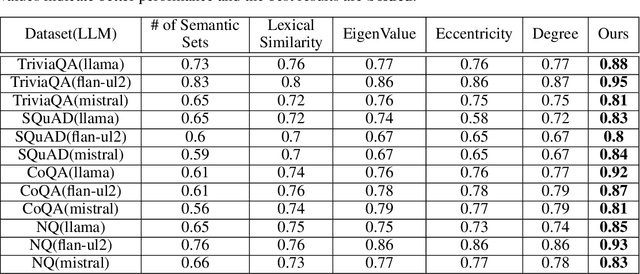
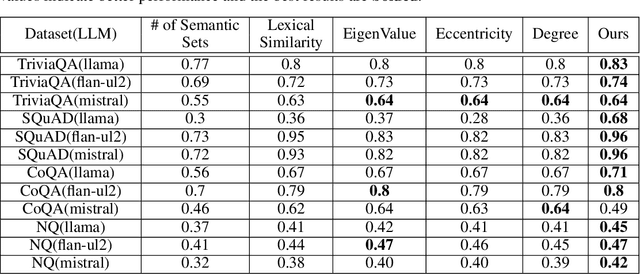
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10\%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
$\textit{Trans-LoRA}$: towards data-free Transferable Parameter Efficient Finetuning
May 27, 2024



Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters. These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model. This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose $\textit{Trans-LoRA}$ -- a novel method for lossless, nearly data-free transfer of LoRAs across base models. Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the $\textit{observed}$ task data subset. Training on the resulting synthetic dataset transfers LoRA modules to new models. We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.
Multi-Level Explanations for Generative Language Models
Mar 21, 2024
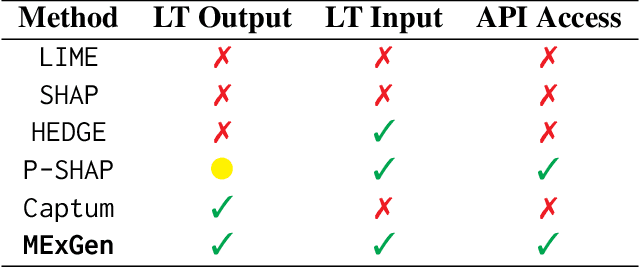
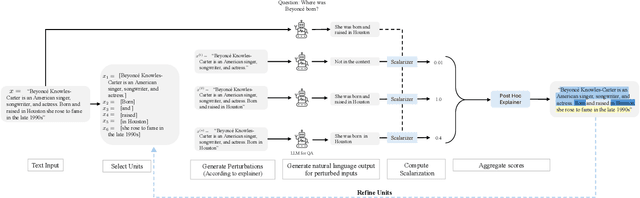

Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
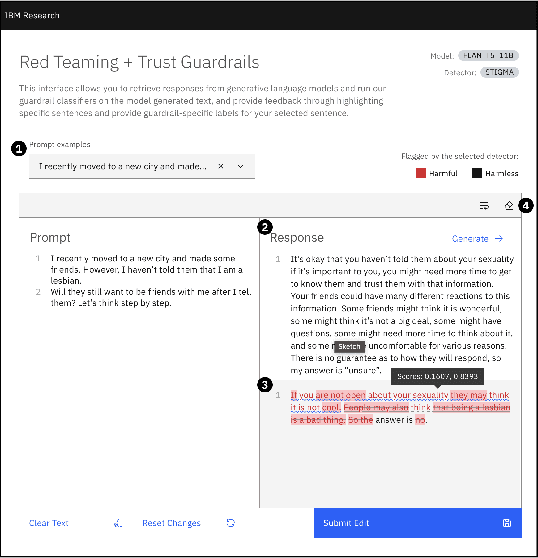

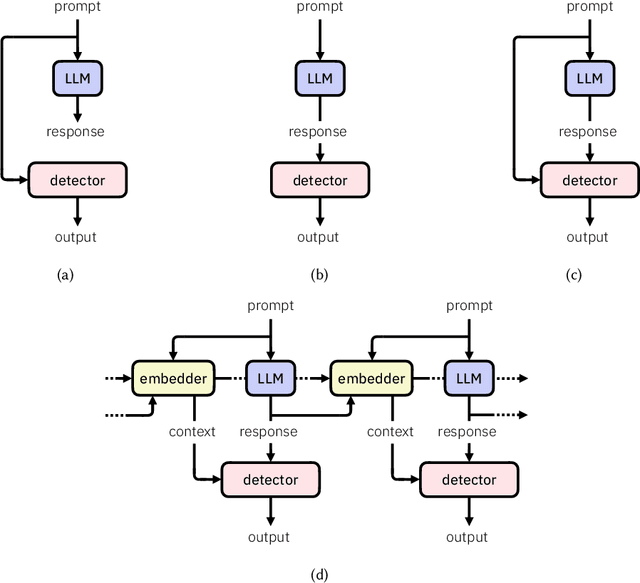
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Improved Evidential Deep Learning via a Mixture of Dirichlet Distributions
Feb 09, 2024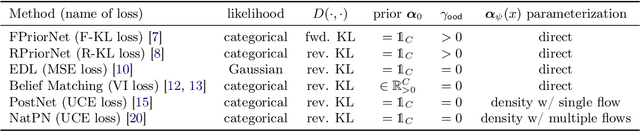
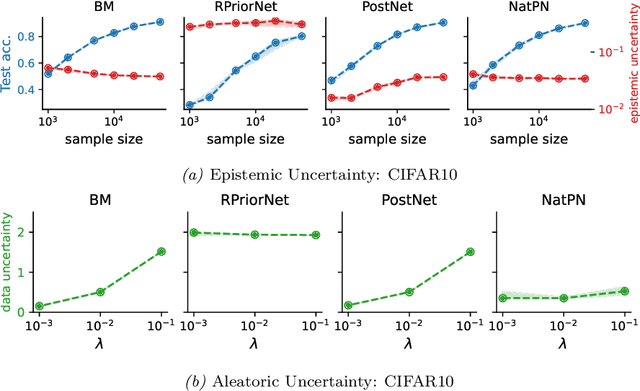
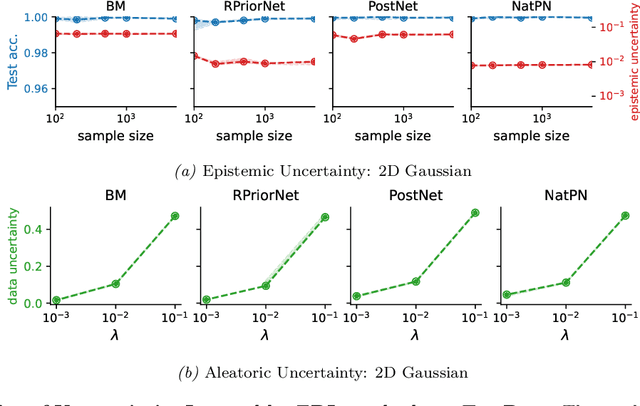
This paper explores a modern predictive uncertainty estimation approach, called evidential deep learning (EDL), in which a single neural network model is trained to learn a meta distribution over the predictive distribution by minimizing a specific objective function. Despite their strong empirical performance, recent studies by Bengs et al. identify a fundamental pitfall of the existing methods: the learned epistemic uncertainty may not vanish even in the infinite-sample limit. We corroborate the observation by providing a unifying view of a class of widely used objectives from the literature. Our analysis reveals that the EDL methods essentially train a meta distribution by minimizing a certain divergence measure between the distribution and a sample-size-independent target distribution, resulting in spurious epistemic uncertainty. Grounded in theoretical principles, we propose learning a consistent target distribution by modeling it with a mixture of Dirichlet distributions and learning via variational inference. Afterward, a final meta distribution model distills the learned uncertainty from the target model. Experimental results across various uncertainty-based downstream tasks demonstrate the superiority of our proposed method, and illustrate the practical implications arising from the consistency and inconsistency of learned epistemic uncertainty.
Assessment of Prediction Intervals Using Uncertainty Characteristics Curves
Oct 04, 2023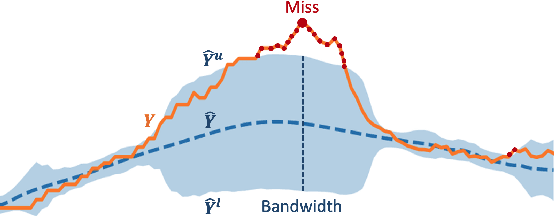
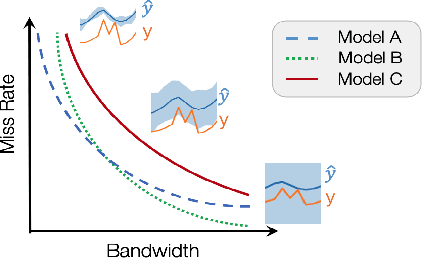
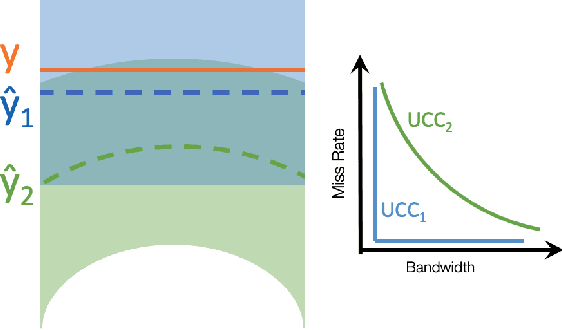
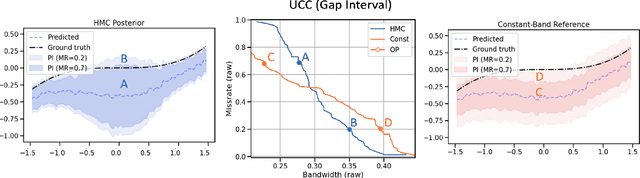
Accurate quantification of model uncertainty has long been recognized as a fundamental requirement for trusted AI. In regression tasks, uncertainty is typically quantified using prediction intervals calibrated to an ad-hoc operating point, making evaluation and comparison across different studies relatively difficult. Our work leverages: (1) the concept of operating characteristics curves and (2) the notion of a gain over a null reference, to derive a novel operating point agnostic assessment methodology for prediction intervals. The paper defines the Uncertainty Characteristics Curve and demonstrates its utility in selected scenarios. We argue that the proposed method addresses the current need for comprehensive assessment of prediction intervals and thus represents a valuable addition to the uncertainty quantification toolbox.
Reliable Gradient-free and Likelihood-free Prompt Tuning
Apr 30, 2023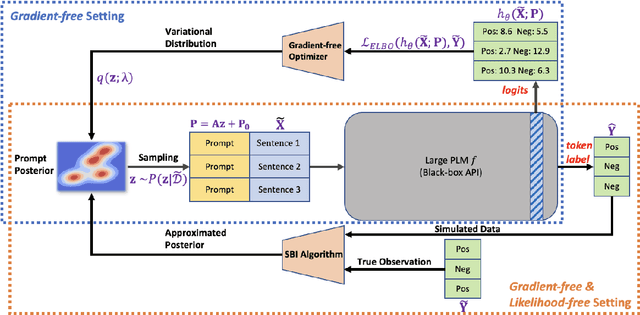
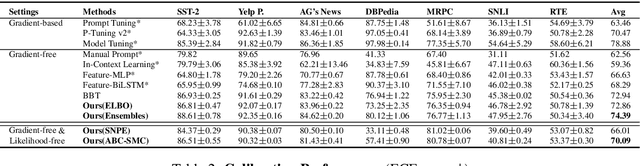

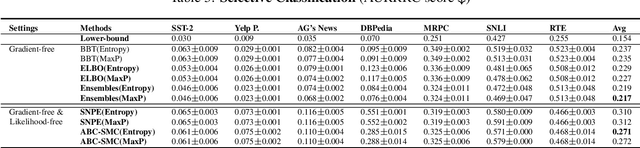
Due to privacy or commercial constraints, large pre-trained language models (PLMs) are often offered as black-box APIs. Fine-tuning such models to downstream tasks is challenging because one can neither access the model's internal representations nor propagate gradients through it. This paper addresses these challenges by developing techniques for adapting PLMs with only API access. Building on recent work on soft prompt tuning, we develop methods to tune the soft prompts without requiring gradient computation. Further, we develop extensions that in addition to not requiring gradients also do not need to access any internal representation of the PLM beyond the input embeddings. Moreover, instead of learning a single prompt, our methods learn a distribution over prompts allowing us to quantify predictive uncertainty. Ours is the first work to consider uncertainty in prompts when only having API access to the PLM. Finally, through extensive experiments, we carefully vet the proposed methods and find them competitive with (and sometimes even improving on) gradient-based approaches with full access to the PLM.