 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICX360: In-Context eXplainability 360 Toolkit
Nov 14, 2025Large Language Models (LLMs) have become ubiquitous in everyday life and are entering higher-stakes applications ranging from summarizing meeting transcripts to answering doctors' questions. As was the case with earlier predictive models, it is crucial that we develop tools for explaining the output of LLMs, be it a summary, list, response to a question, etc. With these needs in mind, we introduce In-Context Explainability 360 (ICX360), an open-source Python toolkit for explaining LLMs with a focus on the user-provided context (or prompts in general) that are fed to the LLMs. ICX360 contains implementations for three recent tools that explain LLMs using both black-box and white-box methods (via perturbations and gradients respectively). The toolkit, available at https://github.com/IBM/ICX360, contains quick-start guidance materials as well as detailed tutorials covering use cases such as retrieval augmented generation, natural language generation, and jailbreaking.
Small Models, Smarter Learning: The Power of Joint Task Training
May 23, 2025The ability of a model to learn a task depends strongly on both the task difficulty and the model size. We aim to understand how task difficulty relates to the minimum number of parameters required for learning specific tasks in small transformer models. Our study focuses on the ListOps dataset, which consists of nested mathematical operations. We gradually increase task difficulty by introducing new operations or combinations of operations into the training data. We observe that sum modulo n is the hardest to learn. Curiously, when combined with other operations such as maximum and median, the sum operation becomes easier to learn and requires fewer parameters. We show that joint training not only improves performance but also leads to qualitatively different model behavior. We show evidence that models trained only on SUM might be memorizing and fail to capture the number structure in the embeddings. In contrast, models trained on a mixture of SUM and other operations exhibit number-like representations in the embedding space, and a strong ability to distinguish parity. Furthermore, the SUM-only model relies more heavily on its feedforward layers, while the jointly trained model activates the attention mechanism more. Finally, we show that learning pure SUM can be induced in models below the learning threshold of pure SUM, by pretraining them on MAX+MED. Our findings indicate that emergent abilities in language models depend not only on model size, but also the training curriculum.
GPT-2 Through the Lens of Vector Symbolic Architectures
Dec 10, 2024Understanding the general priniciples behind transformer models remains a complex endeavor. Experiments with probing and disentangling features using sparse autoencoders (SAE) suggest that these models might manage linear features embedded as directions in the residual stream. This paper explores the resemblance between decoder-only transformer architecture and vector symbolic architectures (VSA) and presents experiments indicating that GPT-2 uses mechanisms involving nearly orthogonal vector bundling and binding operations similar to VSA for computation and communication between layers. It further shows that these principles help explain a significant portion of the actual neural weights.
Dense Associative Memory Through the Lens of Random Features
Oct 31, 2024

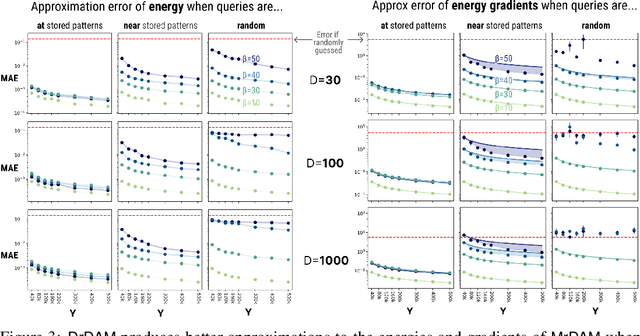
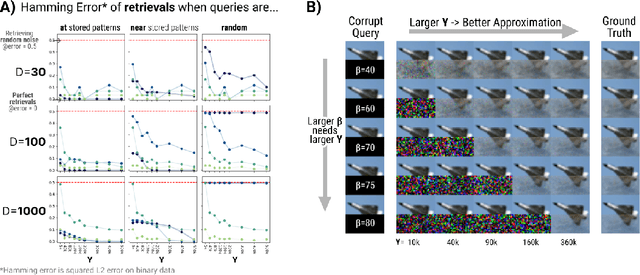
Dense Associative Memories are high storage capacity variants of the Hopfield networks that are capable of storing a large number of memory patterns in the weights of the network of a given size. Their common formulations typically require storing each pattern in a separate set of synaptic weights, which leads to the increase of the number of synaptic weights when new patterns are introduced. In this work we propose an alternative formulation of this class of models using random features, commonly used in kernel methods. In this formulation the number of network's parameters remains fixed. At the same time, new memories can be added to the network by modifying existing weights. We show that this novel network closely approximates the energy function and dynamics of conventional Dense Associative Memories and shares their desirable computational properties.
Why context matters in VQA and Reasoning: Semantic interventions for VLM input modalities
Oct 02, 2024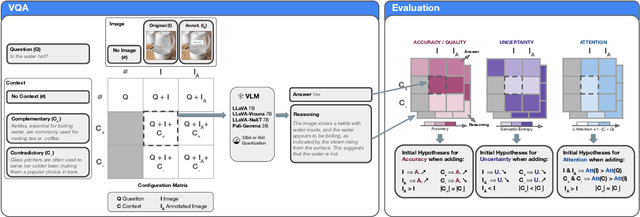

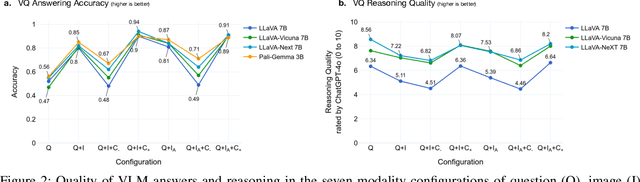
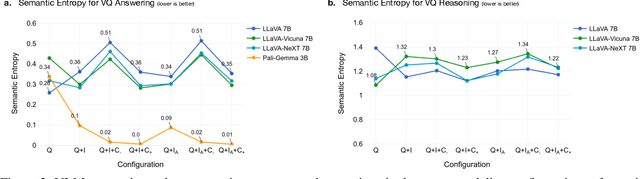
The various limitations of Generative AI, such as hallucinations and model failures, have made it crucial to understand the role of different modalities in Visual Language Model (VLM) predictions. Our work investigates how the integration of information from image and text modalities influences the performance and behavior of VLMs in visual question answering (VQA) and reasoning tasks. We measure this effect through answer accuracy, reasoning quality, model uncertainty, and modality relevance. We study the interplay between text and image modalities in different configurations where visual content is essential for solving the VQA task. Our contributions include (1) the Semantic Interventions (SI)-VQA dataset, (2) a benchmark study of various VLM architectures under different modality configurations, and (3) the Interactive Semantic Interventions (ISI) tool. The SI-VQA dataset serves as the foundation for the benchmark, while the ISI tool provides an interface to test and apply semantic interventions in image and text inputs, enabling more fine-grained analysis. Our results show that complementary information between modalities improves answer and reasoning quality, while contradictory information harms model performance and confidence. Image text annotations have minimal impact on accuracy and uncertainty, slightly increasing image relevance. Attention analysis confirms the dominant role of image inputs over text in VQA tasks. In this study, we evaluate state-of-the-art VLMs that allow us to extract attention coefficients for each modality. A key finding is PaliGemma's harmful overconfidence, which poses a higher risk of silent failures compared to the LLaVA models. This work sets the foundation for rigorous analysis of modality integration, supported by datasets specifically designed for this purpose.
Abstraction Alignment: Comparing Model and Human Conceptual Relationships
Jul 17, 2024



Abstraction -- the process of generalizing specific examples into broad reusable patterns -- is central to how people efficiently process and store information and apply their knowledge to new data. Promisingly, research has shown that ML models learn representations that span levels of abstraction, from specific concepts like "bolo tie" and "car tire" to more general concepts like "CEO" and "model". However, existing techniques analyze these representations in isolation, treating learned concepts as independent artifacts rather than an interconnected web of abstraction. As a result, although we can identify the concepts a model uses to produce its output, it is difficult to assess if it has learned a human-aligned abstraction of the concepts that will generalize to new data. To address this gap, we introduce abstraction alignment, a methodology to measure the agreement between a model's learned abstraction and the expected human abstraction. We quantify abstraction alignment by comparing model outputs against a human abstraction graph, such as linguistic relationships or medical disease hierarchies. In evaluation tasks interpreting image models, benchmarking language models, and analyzing medical datasets, abstraction alignment provides a deeper understanding of model behavior and dataset content, differentiating errors based on their agreement with human knowledge, expanding the verbosity of current model quality metrics, and revealing ways to improve existing human abstractions.
Interactive Analysis of LLMs using Meaningful Counterfactuals
Apr 23, 2024Counterfactual examples are useful for exploring the decision boundaries of machine learning models and determining feature attributions. How can we apply counterfactual-based methods to analyze and explain LLMs? We identify the following key challenges. First, the generated textual counterfactuals should be meaningful and readable to users and thus can be mentally compared to draw conclusions. Second, to make the solution scalable to long-form text, users should be equipped with tools to create batches of counterfactuals from perturbations at various granularity levels and interactively analyze the results. In this paper, we tackle the above challenges and contribute 1) a novel algorithm for generating batches of complete and meaningful textual counterfactuals by removing and replacing text segments in different granularities, and 2) LLM Analyzer, an interactive visualization tool to help users understand an LLM's behaviors by interactively inspecting and aggregating meaningful counterfactuals. We evaluate the proposed algorithm by the grammatical correctness of its generated counterfactuals using 1,000 samples from medical, legal, finance, education, and news datasets. In our experiments, 97.2% of the counterfactuals are grammatically correct. Through a use case, user studies, and feedback from experts, we demonstrate the usefulness and usability of the proposed interactive visualization tool.
Interactive Visual Learning for Stable Diffusion
Apr 22, 2024Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. More than 7,200 users spanning 113 countries have used our open-sourced tool at https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/MbkIADZjPnA.
LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity
Apr 04, 2024



Vision Transformers (ViTs), with their ability to model long-range dependencies through self-attention mechanisms, have become a standard architecture in computer vision. However, the interpretability of these models remains a challenge. To address this, we propose LeGrad, an explainability method specifically designed for ViTs. LeGrad computes the gradient with respect to the attention maps of ViT layers, considering the gradient itself as the explainability signal. We aggregate the signal over all layers, combining the activations of the last as well as intermediate tokens to produce the merged explainability map. This makes LeGrad a conceptually simple and an easy-to-implement tool for enhancing the transparency of ViTs. We evaluate LeGrad in challenging segmentation, perturbation, and open-vocabulary settings, showcasing its versatility compared to other SotA explainability methods demonstrating its superior spatial fidelity and robustness to perturbations. A demo and the code is available at https://github.com/WalBouss/LeGrad.
Multi-Level Explanations for Generative Language Models
Mar 21, 2024
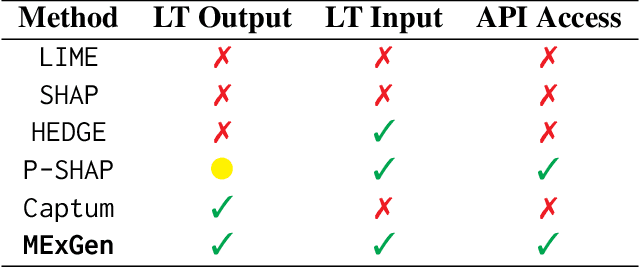
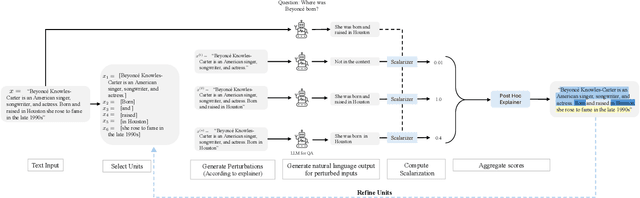

Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.