 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLaVA Meets Objects: Token Composition for Vision-Language-Models
Feb 04, 2026Current autoregressive Vision Language Models (VLMs) usually rely on a large number of visual tokens to represent images, resulting in a need for more compute especially at inference time. To address this problem, we propose Mask-LLaVA, a framework that leverages different levels of visual features to create a compact yet information-rich visual representation for autoregressive VLMs. Namely, we combine mask-based object representations together with global tokens and local patch tokens. While all tokens are used during training, it shows that the resulting model can flexibly drop especially the number of mask-based object-tokens at test time, allowing to adapt the number of tokens during inference without the need to retrain the model and without a significant drop in performance. We evaluate the proposed approach on a suite of standard benchmarks showing results competitive to current token efficient methods and comparable to the original LLaVA baseline using only a fraction of visual tokens. Our analysis demonstrates that combining multi-level features enables efficient learning with fewer tokens while allowing dynamic token selection at test time for good performance.
REVEAL: Relation-based Video Representation Learning for Video-Question-Answering
Apr 07, 2025Video-Question-Answering (VideoQA) comprises the capturing of complex visual relation changes over time, remaining a challenge even for advanced Video Language Models (VLM), i.a., because of the need to represent the visual content to a reasonably sized input for those models. To address this problem, we propose RElation-based Video rEpresentAtion Learning (REVEAL), a framework designed to capture visual relation information by encoding them into structured, decomposed representations. Specifically, inspired by spatiotemporal scene graphs, we propose to encode video sequences as sets of relation triplets in the form of (\textit{subject-predicate-object}) over time via their language embeddings. To this end, we extract explicit relations from video captions and introduce a Many-to-Many Noise Contrastive Estimation (MM-NCE) together with a Q-Former architecture to align an unordered set of video-derived queries with corresponding text-based relation descriptions. At inference, the resulting Q-former produces an efficient token representation that can serve as input to a VLM for VideoQA. We evaluate the proposed framework on five challenging benchmarks: NeXT-QA, Intent-QA, STAR, VLEP, and TVQA. It shows that the resulting query-based video representation is able to outperform global alignment-based CLS or patch token representations and achieves competitive results against state-of-the-art models, particularly on tasks requiring temporal reasoning and relation comprehension. The code and models will be publicly released.
VideoGEM: Training-free Action Grounding in Videos
Mar 26, 2025Vision-language foundation models have shown impressive capabilities across various zero-shot tasks, including training-free localization and grounding, primarily focusing on localizing objects in images. However, leveraging those capabilities to localize actions and events in videos is challenging, as actions have less physical outline and are usually described by higher-level concepts. In this work, we propose VideoGEM, the first training-free spatial action grounding method based on pretrained image- and video-language backbones. Namely, we adapt the self-self attention formulation of GEM to spatial activity grounding. We observe that high-level semantic concepts, such as actions, usually emerge in the higher layers of the image- and video-language models. We, therefore, propose a layer weighting in the self-attention path to prioritize higher layers. Additionally, we introduce a dynamic weighting method to automatically tune layer weights to capture each layer`s relevance to a specific prompt. Finally, we introduce a prompt decomposition, processing action, verb, and object prompts separately, resulting in a better spatial localization of actions. We evaluate the proposed approach on three image- and video-language backbones, CLIP, OpenCLIP, and ViCLIP, and on four video grounding datasets, V-HICO, DALY, YouCook-Interactions, and GroundingYouTube, showing that the proposed training-free approach is able to outperform current trained state-of-the-art approaches for spatial video grounding.
MaskInversion: Localized Embeddings via Optimization of Explainability Maps
Jul 29, 2024Vision-language foundation models such as CLIP have achieved tremendous results in global vision-language alignment, but still show some limitations in creating representations for specific image regions. % To address this problem, we propose MaskInversion, a method that leverages the feature representations of pre-trained foundation models, such as CLIP, to generate a context-aware embedding for a query image region specified by a mask at test time. MaskInversion starts with initializing an embedding token and compares its explainability map, derived from the foundation model, to the query mask. The embedding token is then subsequently refined to approximate the query region by minimizing the discrepancy between its explainability map and the query mask. During this process, only the embedding vector is updated, while the underlying foundation model is kept frozen allowing to use MaskInversion with any pre-trained model. As deriving the explainability map involves computing its gradient, which can be expensive, we propose a gradient decomposition strategy that simplifies this computation. The learned region representation can be used for a broad range of tasks, including open-vocabulary class retrieval, referring expression comprehension, as well as for localized captioning and image generation. We evaluate the proposed method on all those tasks on several datasets such as PascalVOC, MSCOCO, RefCOCO, and OpenImagesV7 and show its capabilities compared to other SOTA approaches.
LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity
Apr 04, 2024



Vision Transformers (ViTs), with their ability to model long-range dependencies through self-attention mechanisms, have become a standard architecture in computer vision. However, the interpretability of these models remains a challenge. To address this, we propose LeGrad, an explainability method specifically designed for ViTs. LeGrad computes the gradient with respect to the attention maps of ViT layers, considering the gradient itself as the explainability signal. We aggregate the signal over all layers, combining the activations of the last as well as intermediate tokens to produce the merged explainability map. This makes LeGrad a conceptually simple and an easy-to-implement tool for enhancing the transparency of ViTs. We evaluate LeGrad in challenging segmentation, perturbation, and open-vocabulary settings, showcasing its versatility compared to other SotA explainability methods demonstrating its superior spatial fidelity and robustness to perturbations. A demo and the code is available at https://github.com/WalBouss/LeGrad.
Grounding Everything: Emerging Localization Properties in Vision-Language Transformers
Dec 05, 2023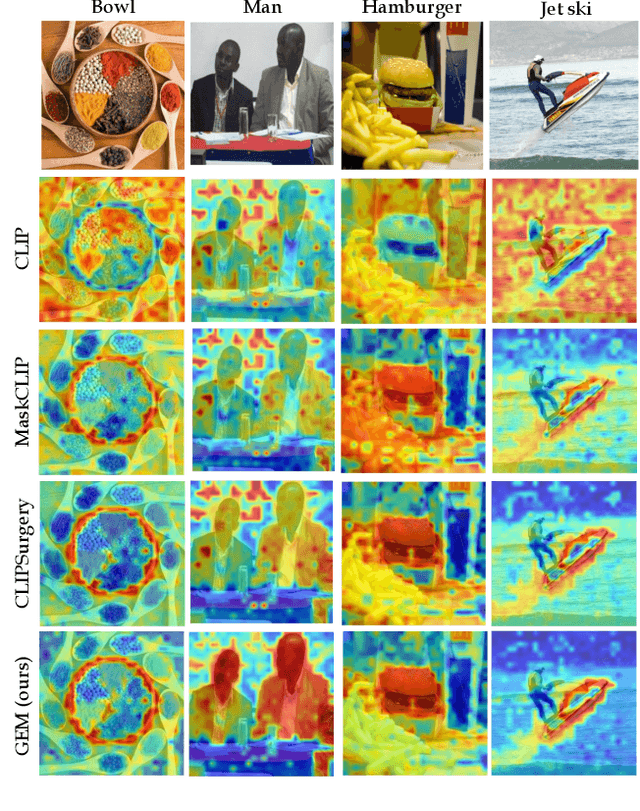
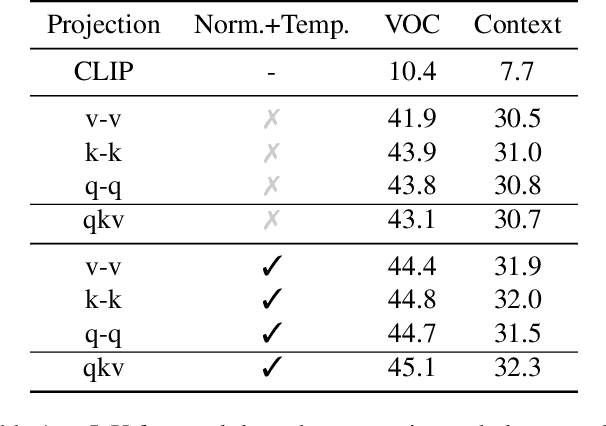
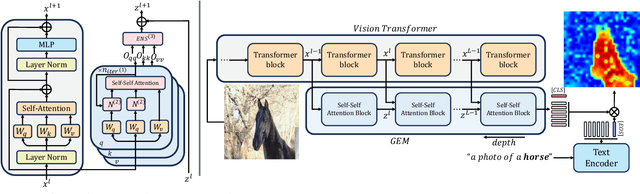
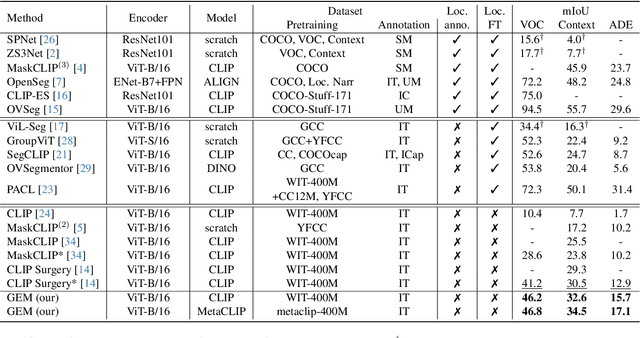
Vision-language foundation models have shown remarkable performance in various zero-shot settings such as image retrieval, classification, or captioning. But so far, those models seem to fall behind when it comes to zero-shot localization of referential expressions and objects in images. As a result, they need to be fine-tuned for this task. In this paper, we show that pretrained vision-language (VL) models allow for zero-shot open-vocabulary object localization without any fine-tuning. To leverage those capabilities, we propose a Grounding Everything Module (GEM) that generalizes the idea of value-value attention introduced by CLIPSurgery to a self-self attention path. We show that the concept of self-self attention corresponds to clustering, thus enforcing groups of tokens arising from the same object to be similar while preserving the alignment with the language space. To further guide the group formation, we propose a set of regularizations that allows the model to finally generalize across datasets and backbones. We evaluate the proposed GEM framework on various benchmark tasks and datasets for semantic segmentation. It shows that GEM not only outperforms other training-free open-vocabulary localization methods, but also achieves state-of-the-art results on the recently proposed OpenImagesV7 large-scale segmentation benchmark.
Learning Situation Hyper-Graphs for Video Question Answering
Apr 18, 2023



Answering questions about complex situations in videos requires not only capturing the presence of actors, objects, and their relations but also the evolution of these relationships over time. A situation hyper-graph is a representation that describes situations as scene sub-graphs for video frames and hyper-edges for connected sub-graphs and has been proposed to capture all such information in a compact structured form. In this work, we propose an architecture for Video Question Answering (VQA) that enables answering questions related to video content by predicting situation hyper-graphs, coined Situation Hyper-Graph based Video Question Answering (SHG-VQA). To this end, we train a situation hyper-graph decoder to implicitly identify graph representations with actions and object/human-object relationships from the input video clip. and to use cross-attention between the predicted situation hyper-graphs and the question embedding to predict the correct answer. The proposed method is trained in an end-to-end manner and optimized by a VQA loss with the cross-entropy function and a Hungarian matching loss for the situation graph prediction. The effectiveness of the proposed architecture is extensively evaluated on two challenging benchmarks: AGQA and STAR. Our results show that learning the underlying situation hyper-graphs helps the system to significantly improve its performance for novel challenges of video question-answering tasks.
Efficient Self-Ensemble Framework for Semantic Segmentation
Nov 26, 2021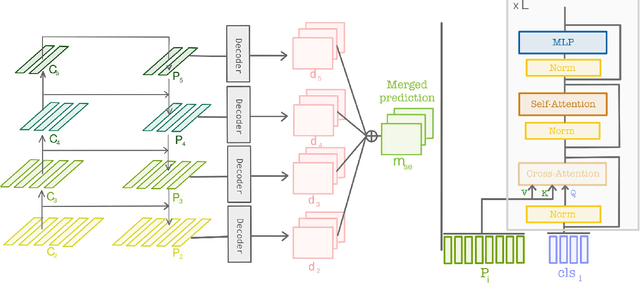
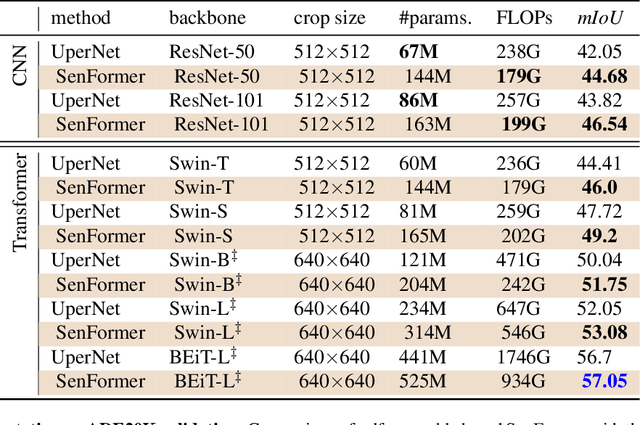
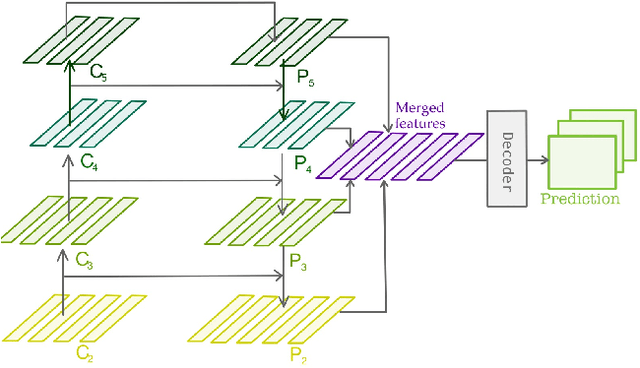

Ensemble of predictions is known to perform better than individual predictions taken separately. However, for tasks that require heavy computational resources, \textit{e.g.} semantic segmentation, creating an ensemble of learners that needs to be trained separately is hardly tractable. In this work, we propose to leverage the performance boost offered by ensemble methods to enhance the semantic segmentation, while avoiding the traditional heavy training cost of the ensemble. Our self-ensemble framework takes advantage of the multi-scale features set produced by feature pyramid network methods to feed independent decoders, thus creating an ensemble within a single model. Similar to the ensemble, the final prediction is the aggregation of the prediction made by each learner. In contrast to previous works, our model can be trained end-to-end, alleviating the traditional cumbersome multi-stage training of ensembles. Our self-ensemble framework outperforms the current state-of-the-art on the benchmark datasets ADE20K, Pascal Context and COCO-Stuff-10K for semantic segmentation and is competitive on Cityscapes. Code will be available at github.com/WalBouss/SenFormer.