 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2SVid: End-to-End Inpainting and Refinement for Monocular-to-Stereo Video Conversion
May 22, 2025We tackle the problem of monocular-to-stereo video conversion and propose a novel architecture for inpainting and refinement of the warped right view obtained by depth-based reprojection of the input left view. We extend the Stable Video Diffusion (SVD) model to utilize the input left video, the warped right video, and the disocclusion masks as conditioning input to generate a high-quality right camera view. In order to effectively exploit information from neighboring frames for inpainting, we modify the attention layers in SVD to compute full attention for discoccluded pixels. Our model is trained to generate the right view video in an end-to-end manner by minimizing image space losses to ensure high-quality generation. Our approach outperforms previous state-of-the-art methods, obtaining an average rank of 1.43 among the 4 compared methods in a user study, while being 6x faster than the second placed method.
VideoGEM: Training-free Action Grounding in Videos
Mar 26, 2025



Vision-language foundation models have shown impressive capabilities across various zero-shot tasks, including training-free localization and grounding, primarily focusing on localizing objects in images. However, leveraging those capabilities to localize actions and events in videos is challenging, as actions have less physical outline and are usually described by higher-level concepts. In this work, we propose VideoGEM, the first training-free spatial action grounding method based on pretrained image- and video-language backbones. Namely, we adapt the self-self attention formulation of GEM to spatial activity grounding. We observe that high-level semantic concepts, such as actions, usually emerge in the higher layers of the image- and video-language models. We, therefore, propose a layer weighting in the self-attention path to prioritize higher layers. Additionally, we introduce a dynamic weighting method to automatically tune layer weights to capture each layer`s relevance to a specific prompt. Finally, we introduce a prompt decomposition, processing action, verb, and object prompts separately, resulting in a better spatial localization of actions. We evaluate the proposed approach on three image- and video-language backbones, CLIP, OpenCLIP, and ViCLIP, and on four video grounding datasets, V-HICO, DALY, YouCook-Interactions, and GroundingYouTube, showing that the proposed training-free approach is able to outperform current trained state-of-the-art approaches for spatial video grounding.
Unbiasing through Textual Descriptions: Mitigating Representation Bias in Video Benchmarks
Mar 24, 2025We propose a new "Unbiased through Textual Description (UTD)" video benchmark based on unbiased subsets of existing video classification and retrieval datasets to enable a more robust assessment of video understanding capabilities. Namely, we tackle the problem that current video benchmarks may suffer from different representation biases, e.g., object bias or single-frame bias, where mere recognition of objects or utilization of only a single frame is sufficient for correct prediction. We leverage VLMs and LLMs to analyze and debias benchmarks from such representation biases. Specifically, we generate frame-wise textual descriptions of videos, filter them for specific information (e.g. only objects) and leverage them to examine representation biases across three dimensions: 1) concept bias - determining if a specific concept (e.g., objects) alone suffice for prediction; 2) temporal bias - assessing if temporal information contributes to prediction; and 3) common sense vs. dataset bias - evaluating whether zero-shot reasoning or dataset correlations contribute to prediction. We conduct a systematic analysis of 12 popular video classification and retrieval datasets and create new object-debiased test splits for these datasets. Moreover, we benchmark 30 state-of-the-art video models on original and debiased splits and analyze biases in the models. To facilitate the future development of more robust video understanding benchmarks and models, we release: "UTD-descriptions", a dataset with our rich structured descriptions for each dataset, and "UTD-splits", a dataset of object-debiased test splits.
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Oct 07, 2023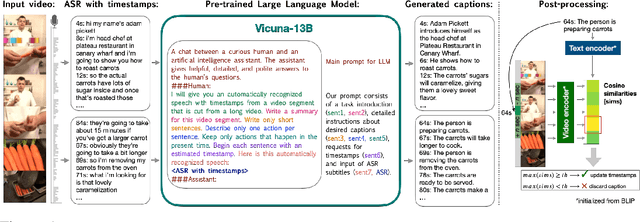
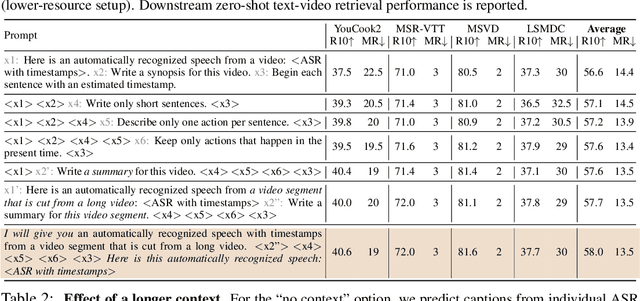


Instructional videos are an excellent source for learning multimodal representations by leveraging video-subtitle pairs extracted with automatic speech recognition systems (ASR) from the audio signal in the videos. However, in contrast to human-annotated captions, both speech and subtitles naturally differ from the visual content of the videos and thus provide only noisy supervision for multimodal learning. As a result, large-scale annotation-free web video training data remains sub-optimal for training text-video models. In this work, we propose to leverage the capability of large language models (LLMs) to obtain fine-grained video descriptions aligned with videos. Specifically, we prompt an LLM to create plausible video descriptions based on ASR narrations of the video for a large-scale instructional video dataset. To this end, we introduce a prompting method that is able to take into account a longer text of subtitles, allowing us to capture context beyond a single sentence. To align the captions to the video temporally, we prompt the LLM to generate timestamps for each produced caption based on the subtitles. In this way, we obtain human-style video captions at scale without human supervision. We apply our method to the subtitles of the HowTo100M dataset, creating a new large-scale dataset, HowToCaption. Our evaluation shows that the resulting captions not only significantly improve the performance over many different benchmark datasets for text-video retrieval but also lead to a disentangling of textual narration from the audio, boosting performance in text-video-audio tasks.
In-Style: Bridging Text and Uncurated Videos with Style Transfer for Text-Video Retrieval
Sep 16, 2023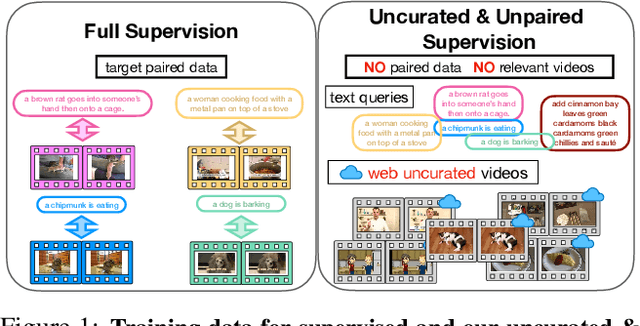

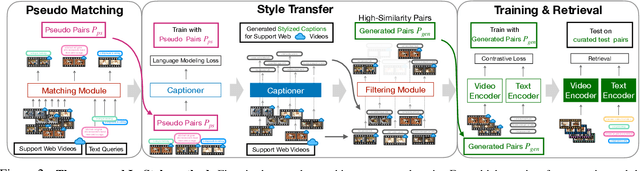
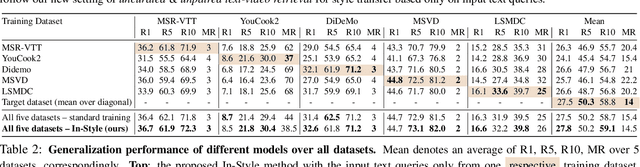
Large-scale noisy web image-text datasets have been proven to be efficient for learning robust vision-language models. However, when transferring them to the task of video retrieval, models still need to be fine-tuned on hand-curated paired text-video data to adapt to the diverse styles of video descriptions. To address this problem without the need for hand-annotated pairs, we propose a new setting, text-video retrieval with uncurated & unpaired data, that during training utilizes only text queries together with uncurated web videos without any paired text-video data. To this end, we propose an approach, In-Style, that learns the style of the text queries and transfers it to uncurated web videos. Moreover, to improve generalization, we show that one model can be trained with multiple text styles. To this end, we introduce a multi-style contrastive training procedure that improves the generalizability over several datasets simultaneously. We evaluate our model on retrieval performance over multiple datasets to demonstrate the advantages of our style transfer framework on the new task of uncurated & unpaired text-video retrieval and improve state-of-the-art performance on zero-shot text-video retrieval.
Preserving Modality Structure Improves Multi-Modal Learning
Aug 24, 2023



Self-supervised learning on large-scale multi-modal datasets allows learning semantically meaningful embeddings in a joint multi-modal representation space without relying on human annotations. These joint embeddings enable zero-shot cross-modal tasks like retrieval and classification. However, these methods often struggle to generalize well on out-of-domain data as they ignore the semantic structure present in modality-specific embeddings. In this context, we propose a novel Semantic-Structure-Preserving Consistency approach to improve generalizability by preserving the modality-specific relationships in the joint embedding space. To capture modality-specific semantic relationships between samples, we propose to learn multiple anchors and represent the multifaceted relationship between samples with respect to their relationship with these anchors. To assign multiple anchors to each sample, we propose a novel Multi-Assignment Sinkhorn-Knopp algorithm. Our experimentation demonstrates that our proposed approach learns semantically meaningful anchors in a self-supervised manner. Furthermore, our evaluation on MSR-VTT and YouCook2 datasets demonstrates that our proposed multi-anchor assignment based solution achieves state-of-the-art performance and generalizes to both inand out-of-domain datasets. Code: https://github.com/Swetha5/Multi_Sinkhorn_Knopp
What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
MAtch, eXpand and Improve: Unsupervised Finetuning for Zero-Shot Action Recognition with Language Knowledge
Mar 15, 2023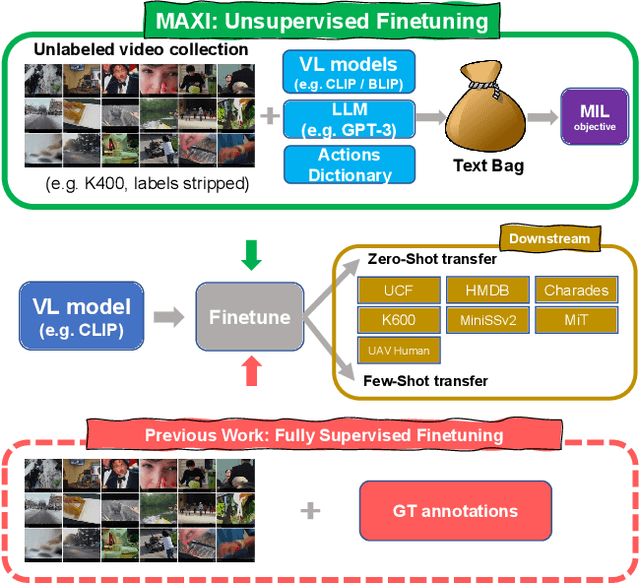
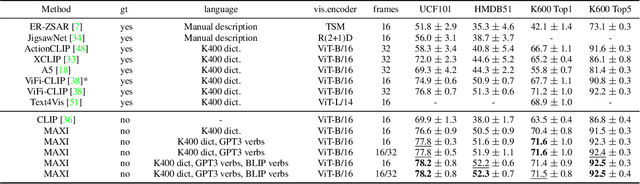
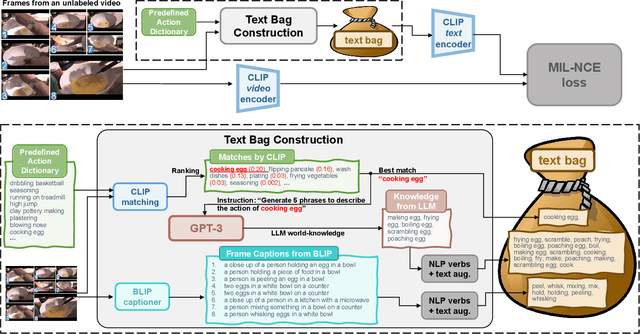

Large scale Vision-Language (VL) models have shown tremendous success in aligning representations between visual and text modalities. This enables remarkable progress in zero-shot recognition, image generation & editing, and many other exciting tasks. However, VL models tend to over-represent objects while paying much less attention to verbs, and require additional tuning on video data for best zero-shot action recognition performance. While previous work relied on large-scale, fully-annotated data, in this work we propose an unsupervised approach. We adapt a VL model for zero-shot and few-shot action recognition using a collection of unlabeled videos and an unpaired action dictionary. Based on that, we leverage Large Language Models and VL models to build a text bag for each unlabeled video via matching, text expansion and captioning. We use those bags in a Multiple Instance Learning setup to adapt an image-text backbone to video data. Although finetuned on unlabeled video data, our resulting models demonstrate high transferability to numerous unseen zero-shot downstream tasks, improving the base VL model performance by up to 14\%, and even comparing favorably to fully-supervised baselines in both zero-shot and few-shot video recognition transfer. The code will be released later at \url{https://github.com/wlin-at/MAXI}.
Learning by Sorting: Self-supervised Learning with Group Ordering Constraints
Jan 05, 2023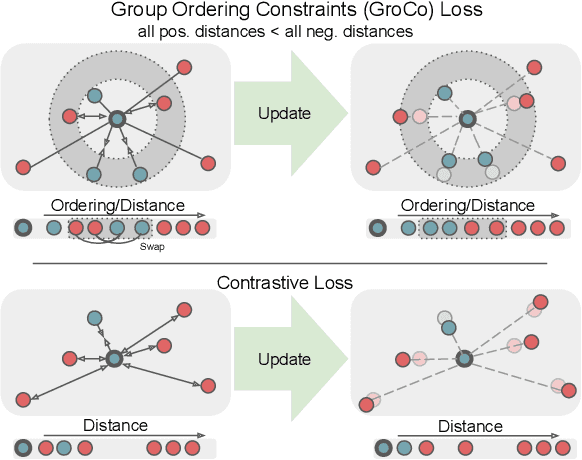
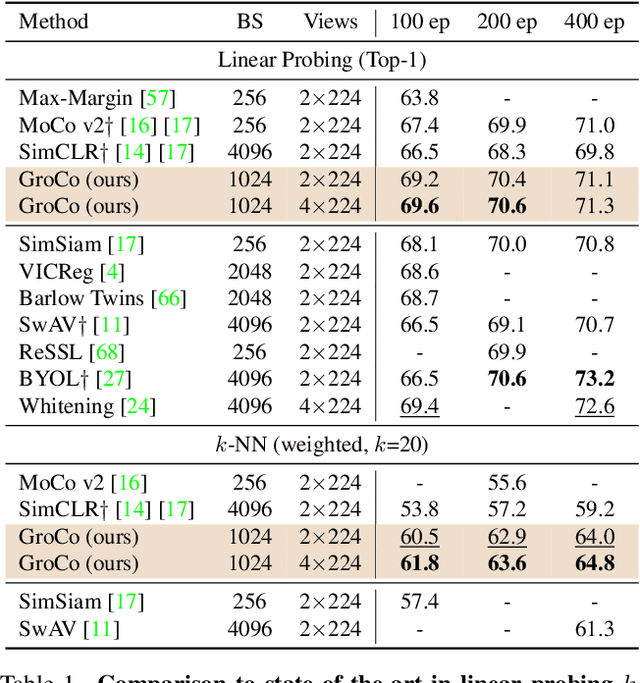
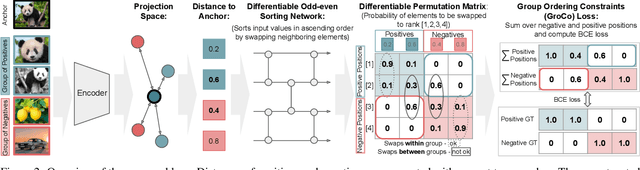
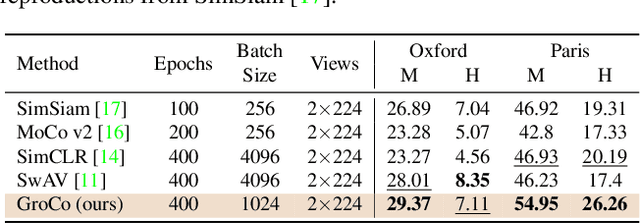
Contrastive learning has become a prominent ingredient in learning representations from unlabeled data. However, existing methods primarily consider pairwise relations. This paper proposes a new approach towards self-supervised contrastive learning based on Group Ordering Constraints (GroCo). The GroCo loss leverages the idea of comparing groups of positive and negative images instead of pairs of images. Building on the recent success of differentiable sorting algorithms, group ordering constraints enforce that the distances of all positive samples (a positive group) are smaller than the distances of all negative images (a negative group); thus, enforcing positive samples to gather around an anchor. This leads to a more holistic optimization of the local neighborhoods. We evaluate the proposed setting on a suite of competitive self-supervised learning benchmarks and show that our method is not only competitive to current methods in the case of linear probing but also leads to higher consistency in local representations, as can be seen from a significantly improved k-NN performance across all benchmarks.
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022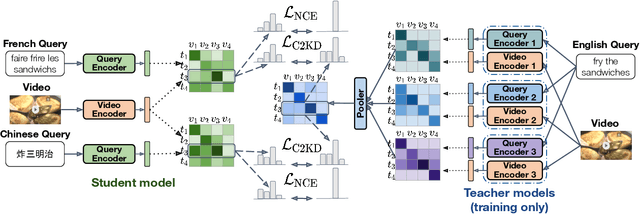
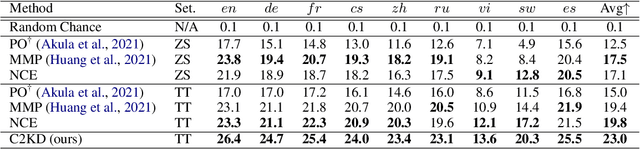

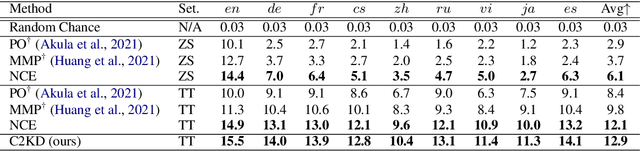
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.