 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Instance Priors Help Weakly Supervised Semantic Segmentation?
Apr 13, 2026Semantic segmentation requires dense pixel-level annotations, which are costly and time-consuming to acquire. To address this, we present SeSAM, a framework that uses a foundational segmentation model, i.e. Segment Anything Model (SAM), with weak labels, including coarse masks, scribbles, and points. SAM, originally designed for instance-based segmentation, cannot be directly used for semantic segmentation tasks. In this work, we identify specific challenges faced by SAM and determine appropriate components to adapt it for class-based segmentation using weak labels. Specifically, SeSAM decomposes class masks into connected components, samples point prompts along object skeletons, selects SAM masks using weak-label coverage, and iteratively refines labels using pseudo-labels, enabling SAM-generated masks to be effectively used for semantic segmentation. Integrated with a semi-supervised learning framework, SeSAM balances ground-truth labels, SAM-based pseudo-labels, and high-confidence pseudo-labels, significantly improving segmentation quality. Extensive experiments across multiple benchmarks and weak annotation types show that SeSAM consistently outperforms weakly supervised baselines while substantially reducing annotation cost relative to fine supervision.
TTA-Vid: Generalized Test-Time Adaptation for Video Reasoning
Apr 01, 2026Recent video reasoning models have shown strong results on temporal and multimodal understanding, yet they depend on large-scale supervised data and multi-stage training pipelines, making them costly to train and difficult to adapt to new domains. In this work, we leverage the paradigm of Test-Time Reinforcement Learning on video-language data to allow for adapting a pretrained model to incoming video samples at test-time without explicit labels. The proposed test-time adaptation for video approach (TTA-Vid) combines two components that work simultaneously: (1) a test-time adaptation that performs step-by-step reasoning at inference time on multiple frame subsets. We then use a batch-aware frequency-based reward computed across different frame subsets as pseudo ground truth to update the model. It shows that the resulting model trained on a single batch or even a single sample from a dataset, is able to generalize at test-time to the whole dataset and even across datasets. Because the adaptation occurs entirely at test time, our method requires no ground-truth annotations or dedicated training splits. Additionally, we propose a multi-armed bandit strategy for adaptive frame selection that learns to prioritize informative frames, guided by the same reward formulation. Our evaluation shows that TTA-Vid yields consistent improvements across various video reasoning tasks and is able to outperform current state-of-the-art methods trained on large-scale data. This highlights the potential of test-time reinforcement learning for temporal multimodal understanding.
MM-TS: Multi-Modal Temperature and Margin Schedules for Contrastive Learning with Long-Tail Data
Mar 09, 2026Contrastive learning has become a fundamental approach in both uni-modal and multi-modal frameworks. This learning paradigm pulls positive pairs of samples closer while pushing negatives apart. In the uni-modal setting (e.g., image-based learning), previous research has shown that the strength of these forces can be controlled through the temperature parameter. In this work, we propose Multi-Modal Temperature and Margin Schedules (MM-TS), extending the concept of uni-modal temperature scheduling to multi-modal contrastive learning. Our method dynamically adjusts the temperature in the contrastive loss during training, modulating the attraction and repulsion forces in the multi-modal setting. Additionally, recognizing that standard multi-modal datasets often follow imbalanced, long-tail distributions, we adapt the temperature based on the local distribution of each training sample. Specifically, samples from dense clusters are assigned a higher temperature to better preserve their semantic structure. Furthermore, we demonstrate that temperature scheduling can be effectively integrated within a max-margin framework, thereby unifying the two predominant approaches in multi-modal contrastive learning: InfoNCE loss and max-margin objective. We evaluate our approach on four widely used image- and video-language datasets, Flickr30K, MSCOCO, EPIC-KITCHENS-100, and YouCook2, and show that our dynamic temperature and margin schedules improve performance and lead to new state-of-the-art results in the field.
When LLaVA Meets Objects: Token Composition for Vision-Language-Models
Feb 04, 2026Current autoregressive Vision Language Models (VLMs) usually rely on a large number of visual tokens to represent images, resulting in a need for more compute especially at inference time. To address this problem, we propose Mask-LLaVA, a framework that leverages different levels of visual features to create a compact yet information-rich visual representation for autoregressive VLMs. Namely, we combine mask-based object representations together with global tokens and local patch tokens. While all tokens are used during training, it shows that the resulting model can flexibly drop especially the number of mask-based object-tokens at test time, allowing to adapt the number of tokens during inference without the need to retrain the model and without a significant drop in performance. We evaluate the proposed approach on a suite of standard benchmarks showing results competitive to current token efficient methods and comparable to the original LLaVA baseline using only a fraction of visual tokens. Our analysis demonstrates that combining multi-level features enables efficient learning with fewer tokens while allowing dynamic token selection at test time for good performance.
RefAM: Attention Magnets for Zero-Shot Referral Segmentation
Sep 26, 2025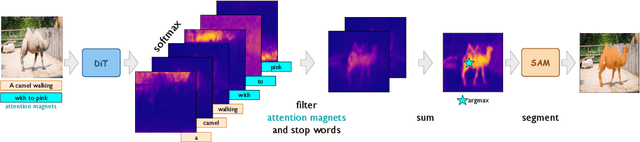
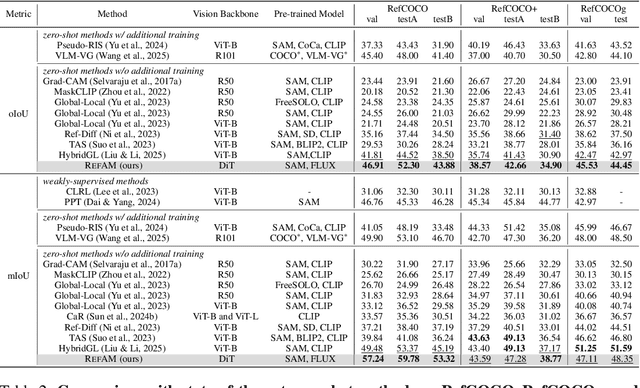

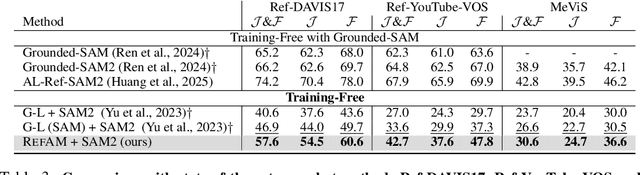
Most existing approaches to referring segmentation achieve strong performance only through fine-tuning or by composing multiple pre-trained models, often at the cost of additional training and architectural modifications. Meanwhile, large-scale generative diffusion models encode rich semantic information, making them attractive as general-purpose feature extractors. In this work, we introduce a new method that directly exploits features, attention scores, from diffusion transformers for downstream tasks, requiring neither architectural modifications nor additional training. To systematically evaluate these features, we extend benchmarks with vision-language grounding tasks spanning both images and videos. Our key insight is that stop words act as attention magnets: they accumulate surplus attention and can be filtered to reduce noise. Moreover, we identify global attention sinks (GAS) emerging in deeper layers and show that they can be safely suppressed or redirected onto auxiliary tokens, leading to sharper and more accurate grounding maps. We further propose an attention redistribution strategy, where appended stop words partition background activations into smaller clusters, yielding sharper and more localized heatmaps. Building on these findings, we develop RefAM, a simple training-free grounding framework that combines cross-attention maps, GAS handling, and redistribution. Across zero-shot referring image and video segmentation benchmarks, our approach consistently outperforms prior methods, establishing a new state of the art without fine-tuning or additional components.
VideoGEM: Training-free Action Grounding in Videos
Mar 26, 2025



Vision-language foundation models have shown impressive capabilities across various zero-shot tasks, including training-free localization and grounding, primarily focusing on localizing objects in images. However, leveraging those capabilities to localize actions and events in videos is challenging, as actions have less physical outline and are usually described by higher-level concepts. In this work, we propose VideoGEM, the first training-free spatial action grounding method based on pretrained image- and video-language backbones. Namely, we adapt the self-self attention formulation of GEM to spatial activity grounding. We observe that high-level semantic concepts, such as actions, usually emerge in the higher layers of the image- and video-language models. We, therefore, propose a layer weighting in the self-attention path to prioritize higher layers. Additionally, we introduce a dynamic weighting method to automatically tune layer weights to capture each layer`s relevance to a specific prompt. Finally, we introduce a prompt decomposition, processing action, verb, and object prompts separately, resulting in a better spatial localization of actions. We evaluate the proposed approach on three image- and video-language backbones, CLIP, OpenCLIP, and ViCLIP, and on four video grounding datasets, V-HICO, DALY, YouCook-Interactions, and GroundingYouTube, showing that the proposed training-free approach is able to outperform current trained state-of-the-art approaches for spatial video grounding.
T-FAKE: Synthesizing Thermal Images for Facial Landmarking
Aug 27, 2024
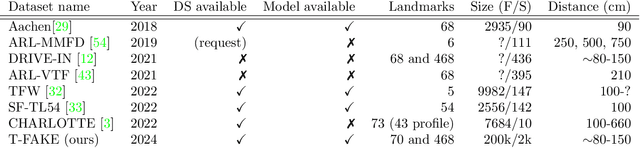

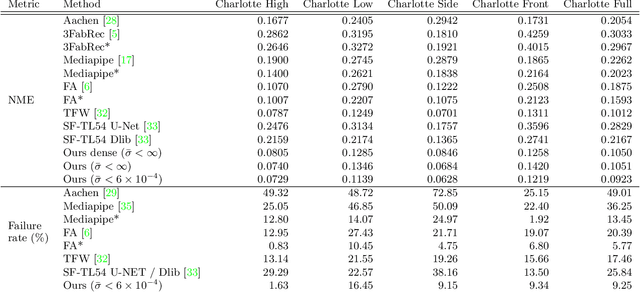
Facial analysis is a key component in a wide range of applications such as security, autonomous driving, entertainment, and healthcare. Despite the availability of various facial RGB datasets, the thermal modality, which plays a crucial role in life sciences, medicine, and biometrics, has been largely overlooked. To address this gap, we introduce the T-FAKE dataset, a new large-scale synthetic thermal dataset with sparse and dense landmarks. To facilitate the creation of the dataset, we propose a novel RGB2Thermal loss function, which enables the transfer of thermal style to RGB faces. By utilizing the Wasserstein distance between thermal and RGB patches and the statistical analysis of clinical temperature distributions on faces, we ensure that the generated thermal images closely resemble real samples. Using RGB2Thermal style transfer based on our RGB2Thermal loss function, we create the T-FAKE dataset, a large-scale synthetic thermal dataset of faces. Leveraging our novel T-FAKE dataset, probabilistic landmark prediction, and label adaptation networks, we demonstrate significant improvements in landmark detection methods on thermal images across different landmark conventions. Our models show excellent performance with both sparse 70-point landmarks and dense 478-point landmark annotations. Our code and models are available at https://github.com/phflot/tfake.
X-MIC: Cross-Modal Instance Conditioning for Egocentric Action Generalization
Mar 28, 2024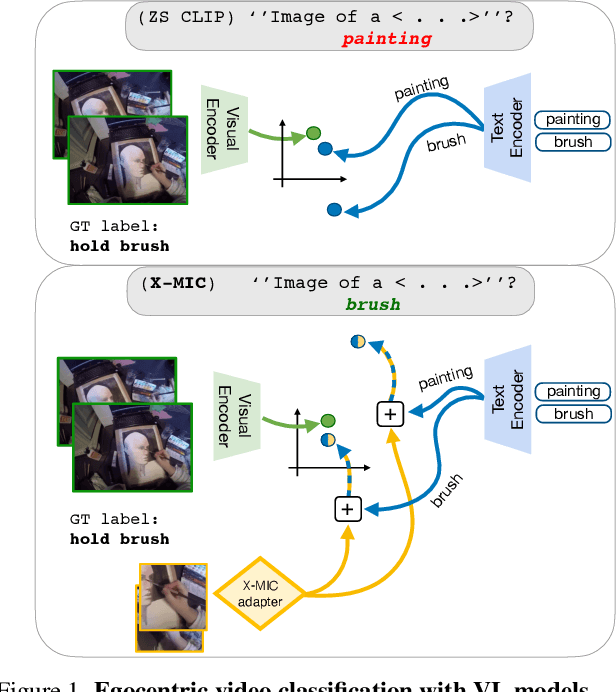
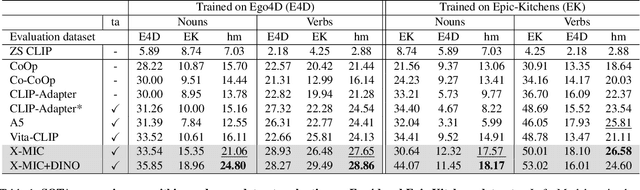
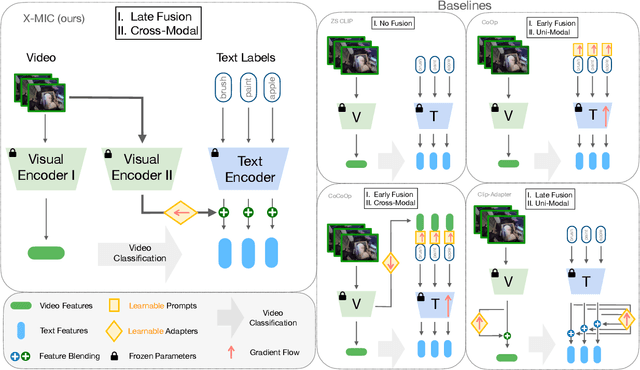
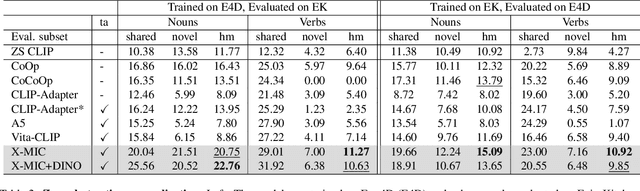
Lately, there has been growing interest in adapting vision-language models (VLMs) to image and third-person video classification due to their success in zero-shot recognition. However, the adaptation of these models to egocentric videos has been largely unexplored. To address this gap, we propose a simple yet effective cross-modal adaptation framework, which we call X-MIC. Using a video adapter, our pipeline learns to align frozen text embeddings to each egocentric video directly in the shared embedding space. Our novel adapter architecture retains and improves generalization of the pre-trained VLMs by disentangling learnable temporal modeling and frozen visual encoder. This results in an enhanced alignment of text embeddings to each egocentric video, leading to a significant improvement in cross-dataset generalization. We evaluate our approach on the Epic-Kitchens, Ego4D, and EGTEA datasets for fine-grained cross-dataset action generalization, demonstrating the effectiveness of our method. Code is available at https://github.com/annusha/xmic
OrCo: Towards Better Generalization via Orthogonality and Contrast for Few-Shot Class-Incremental Learning
Mar 27, 2024Few-Shot Class-Incremental Learning (FSCIL) introduces a paradigm in which the problem space expands with limited data. FSCIL methods inherently face the challenge of catastrophic forgetting as data arrives incrementally, making models susceptible to overwriting previously acquired knowledge. Moreover, given the scarcity of labeled samples available at any given time, models may be prone to overfitting and find it challenging to strike a balance between extensive pretraining and the limited incremental data. To address these challenges, we propose the OrCo framework built on two core principles: features' orthogonality in the representation space, and contrastive learning. In particular, we improve the generalization of the embedding space by employing a combination of supervised and self-supervised contrastive losses during the pretraining phase. Additionally, we introduce OrCo loss to address challenges arising from data limitations during incremental sessions. Through feature space perturbations and orthogonality between classes, the OrCo loss maximizes margins and reserves space for the following incremental data. This, in turn, ensures the accommodation of incoming classes in the feature space without compromising previously acquired knowledge. Our experimental results showcase state-of-the-art performance across three benchmark datasets, including mini-ImageNet, CIFAR100, and CUB datasets. Code is available at https://github.com/noorahmedds/OrCo
SSB: Simple but Strong Baseline for Boosting Performance of Open-Set Semi-Supervised Learning
Nov 17, 2023



Semi-supervised learning (SSL) methods effectively leverage unlabeled data to improve model generalization. However, SSL models often underperform in open-set scenarios, where unlabeled data contain outliers from novel categories that do not appear in the labeled set. In this paper, we study the challenging and realistic open-set SSL setting, where the goal is to both correctly classify inliers and to detect outliers. Intuitively, the inlier classifier should be trained on inlier data only. However, we find that inlier classification performance can be largely improved by incorporating high-confidence pseudo-labeled data, regardless of whether they are inliers or outliers. Also, we propose to utilize non-linear transformations to separate the features used for inlier classification and outlier detection in the multi-task learning framework, preventing adverse effects between them. Additionally, we introduce pseudo-negative mining, which further boosts outlier detection performance. The three ingredients lead to what we call Simple but Strong Baseline (SSB) for open-set SSL. In experiments, SSB greatly improves both inlier classification and outlier detection performance, outperforming existing methods by a large margin. Our code will be released at https://github.com/YUE-FAN/SSB.