 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAEC: Unsupervised Action Segmentation with Temporal-Aware Embedding and Clustering
Paper and Code
Mar 09, 2023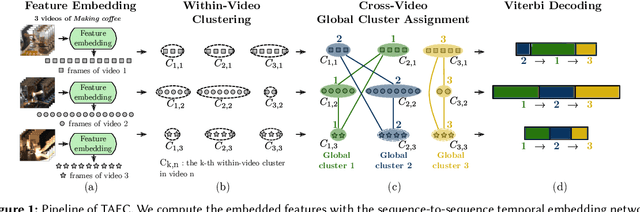
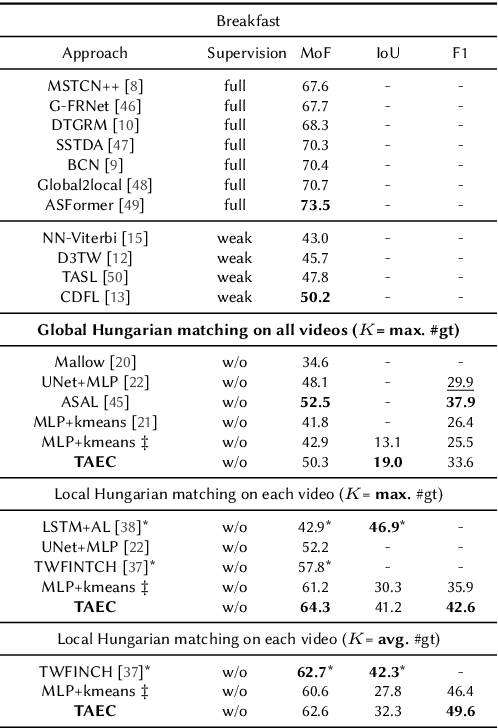
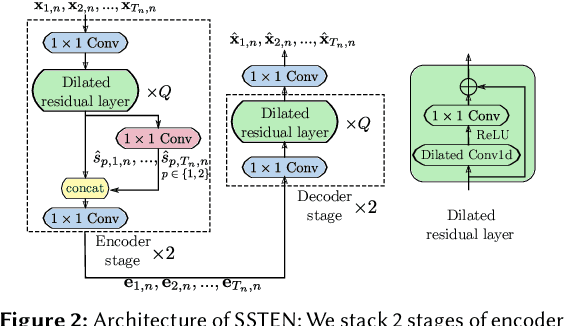
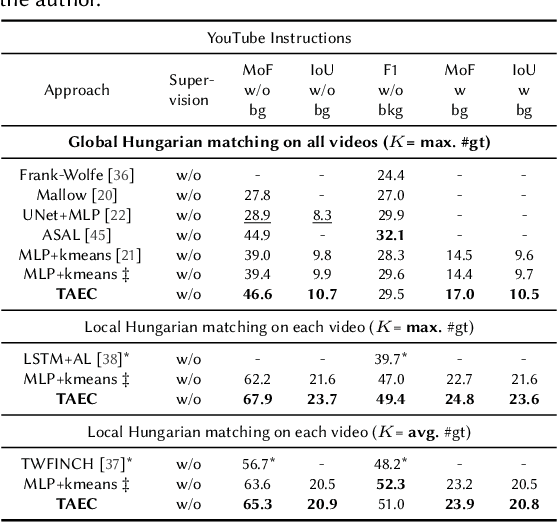
Temporal action segmentation in untrimmed videos has gained increased attention recently. However, annotating action classes and frame-wise boundaries is extremely time consuming and cost intensive, especially on large-scale datasets. To address this issue, we propose an unsupervised approach for learning action classes from untrimmed video sequences. In particular, we propose a temporal embedding network that combines relative time prediction, feature reconstruction, and sequence-to-sequence learning, to preserve the spatial layout and sequential nature of the video features. A two-step clustering pipeline on these embedded feature representations then allows us to enforce temporal consistency within, as well as across videos. Based on the identified clusters, we decode the video into coherent temporal segments that correspond to semantically meaningful action classes. Our evaluation on three challenging datasets shows the impact of each component and, furthermore, demonstrates our state-of-the-art unsupervised action segmentation results.