 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Rank: Visual Attribution by Learning Importance Ranking
Apr 07, 2026Interpreting the decisions of complex computer vision models is crucial to establish trust and accountability, especially in safety-critical domains. An established approach to interpretability is generating visual attribution maps that highlight regions of the input most relevant to the model's prediction. However, existing methods face a three-way trade-off. Propagation-based approaches are efficient, but they can be biased and architecture-specific. Meanwhile, perturbation-based methods are causally grounded, yet they are expensive and for vision transformers often yield coarse, patch-level explanations. Learning-based explainers are fast but usually optimize surrogate objectives or distill from heuristic teachers. We propose a learning scheme that instead optimizes deletion and insertion metrics directly. Since these metrics depend on non-differentiable sorting and ranking, we frame them as permutation learning and replace the hard sorting with a differentiable relaxation using Gumbel-Sinkhorn. This enables end-to-end training through attribution-guided perturbations of the target model. During inference, our method produces dense, pixel-level attributions in a single forward pass with optional, few-step gradient refinement. Our experiments demonstrate consistent quantitative improvements and sharper, boundary-aligned explanations, particularly for transformer-based vision models.
SHARP: Short-Window Streaming for Accurate and Robust Prediction in Motion Forecasting
Mar 30, 2026In dynamic traffic environments, motion forecasting models must be able to accurately estimate future trajectories continuously. Streaming-based methods are a promising solution, but despite recent advances, their performance often degrades when exposed to heterogeneous observation lengths. To address this, we propose a novel streaming-based motion forecasting framework that explicitly focuses on evolving scenes. Our method incrementally processes incoming observation windows and leverages an instance-aware context streaming to maintain and update latent agent representations across inference steps. A dual training objective further enables consistent forecasting accuracy across diverse observation horizons. Extensive experiments on Argoverse 2, nuScenes, and Argoverse 1 demonstrate the robustness of our approach under evolving scene conditions and also on the single-agent benchmarks. Our model achieves state-of-the-art performance in streaming inference on the Argoverse 2 multi-agent benchmark, while maintaining minimal latency, highlighting its suitability for real-world deployment.
ASCENT: Transformer-Based Aircraft Trajectory Prediction in Non-Towered Terminal Airspace
Mar 17, 2026Accurate trajectory prediction can improve General Aviation safety in non-towered terminal airspace, where high traffic density increases accident risk. We present ASCENT, a lightweight transformer-based model for multi-modal 3D aircraft trajectory forecasting, which integrates domain-aware 3D coordinate normalization and parameterized predictions. ASCENT employs a transformer-based motion encoder and a query-based decoder, enabling the generation of diverse maneuver hypotheses with low latency. Experiments on the TrajAir and TartanAviation datasets demonstrate that our model outperforms prior baselines, as the encoder effectively captures motion dynamics and the decoder aligns with structured aircraft traffic patterns. Furthermore, ablation studies confirm the contributions of the decoder design, coordinate-frame modeling, and parameterized outputs. These results establish ASCENT as an effective approach for real-time aircraft trajectory prediction in non-towered terminal airspace.
Streaming Real-Time Trajectory Prediction Using Endpoint-Aware Modeling
Mar 02, 2026Future trajectories of neighboring traffic agents have a significant influence on the path planning and decision-making of autonomous vehicles. While trajectory forecasting is a well-studied field, research mainly focuses on snapshot-based prediction, where each scenario is treated independently of its global temporal context. However, real-world autonomous driving systems need to operate in a continuous setting, requiring real-time processing of data streams with low latency and consistent predictions over successive timesteps. We leverage this continuous setting to propose a lightweight yet highly accurate streaming-based trajectory forecasting approach. We integrate valuable information from previous predictions with a novel endpoint-aware modeling scheme. Our temporal context propagation uses the trajectory endpoints of the previous forecasts as anchors to extract targeted scenario context encodings. Our approach efficiently guides its scene encoder to extract highly relevant context information without needing refinement iterations or segment-wise decoding. Our experiments highlight that our approach effectively relays information across consecutive timesteps. Unlike methods using multi-stage refinement processing, our approach significantly reduces inference latency, making it well-suited for real-world deployment. We achieve state-of-the-art streaming trajectory prediction results on the Argoverse~2 multi-agent and single-agent benchmarks, while requiring substantially fewer resources.
One Model, Many Behaviors: Training-Induced Effects on Out-of-Distribution Detection
Jan 15, 2026Out-of-distribution (OOD) detection is crucial for deploying robust and reliable machine-learning systems in open-world settings. Despite steady advances in OOD detectors, their interplay with modern training pipelines that maximize in-distribution (ID) accuracy and generalization remains under-explored. We investigate this link through a comprehensive empirical study. Fixing the architecture to the widely adopted ResNet-50, we benchmark 21 post-hoc, state-of-the-art OOD detection methods across 56 ImageNet-trained models obtained via diverse training strategies and evaluate them on eight OOD test sets. Contrary to the common assumption that higher ID accuracy implies better OOD detection performance, we uncover a non-monotonic relationship: OOD performance initially improves with accuracy but declines once advanced training recipes push accuracy beyond the baseline. Moreover, we observe a strong interdependence between training strategy, detector choice, and resulting OOD performance, indicating that no single method is universally optimal.
ICONIC-444: A 3.1-Million-Image Dataset for OOD Detection Research
Jan 15, 2026Current progress in out-of-distribution (OOD) detection is limited by the lack of large, high-quality datasets with clearly defined OOD categories across varying difficulty levels (near- to far-OOD) that support both fine- and coarse-grained computer vision tasks. To address this limitation, we introduce ICONIC-444 (Image Classification and OOD Detection with Numerous Intricate Complexities), a specialized large-scale industrial image dataset containing over 3.1 million RGB images spanning 444 classes tailored for OOD detection research. Captured with a prototype industrial sorting machine, ICONIC-444 closely mimics real-world tasks. It complements existing datasets by offering structured, diverse data suited for rigorous OOD evaluation across a spectrum of task complexities. We define four reference tasks within ICONIC-444 to benchmark and advance OOD detection research and provide baseline results for 22 state-of-the-art post-hoc OOD detection methods.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
STSBench: A Spatio-temporal Scenario Benchmark for Multi-modal Large Language Models in Autonomous Driving
Jun 06, 2025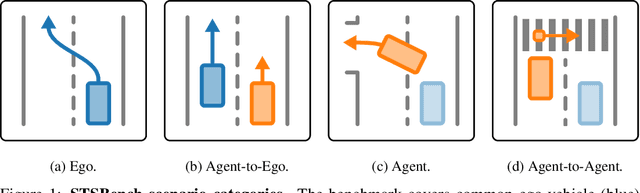
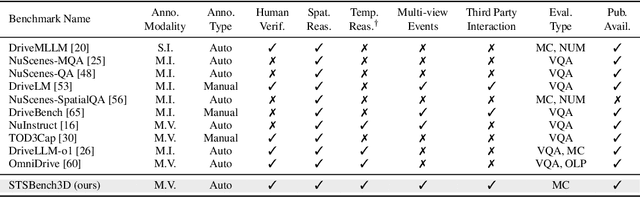
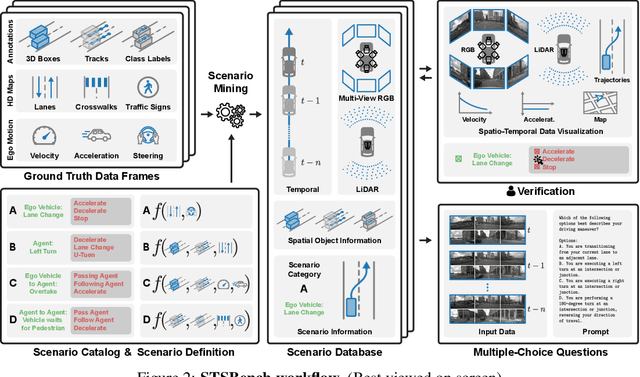
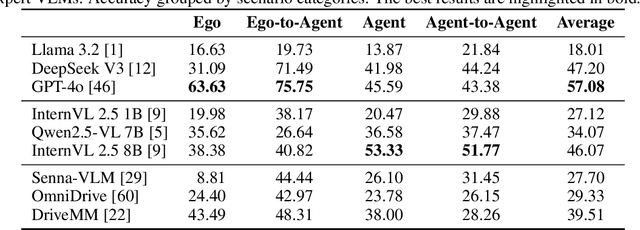
We introduce STSBench, a scenario-based framework to benchmark the holistic understanding of vision-language models (VLMs) for autonomous driving. The framework automatically mines pre-defined traffic scenarios from any dataset using ground-truth annotations, provides an intuitive user interface for efficient human verification, and generates multiple-choice questions for model evaluation. Applied to the NuScenes dataset, we present STSnu, the first benchmark that evaluates the spatio-temporal reasoning capabilities of VLMs based on comprehensive 3D perception. Existing benchmarks typically target off-the-shelf or fine-tuned VLMs for images or videos from a single viewpoint and focus on semantic tasks such as object recognition, dense captioning, risk assessment, or scene understanding. In contrast, STSnu evaluates driving expert VLMs for end-to-end driving, operating on videos from multi-view cameras or LiDAR. It specifically assesses their ability to reason about both ego-vehicle actions and complex interactions among traffic participants, a crucial capability for autonomous vehicles. The benchmark features 43 diverse scenarios spanning multiple views and frames, resulting in 971 human-verified multiple-choice questions. A thorough evaluation uncovers critical shortcomings in existing models' ability to reason about fundamental traffic dynamics in complex environments. These findings highlight the urgent need for architectural advances that explicitly model spatio-temporal reasoning. By addressing a core gap in spatio-temporal evaluation, STSBench enables the development of more robust and explainable VLMs for autonomous driving.
Exploring Modality Guidance to Enhance VFM-based Feature Fusion for UDA in 3D Semantic Segmentation
Apr 19, 2025Vision Foundation Models (VFMs) have become a de facto choice for many downstream vision tasks, like image classification, image segmentation, and object localization. However, they can also provide significant utility for downstream 3D tasks that can leverage the cross-modal information (e.g., from paired image data). In our work, we further explore the utility of VFMs for adapting from a labeled source to unlabeled target data for the task of LiDAR-based 3D semantic segmentation. Our method consumes paired 2D-3D (image and point cloud) data and relies on the robust (cross-domain) features from a VFM to train a 3D backbone on a mix of labeled source and unlabeled target data. At the heart of our method lies a fusion network that is guided by both the image and point cloud streams, with their relative contributions adjusted based on the target domain. We extensively compare our proposed methodology with different state-of-the-art methods in several settings and achieve strong performance gains. For example, achieving an average improvement of 6.5 mIoU (over all tasks), when compared with the previous state-of-the-art.
LiSu: A Dataset and Method for LiDAR Surface Normal Estimation
Mar 11, 2025
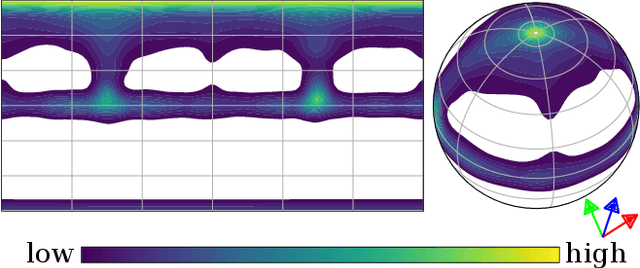


While surface normals are widely used to analyse 3D scene geometry, surface normal estimation from LiDAR point clouds remains severely underexplored. This is caused by the lack of large-scale annotated datasets on the one hand, and lack of methods that can robustly handle the sparse and often noisy LiDAR data in a reasonable time on the other hand. We address these limitations using a traffic simulation engine and present LiSu, the first large-scale, synthetic LiDAR point cloud dataset with ground truth surface normal annotations, eliminating the need for tedious manual labeling. Additionally, we propose a novel method that exploits the spatiotemporal characteristics of autonomous driving data to enhance surface normal estimation accuracy. By incorporating two regularization terms, we enforce spatial consistency among neighboring points and temporal smoothness across consecutive LiDAR frames. These regularizers are particularly effective in self-training settings, where they mitigate the impact of noisy pseudo-labels, enabling robust real-world deployment. We demonstrate the effectiveness of our method on LiSu, achieving state-of-the-art performance in LiDAR surface normal estimation. Moreover, we showcase its full potential in addressing the challenging task of synthetic-to-real domain adaptation, leading to improved neural surface reconstruction on real-world data.