 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Rank: Visual Attribution by Learning Importance Ranking
Apr 07, 2026Interpreting the decisions of complex computer vision models is crucial to establish trust and accountability, especially in safety-critical domains. An established approach to interpretability is generating visual attribution maps that highlight regions of the input most relevant to the model's prediction. However, existing methods face a three-way trade-off. Propagation-based approaches are efficient, but they can be biased and architecture-specific. Meanwhile, perturbation-based methods are causally grounded, yet they are expensive and for vision transformers often yield coarse, patch-level explanations. Learning-based explainers are fast but usually optimize surrogate objectives or distill from heuristic teachers. We propose a learning scheme that instead optimizes deletion and insertion metrics directly. Since these metrics depend on non-differentiable sorting and ranking, we frame them as permutation learning and replace the hard sorting with a differentiable relaxation using Gumbel-Sinkhorn. This enables end-to-end training through attribution-guided perturbations of the target model. During inference, our method produces dense, pixel-level attributions in a single forward pass with optional, few-step gradient refinement. Our experiments demonstrate consistent quantitative improvements and sharper, boundary-aligned explanations, particularly for transformer-based vision models.
SHARP: Short-Window Streaming for Accurate and Robust Prediction in Motion Forecasting
Mar 30, 2026In dynamic traffic environments, motion forecasting models must be able to accurately estimate future trajectories continuously. Streaming-based methods are a promising solution, but despite recent advances, their performance often degrades when exposed to heterogeneous observation lengths. To address this, we propose a novel streaming-based motion forecasting framework that explicitly focuses on evolving scenes. Our method incrementally processes incoming observation windows and leverages an instance-aware context streaming to maintain and update latent agent representations across inference steps. A dual training objective further enables consistent forecasting accuracy across diverse observation horizons. Extensive experiments on Argoverse 2, nuScenes, and Argoverse 1 demonstrate the robustness of our approach under evolving scene conditions and also on the single-agent benchmarks. Our model achieves state-of-the-art performance in streaming inference on the Argoverse 2 multi-agent benchmark, while maintaining minimal latency, highlighting its suitability for real-world deployment.
ASCENT: Transformer-Based Aircraft Trajectory Prediction in Non-Towered Terminal Airspace
Mar 17, 2026Accurate trajectory prediction can improve General Aviation safety in non-towered terminal airspace, where high traffic density increases accident risk. We present ASCENT, a lightweight transformer-based model for multi-modal 3D aircraft trajectory forecasting, which integrates domain-aware 3D coordinate normalization and parameterized predictions. ASCENT employs a transformer-based motion encoder and a query-based decoder, enabling the generation of diverse maneuver hypotheses with low latency. Experiments on the TrajAir and TartanAviation datasets demonstrate that our model outperforms prior baselines, as the encoder effectively captures motion dynamics and the decoder aligns with structured aircraft traffic patterns. Furthermore, ablation studies confirm the contributions of the decoder design, coordinate-frame modeling, and parameterized outputs. These results establish ASCENT as an effective approach for real-time aircraft trajectory prediction in non-towered terminal airspace.
Streaming Real-Time Trajectory Prediction Using Endpoint-Aware Modeling
Mar 02, 2026Future trajectories of neighboring traffic agents have a significant influence on the path planning and decision-making of autonomous vehicles. While trajectory forecasting is a well-studied field, research mainly focuses on snapshot-based prediction, where each scenario is treated independently of its global temporal context. However, real-world autonomous driving systems need to operate in a continuous setting, requiring real-time processing of data streams with low latency and consistent predictions over successive timesteps. We leverage this continuous setting to propose a lightweight yet highly accurate streaming-based trajectory forecasting approach. We integrate valuable information from previous predictions with a novel endpoint-aware modeling scheme. Our temporal context propagation uses the trajectory endpoints of the previous forecasts as anchors to extract targeted scenario context encodings. Our approach efficiently guides its scene encoder to extract highly relevant context information without needing refinement iterations or segment-wise decoding. Our experiments highlight that our approach effectively relays information across consecutive timesteps. Unlike methods using multi-stage refinement processing, our approach significantly reduces inference latency, making it well-suited for real-world deployment. We achieve state-of-the-art streaming trajectory prediction results on the Argoverse~2 multi-agent and single-agent benchmarks, while requiring substantially fewer resources.
STSBench: A Spatio-temporal Scenario Benchmark for Multi-modal Large Language Models in Autonomous Driving
Jun 06, 2025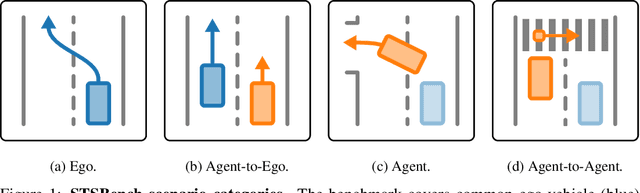
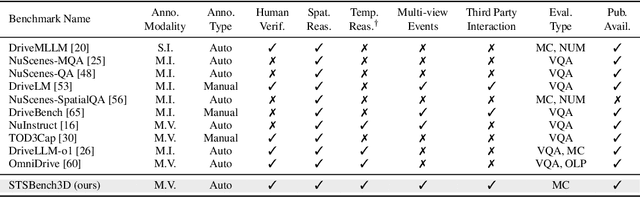
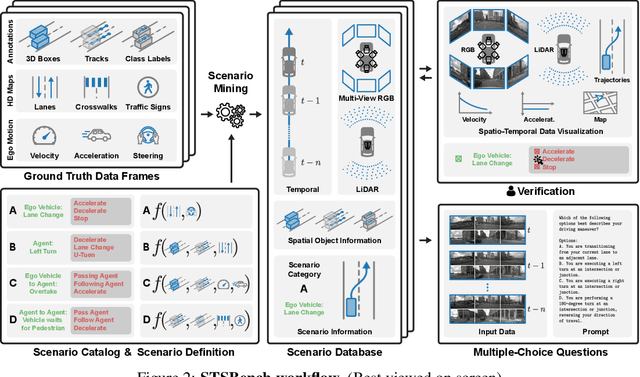
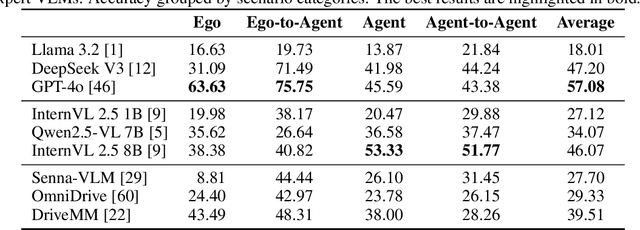
We introduce STSBench, a scenario-based framework to benchmark the holistic understanding of vision-language models (VLMs) for autonomous driving. The framework automatically mines pre-defined traffic scenarios from any dataset using ground-truth annotations, provides an intuitive user interface for efficient human verification, and generates multiple-choice questions for model evaluation. Applied to the NuScenes dataset, we present STSnu, the first benchmark that evaluates the spatio-temporal reasoning capabilities of VLMs based on comprehensive 3D perception. Existing benchmarks typically target off-the-shelf or fine-tuned VLMs for images or videos from a single viewpoint and focus on semantic tasks such as object recognition, dense captioning, risk assessment, or scene understanding. In contrast, STSnu evaluates driving expert VLMs for end-to-end driving, operating on videos from multi-view cameras or LiDAR. It specifically assesses their ability to reason about both ego-vehicle actions and complex interactions among traffic participants, a crucial capability for autonomous vehicles. The benchmark features 43 diverse scenarios spanning multiple views and frames, resulting in 971 human-verified multiple-choice questions. A thorough evaluation uncovers critical shortcomings in existing models' ability to reason about fundamental traffic dynamics in complex environments. These findings highlight the urgent need for architectural advances that explicitly model spatio-temporal reasoning. By addressing a core gap in spatio-temporal evaluation, STSBench enables the development of more robust and explainable VLMs for autonomous driving.
GACE: Geometry Aware Confidence Enhancement for Black-Box 3D Object Detectors on LiDAR-Data
Oct 31, 2023



Widely-used LiDAR-based 3D object detectors often neglect fundamental geometric information readily available from the object proposals in their confidence estimation. This is mostly due to architectural design choices, which were often adopted from the 2D image domain, where geometric context is rarely available. In 3D, however, considering the object properties and its surroundings in a holistic way is important to distinguish between true and false positive detections, e.g. occluded pedestrians in a group. To address this, we present GACE, an intuitive and highly efficient method to improve the confidence estimation of a given black-box 3D object detector. We aggregate geometric cues of detections and their spatial relationships, which enables us to properly assess their plausibility and consequently, improve the confidence estimation. This leads to consistent performance gains over a variety of state-of-the-art detectors. Across all evaluated detectors, GACE proves to be especially beneficial for the vulnerable road user classes, i.e. pedestrians and cyclists.
MAELi -- Masked Autoencoder for Large-Scale LiDAR Point Clouds
Dec 14, 2022



We show how the inherent, but often neglected, properties of large-scale LiDAR point clouds can be exploited for effective self-supervised representation learning. To this end, we design a highly data-efficient feature pre-training backbone that significantly reduces the amount of tedious 3D annotations to train state-of-the-art object detectors. In particular, we propose a Masked AutoEncoder (MAELi) that intuitively utilizes the sparsity of the LiDAR point clouds in both, the encoder and the decoder, during reconstruction. This results in more expressive and useful features, directly applicable to downstream perception tasks, such as 3D object detection for autonomous driving. In a novel reconstruction scheme, MAELi distinguishes between free and occluded space and leverages a new masking strategy which targets the LiDAR's inherent spherical projection. To demonstrate the potential of MAELi, we pre-train one of the most widespread 3D backbones, in an end-to-end fashion and show the merit of our fully unsupervised pre-trained features on several 3D object detection architectures. Given only a tiny fraction of labeled frames to fine-tune such detectors, we achieve significant performance improvements. For example, with only $\sim800$ labeled frames, MAELi features improve a SECOND model by +10.09APH/LEVEL 2 on Waymo Vehicles.
OccAM's Laser: Occlusion-based Attribution Maps for 3D Object Detectors on LiDAR Data
Apr 13, 2022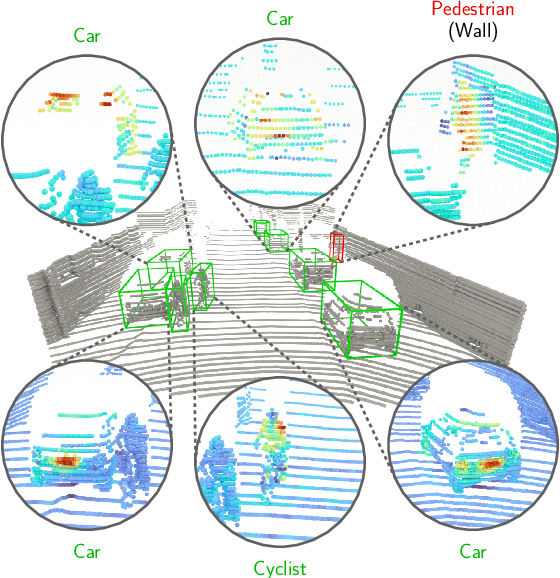
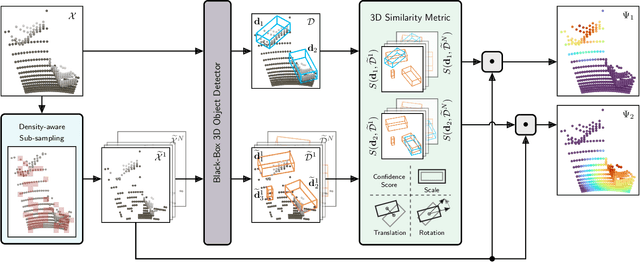
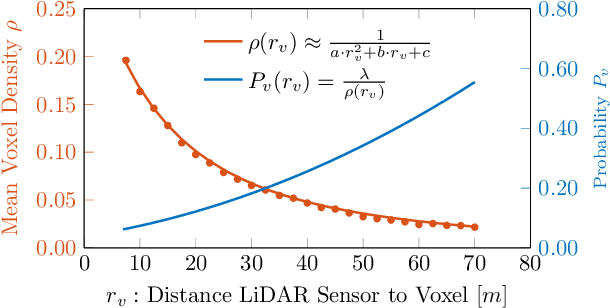
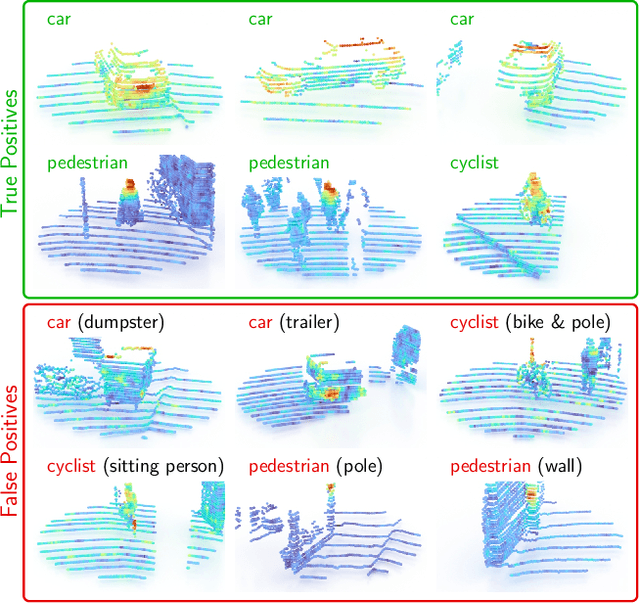
While 3D object detection in LiDAR point clouds is well-established in academia and industry, the explainability of these models is a largely unexplored field. In this paper, we propose a method to generate attribution maps for the detected objects in order to better understand the behavior of such models. These maps indicate the importance of each 3D point in predicting the specific objects. Our method works with black-box models: We do not require any prior knowledge of the architecture nor access to the model's internals, like parameters, activations or gradients. Our efficient perturbation-based approach empirically estimates the importance of each point by testing the model with randomly generated subsets of the input point cloud. Our sub-sampling strategy takes into account the special characteristics of LiDAR data, such as the depth-dependent point density. We show a detailed evaluation of the attribution maps and demonstrate that they are interpretable and highly informative. Furthermore, we compare the attribution maps of recent 3D object detection architectures to provide insights into their decision-making processes.
MURAUER: Mapping Unlabeled Real Data for Label AUstERity
Dec 05, 2018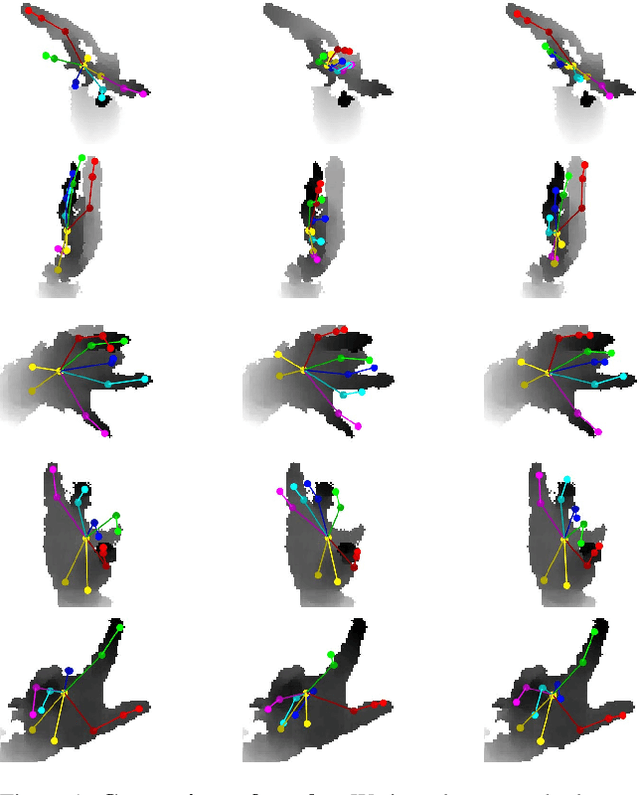
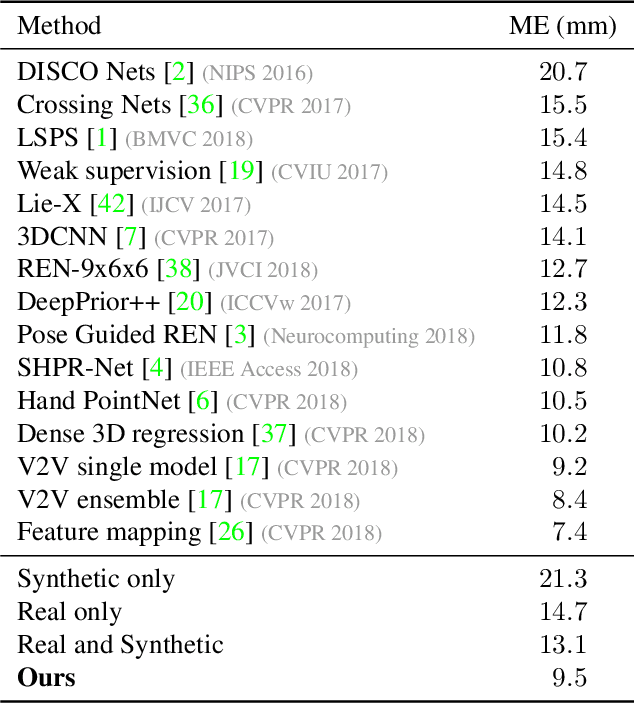
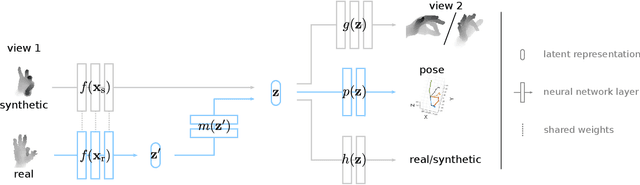
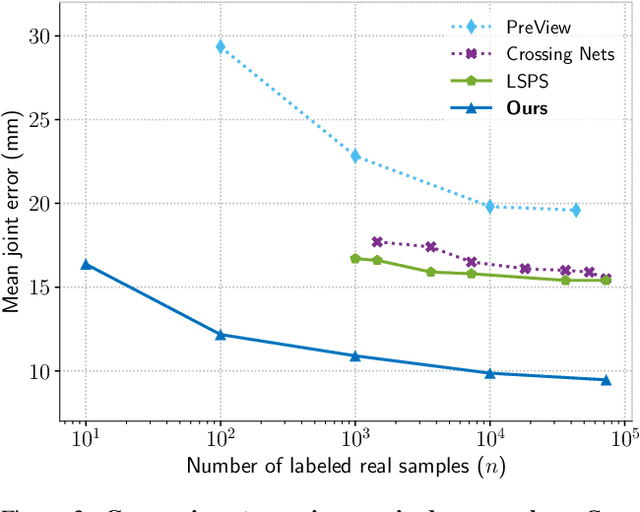
Data labeling for learning 3D hand pose estimation models is a huge effort. Readily available, accurately labeled synthetic data has the potential to reduce the effort. However, to successfully exploit synthetic data, current state-of-the-art methods still require a large amount of labeled real data. In this work, we remove this requirement by learning to map from the features of real data to the features of synthetic data mainly using a large amount of synthetic and unlabeled real data. We exploit unlabeled data using two auxiliary objectives, which enforce that (i) the mapped representation is pose specific and (ii) at the same time, the distributions of real and synthetic data are aligned. While pose specifity is enforced by a self-supervisory signal requiring that the representation is predictive for the appearance from different views, distributions are aligned by an adversarial term. In this way, we can significantly improve the results of the baseline system, which does not use unlabeled data and outperform many recent approaches already with about 1% of the labeled real data. This presents a step towards faster deployment of learning based hand pose estimation, making it accessible for a larger range of applications.
Learning Pose Specific Representations by Predicting Different Views
May 23, 2018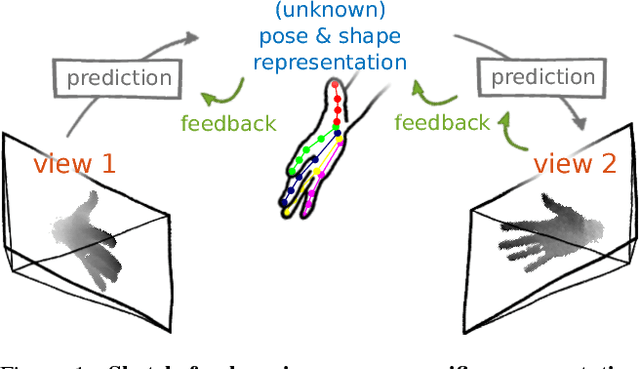
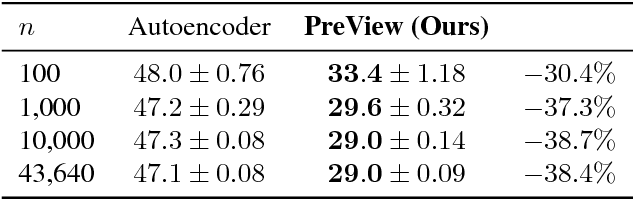
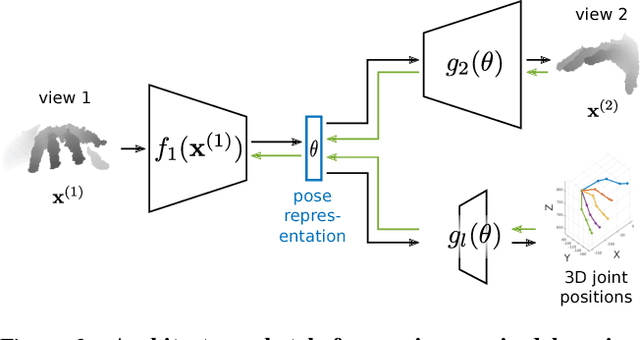
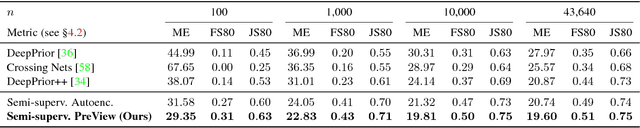
The labeled data required to learn pose estimation for articulated objects is difficult to provide in the desired quantity, realism, density, and accuracy. To address this issue, we develop a method to learn representations, which are very specific for articulated poses, without the need for labeled training data. We exploit the observation that the object pose of a known object is predictive for the appearance in any known view. That is, given only the pose and shape parameters of a hand, the hand's appearance from any viewpoint can be approximated. To exploit this observation, we train a model that -- given input from one view -- estimates a latent representation, which is trained to be predictive for the appearance of the object when captured from another viewpoint. Thus, the only necessary supervision is the second view. The training process of this model reveals an implicit pose representation in the latent space. Importantly, at test time the pose representation can be inferred using only a single view. In qualitative and quantitative experiments we show that the learned representations capture detailed pose information. Moreover, when training the proposed method jointly with labeled and unlabeled data, it consistently surpasses the performance of its fully supervised counterpart, while reducing the amount of needed labeled samples by at least one order of magnitude.