 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGACE: Geometry Aware Confidence Enhancement for Black-Box 3D Object Detectors on LiDAR-Data
Oct 31, 2023



Widely-used LiDAR-based 3D object detectors often neglect fundamental geometric information readily available from the object proposals in their confidence estimation. This is mostly due to architectural design choices, which were often adopted from the 2D image domain, where geometric context is rarely available. In 3D, however, considering the object properties and its surroundings in a holistic way is important to distinguish between true and false positive detections, e.g. occluded pedestrians in a group. To address this, we present GACE, an intuitive and highly efficient method to improve the confidence estimation of a given black-box 3D object detector. We aggregate geometric cues of detections and their spatial relationships, which enables us to properly assess their plausibility and consequently, improve the confidence estimation. This leads to consistent performance gains over a variety of state-of-the-art detectors. Across all evaluated detectors, GACE proves to be especially beneficial for the vulnerable road user classes, i.e. pedestrians and cyclists.
MAELi -- Masked Autoencoder for Large-Scale LiDAR Point Clouds
Dec 14, 2022



We show how the inherent, but often neglected, properties of large-scale LiDAR point clouds can be exploited for effective self-supervised representation learning. To this end, we design a highly data-efficient feature pre-training backbone that significantly reduces the amount of tedious 3D annotations to train state-of-the-art object detectors. In particular, we propose a Masked AutoEncoder (MAELi) that intuitively utilizes the sparsity of the LiDAR point clouds in both, the encoder and the decoder, during reconstruction. This results in more expressive and useful features, directly applicable to downstream perception tasks, such as 3D object detection for autonomous driving. In a novel reconstruction scheme, MAELi distinguishes between free and occluded space and leverages a new masking strategy which targets the LiDAR's inherent spherical projection. To demonstrate the potential of MAELi, we pre-train one of the most widespread 3D backbones, in an end-to-end fashion and show the merit of our fully unsupervised pre-trained features on several 3D object detection architectures. Given only a tiny fraction of labeled frames to fine-tune such detectors, we achieve significant performance improvements. For example, with only $\sim800$ labeled frames, MAELi features improve a SECOND model by +10.09APH/LEVEL 2 on Waymo Vehicles.
OccAM's Laser: Occlusion-based Attribution Maps for 3D Object Detectors on LiDAR Data
Apr 13, 2022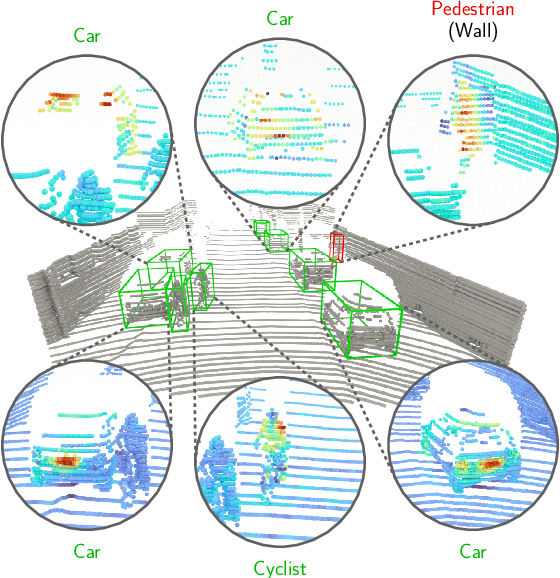
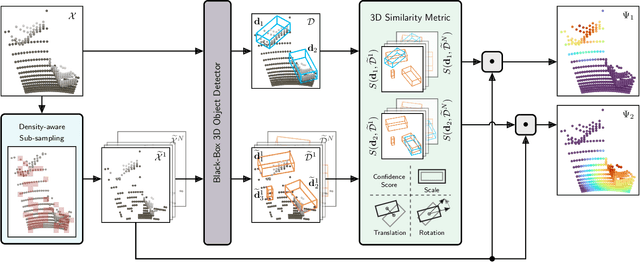
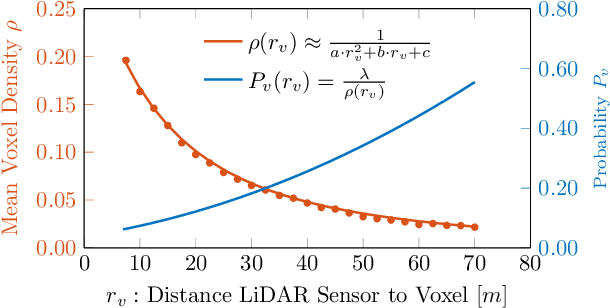
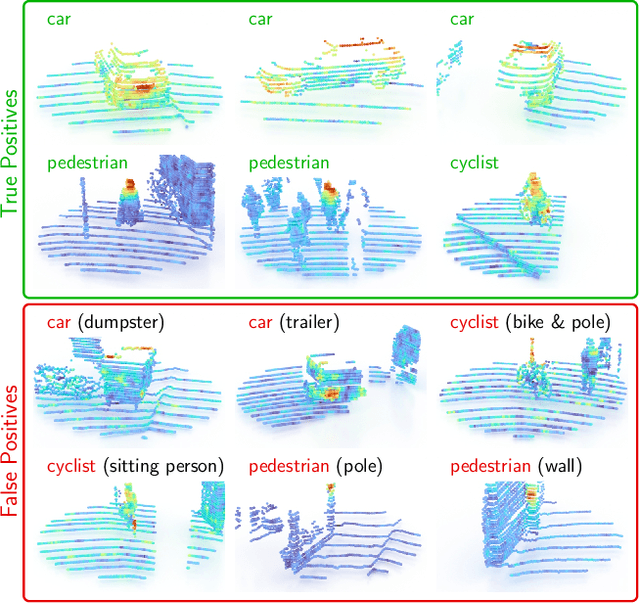
While 3D object detection in LiDAR point clouds is well-established in academia and industry, the explainability of these models is a largely unexplored field. In this paper, we propose a method to generate attribution maps for the detected objects in order to better understand the behavior of such models. These maps indicate the importance of each 3D point in predicting the specific objects. Our method works with black-box models: We do not require any prior knowledge of the architecture nor access to the model's internals, like parameters, activations or gradients. Our efficient perturbation-based approach empirically estimates the importance of each point by testing the model with randomly generated subsets of the input point cloud. Our sub-sampling strategy takes into account the special characteristics of LiDAR data, such as the depth-dependent point density. We show a detailed evaluation of the attribution maps and demonstrate that they are interpretable and highly informative. Furthermore, we compare the attribution maps of recent 3D object detection architectures to provide insights into their decision-making processes.
FuseSeg: LiDAR Point Cloud Segmentation Fusing Multi-Modal Data
Dec 19, 2019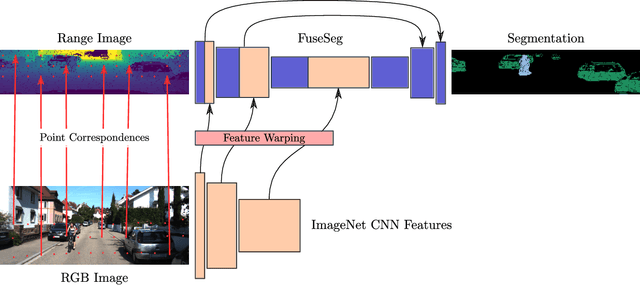
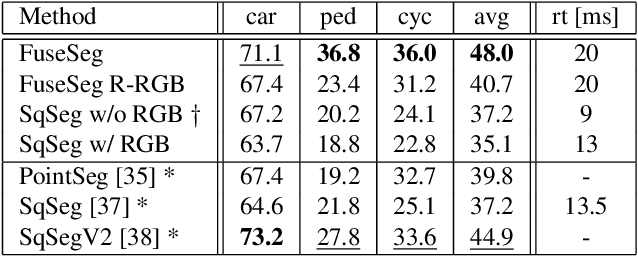
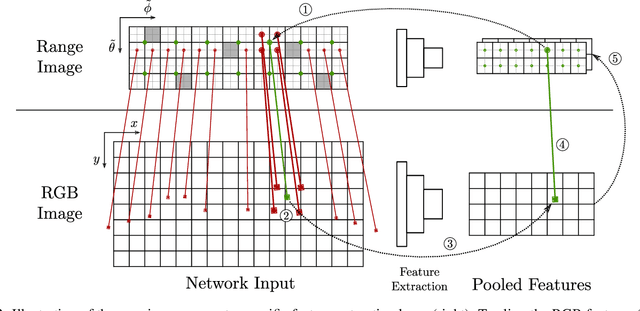

We introduce a simple yet effective fusion method of LiDAR and RGB data to segment LiDAR point clouds. Utilizing the dense native range representation of a LiDAR sensor and the setup calibration, we establish point correspondences between the two input modalities. Subsequently, we are able to warp and fuse the features from one domain into the other. Therefore, we can jointly exploit information from both data sources within one single network. To show the merit of our method, we extend SqueezeSeg, a point cloud segmentation network, with an RGB feature branch and fuse it into the original structure. Our extension called FuseSeg leads to an improvement of up to 18% IoU on the KITTI benchmark. In addition to the improved accuracy, we also achieve real-time performance at 50 fps, five times as fast as the KITTI LiDAR data recording speed.