 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccAM's Laser: Occlusion-based Attribution Maps for 3D Object Detectors on LiDAR Data
Apr 13, 2022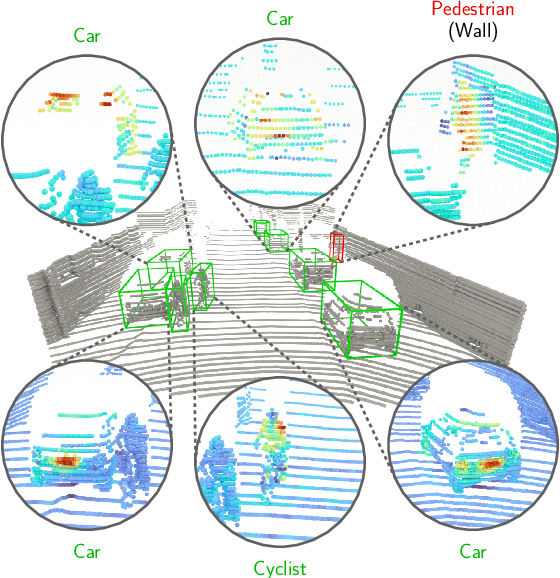
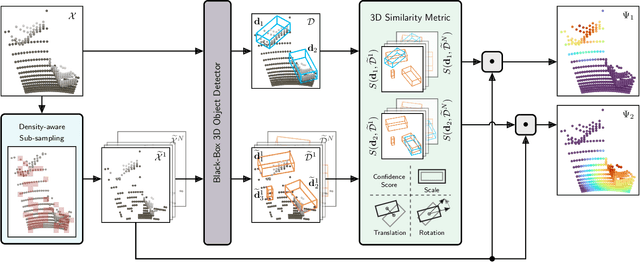
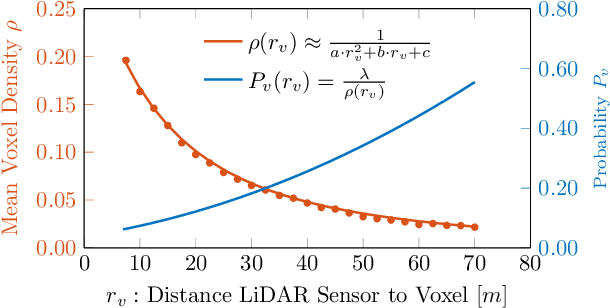
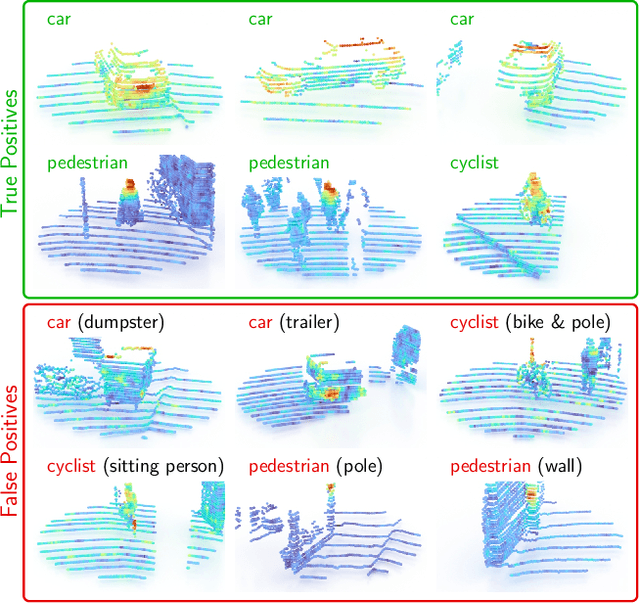
While 3D object detection in LiDAR point clouds is well-established in academia and industry, the explainability of these models is a largely unexplored field. In this paper, we propose a method to generate attribution maps for the detected objects in order to better understand the behavior of such models. These maps indicate the importance of each 3D point in predicting the specific objects. Our method works with black-box models: We do not require any prior knowledge of the architecture nor access to the model's internals, like parameters, activations or gradients. Our efficient perturbation-based approach empirically estimates the importance of each point by testing the model with randomly generated subsets of the input point cloud. Our sub-sampling strategy takes into account the special characteristics of LiDAR data, such as the depth-dependent point density. We show a detailed evaluation of the attribution maps and demonstrate that they are interpretable and highly informative. Furthermore, we compare the attribution maps of recent 3D object detection architectures to provide insights into their decision-making processes.
Automated cross-sectional view selection in CT angiography of aortic dissections with uncertainty awareness and retrospective clinical annotations
Nov 22, 2021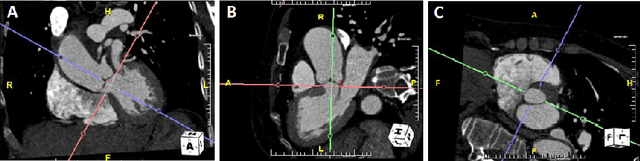
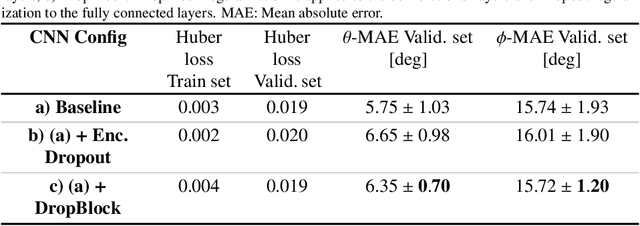
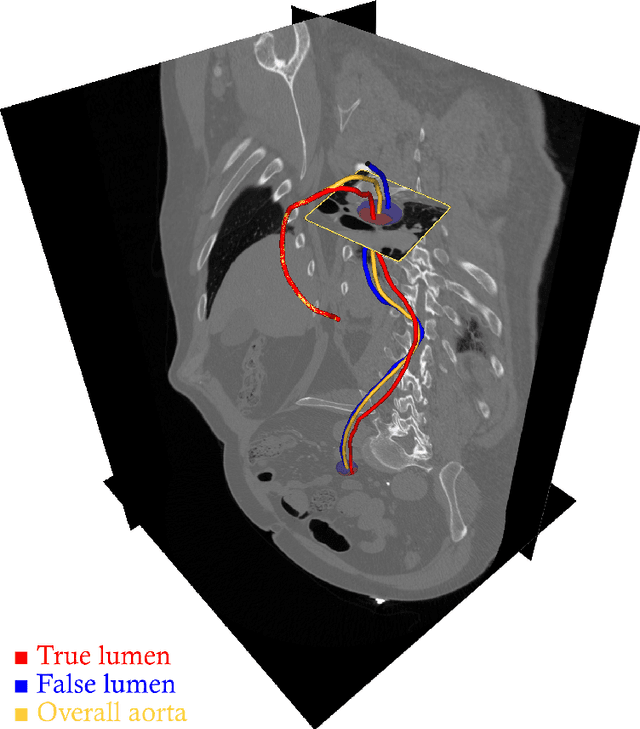
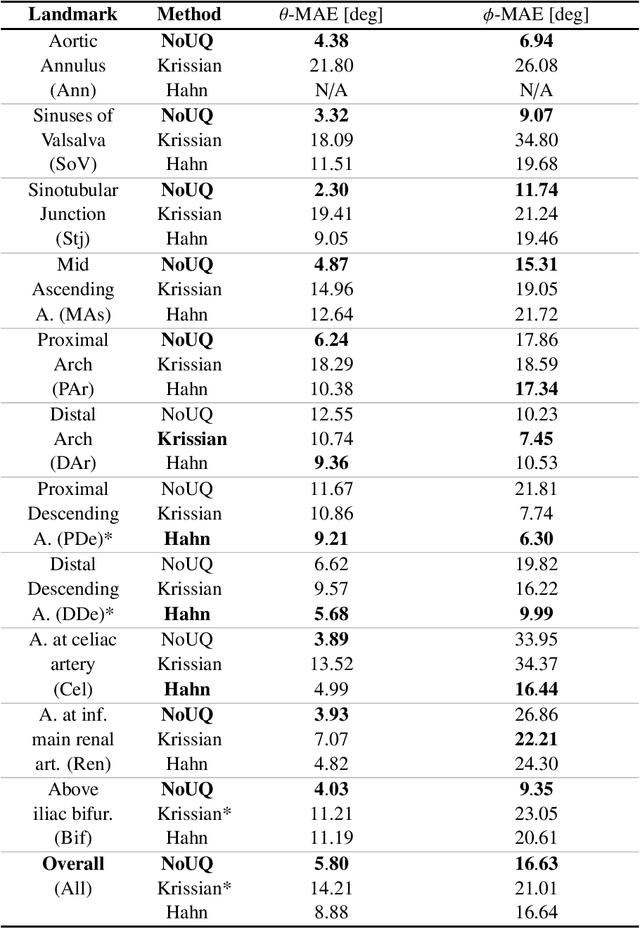
Objective: Surveillance imaging of chronic aortic diseases, such as dissections, relies on obtaining and comparing cross-sectional diameter measurements at predefined aortic landmarks, over time. Due to a lack of robust tools, the orientation of the cross-sectional planes is defined manually by highly trained operators. We show how manual annotations routinely collected in a clinic can be efficiently used to ease this task, despite the presence of a non-negligible interoperator variability in the measurements. Impact: Ill-posed but repetitive imaging tasks can be eased or automated by leveraging imperfect, retrospective clinical annotations. Methodology: In this work, we combine convolutional neural networks and uncertainty quantification methods to predict the orientation of such cross-sectional planes. We use clinical data randomly processed by 11 operators for training, and test on a smaller set processed by 3 independent operators to assess interoperator variability. Results: Our analysis shows that manual selection of cross-sectional planes is characterized by 95% limits of agreement (LOA) of $10.6^\circ$ and $21.4^\circ$ per angle. Our method showed to decrease static error by $3.57^\circ$ ($40.2$%) and $4.11^\circ$ ($32.8$%) against state of the art and LOA by $5.4^\circ$ ($49.0$%) and $16.0^\circ$ ($74.6$%) against manual processing. Conclusion: This suggests that pre-existing annotations can be an inexpensive resource in clinics to ease ill-posed and repetitive tasks like cross-section extraction for surveillance of aortic dissections.
Geometric Correspondence Fields: Learned Differentiable Rendering for 3D Pose Refinement in the Wild
Jul 17, 2020
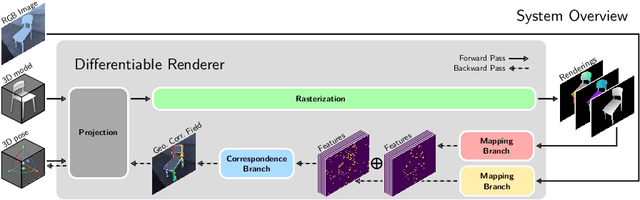
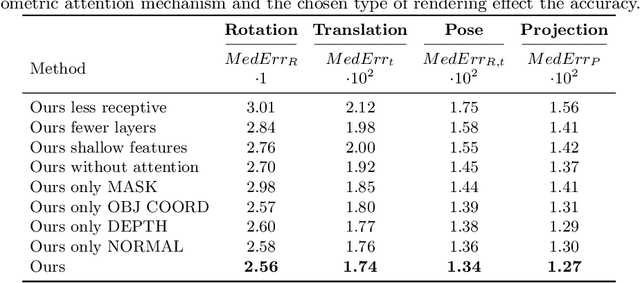
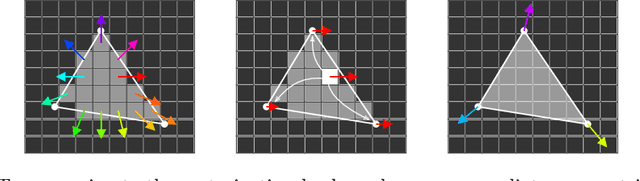
We present a novel 3D pose refinement approach based on differentiable rendering for objects of arbitrary categories in the wild. In contrast to previous methods, we make two main contributions: First, instead of comparing real-world images and synthetic renderings in the RGB or mask space, we compare them in a feature space optimized for 3D pose refinement. Second, we introduce a novel differentiable renderer that learns to approximate the rasterization backward pass from data instead of relying on a hand-crafted algorithm. For this purpose, we predict deep cross-domain correspondences between RGB images and 3D model renderings in the form of what we call geometric correspondence fields. These correspondence fields serve as pixel-level gradients which are analytically propagated backward through the rendering pipeline to perform a gradient-based optimization directly on the 3D pose. In this way, we precisely align 3D models to objects in RGB images which results in significantly improved 3D pose estimates. We evaluate our approach on the challenging Pix3D dataset and achieve up to 55% relative improvement compared to state-of-the-art refinement methods in multiple metrics.
ALCN: Adaptive Local Contrast Normalization
Apr 15, 2020
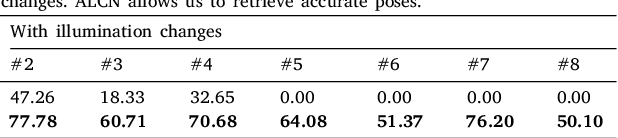
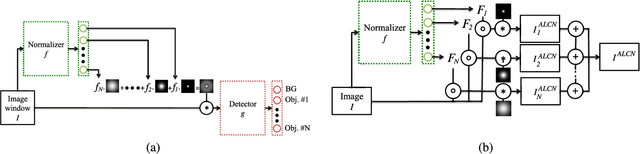

To make Robotics and Augmented Reality applications robust to illumination changes, the current trend is to train a Deep Network with training images captured under many different lighting conditions. Unfortunately, creating such a training set is a very unwieldy and complex task. We therefore propose a novel illumination normalization method that can easily be used for different problems with challenging illumination conditions. Our preliminary experiments show that among current normalization methods, the Difference-of Gaussians method remains a very good baseline, and we introduce a novel illumination normalization model that generalizes it. Our key insight is then that the normalization parameters should depend on the input image, and we aim to train a Convolutional Neural Network to predict these parameters from the input image. This, however, cannot be done in a supervised manner, as the optimal parameters are not known a priori. We thus designed a method to train this network jointly with another network that aims to recognize objects under different illuminations: The latter network performs well when the former network predicts good values for the normalization parameters. We show that our method significantly outperforms standard normalization methods and would also be appear to be universal since it does not have to be re-trained for each new application. Our method improves the robustness to light changes of state-of-the-art 3D object detection and face recognition methods.
Performing Arithmetic Using a Neural Network Trained on Digit Permutation Pairs
Dec 06, 2019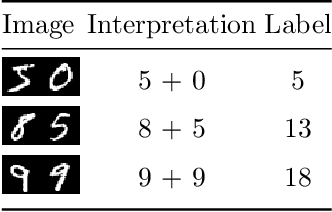

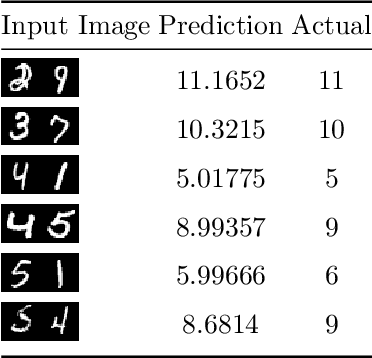
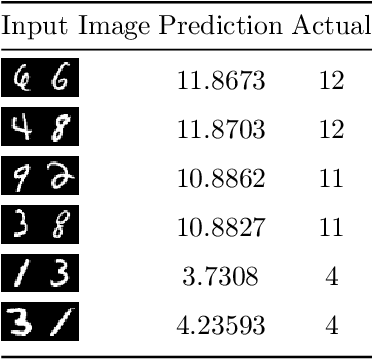
In this paper a neural network is trained to perform simple arithmetic using images of concatenated handwritten digit pairs. A convolutional neural network was trained with images consisting of two side-by-side handwritten digits, where the image's label is the summation of the two digits contained in the combined image. Crucially, the network was tested on permutation pairs that were not present during training in an effort to see if the network could learn the task of addition, as opposed to simply mapping images to labels. A dataset was generated for all possible permutation pairs of length 2 for the digits 0-9 using MNIST as a basis for the images, with one thousand samples generated for each permutation pair. For testing the network, samples generated from previously unseen permutation pairs were fed into the trained network, and its predictions measured. Results were encouraging, with the network achieving an accuracy of over 90% on some permutation train/test splits. This suggests that the network learned at first digit recognition, and subsequently the further task of addition based on the two recognised digits. As far as the authors are aware, no previous work has concentrated on learning a mathematical operation in this way.
Patch augmentation: Towards efficient decision boundaries for neural networks
Nov 25, 2019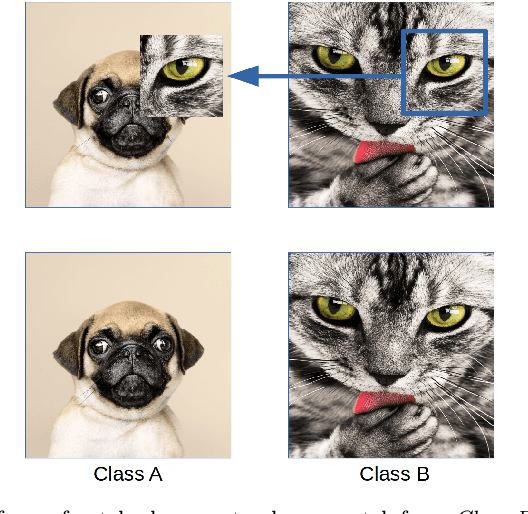


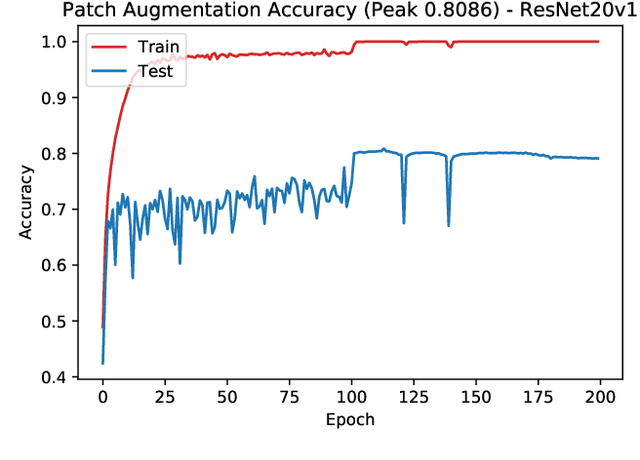
In this paper we propose a new augmentation technique, called patch augmentation, that, in our experiments, improves model accuracy and makes networks more robust to adversarial attacks. In brief, this data-independent approach creates new image data based on image/label pairs, where a patch from one of the two images in the pair is superimposed on to the other image, creating a new augmented sample. The new image's label is a linear combination of the image pair's corresponding labels. Initial experiments show a several percentage point increase in accuracy on CIFAR-10, from a baseline of approximately 81% to 89%. CIFAR-100 sees larger improvements still, from a baseline of 52% to 68% accuracy. Networks trained using patch augmentation are also more robust to adversarial attacks, which we demonstrate using the Fast Gradient Sign Method.
L*ReLU: Piece-wise Linear Activation Functions for Deep Fine-grained Visual Categorization
Oct 27, 2019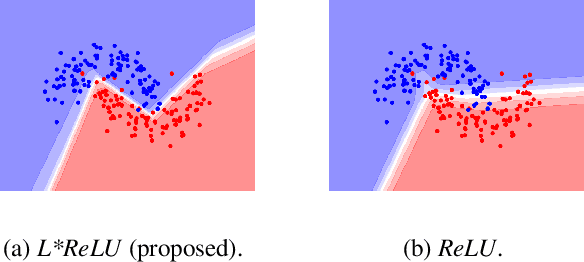

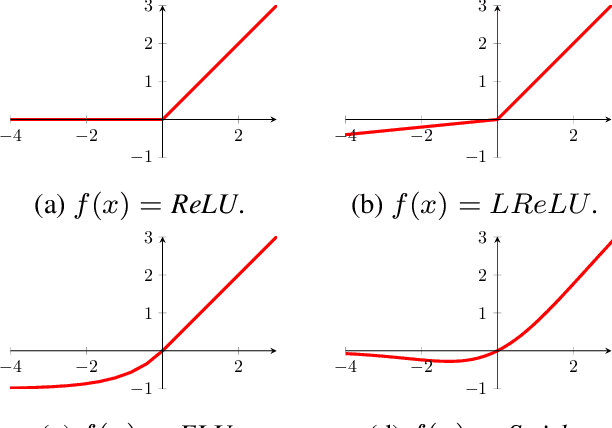
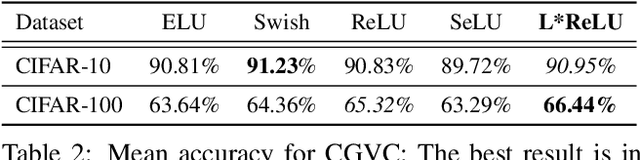
Deep neural networks paved the way for significant improvements in image visual categorization during the last years. However, even though the tasks are highly varying, differing in complexity and difficulty, existing solutions mostly build on the same architectural decisions. This also applies to the selection of activation functions (AFs), where most approaches build on Rectified Linear Units (ReLUs). In this paper, however, we show that the choice of a proper AF has a significant impact on the classification accuracy, in particular, if fine, subtle details are of relevance. Therefore, we propose to model the degree of absence and the presence of features via the AF by using piece-wise linear functions, which we refer to as L*ReLU. In this way, we can ensure the required properties, while still inheriting the benefits in terms of computational efficiency from ReLUs. We demonstrate our approach for the task of Fine-grained Visual Categorization (FGVC), running experiments on seven different benchmark datasets. The results do not only demonstrate superior results but also that for different tasks, having different characteristics, different AFs are selected.
Smart Hypothesis Generation for Efficient and Robust Room Layout Estimation
Oct 27, 2019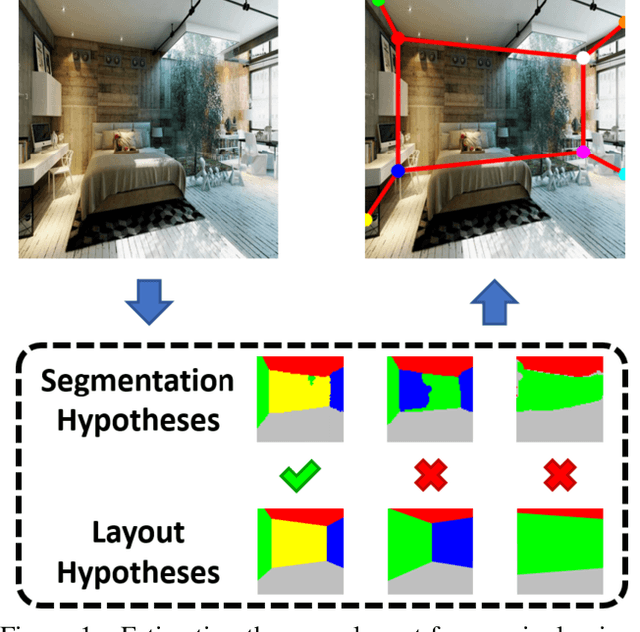
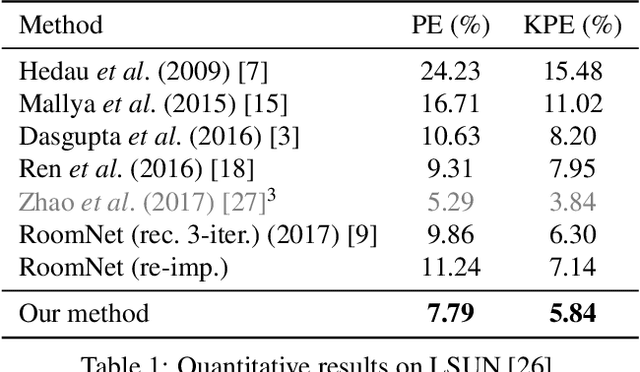
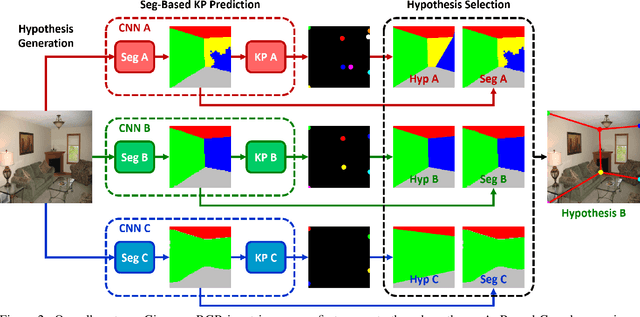
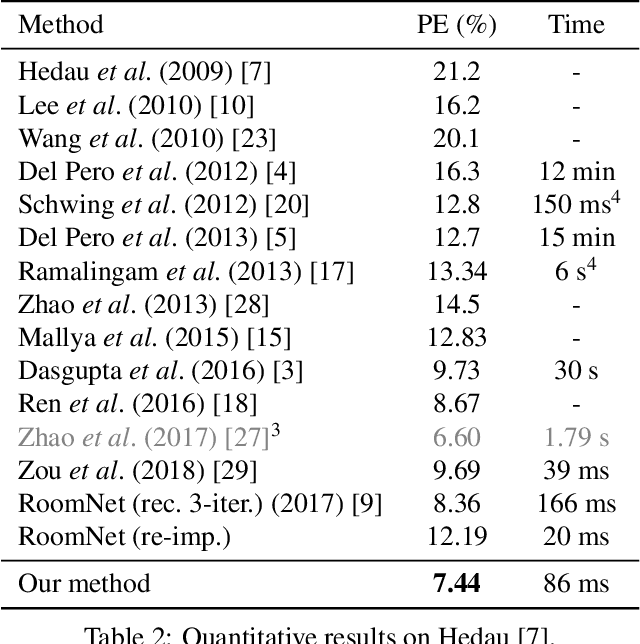
We propose a novel method to efficiently estimate the spatial layout of a room from a single monocular RGB image. As existing approaches based on low-level feature extraction, followed by a vanishing point estimation are very slow and often unreliable in realistic scenarios, we build on semantic segmentation of the input image. To obtain better segmentations, we introduce a robust, accurate and very efficient hypothesize-and-test scheme. The key idea is to use three segmentation hypotheses, each based on a different number of visible walls. For each hypothesis, we predict the image locations of the room corners and select the hypothesis for which the layout estimated from the room corners is consistent with the segmentation. We demonstrate the efficiency and robustness of our method on three challenging benchmark datasets, where we significantly outperform the state-of-the-art.
Location Field Descriptors: Single Image 3D Model Retrieval in the Wild
Aug 07, 2019
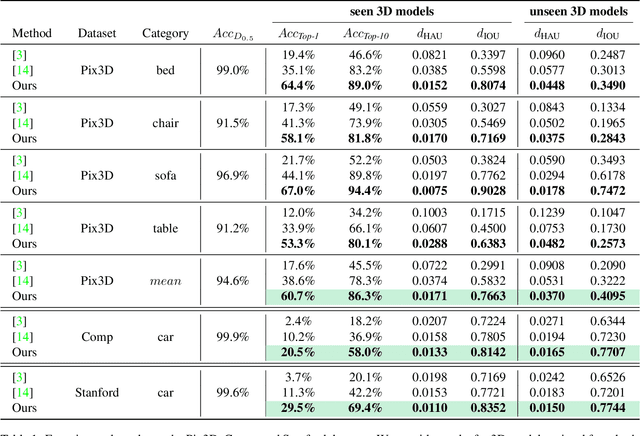
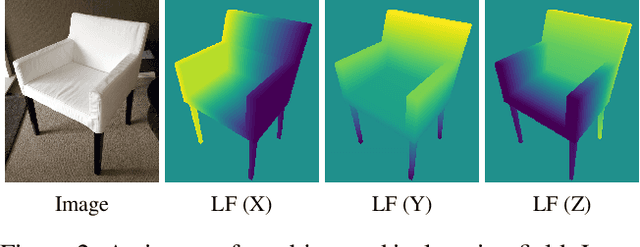
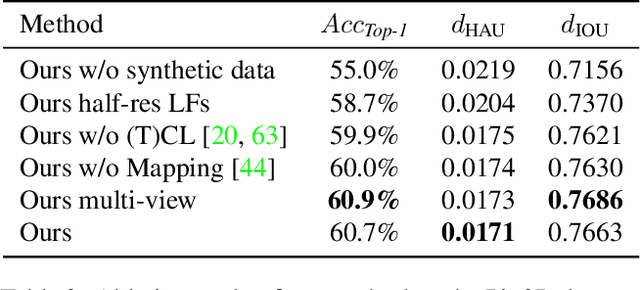
We present Location Field Descriptors, a novel approach for single image 3D model retrieval in the wild. In contrast to previous methods that directly map 3D models and RGB images to an embedding space, we establish a common low-level representation in the form of location fields from which we compute pose invariant 3D shape descriptors. Location fields encode correspondences between 2D pixels and 3D surface coordinates and, thus, explicitly capture 3D shape and 3D pose information without appearance variations which are irrelevant for the task. This early fusion of 3D models and RGB images results in three main advantages: First, the bottleneck location field prediction acts as a regularizer during training. Second, major parts of the system benefit from training on a virtually infinite amount of synthetic data. Finally, the predicted location fields are visually interpretable and unblackbox the system. We evaluate our proposed approach on three challenging real-world datasets (Pix3D, Comp, and Stanford) with different object categories and significantly outperform the state-of-the-art by up to 20% absolute in multiple 3D retrieval metrics.
GP2C: Geometric Projection Parameter Consensus for Joint 3D Pose and Focal Length Estimation in the Wild
Aug 07, 2019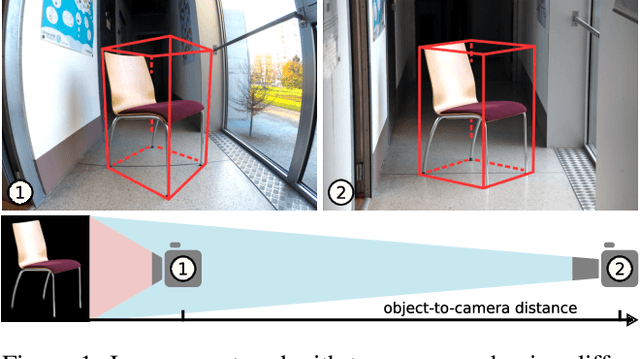
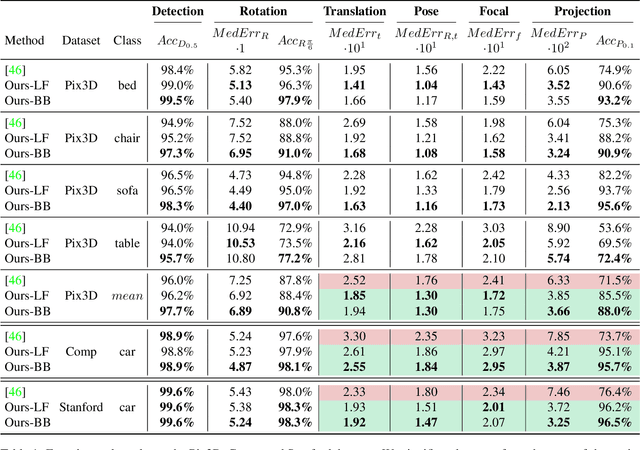


We present a joint 3D pose and focal length estimation approach for object categories in the wild. In contrast to previous methods that predict 3D poses independently of the focal length or assume a constant focal length, we explicitly estimate and integrate the focal length into the 3D pose estimation. For this purpose, we combine deep learning techniques and geometric algorithms in a two-stage approach: First, we estimate an initial focal length and establish 2D-3D correspondences from a single RGB image using a deep network. Second, we recover 3D poses and refine the focal length by minimizing the reprojection error of the predicted correspondences. In this way, we exploit the geometric prior given by the focal length for 3D pose estimation. This results in two advantages: First, we achieve significantly improved 3D translation and 3D pose accuracy compared to existing methods. Second, our approach finds a geometric consensus between the individual projection parameters, which is required for precise 2D-3D alignment. We evaluate our proposed approach on three challenging real-world datasets (Pix3D, Comp, and Stanford) with different object categories and significantly outperform the state-of-the-art by up to 20% absolute in multiple different metrics.