 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL*ReLU: Piece-wise Linear Activation Functions for Deep Fine-grained Visual Categorization
Oct 27, 2019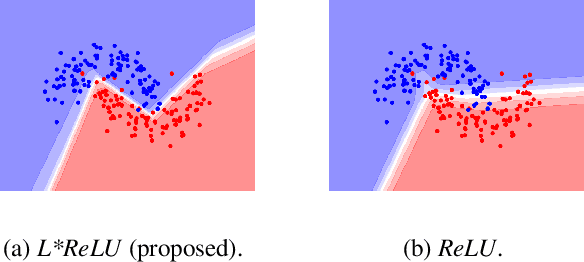

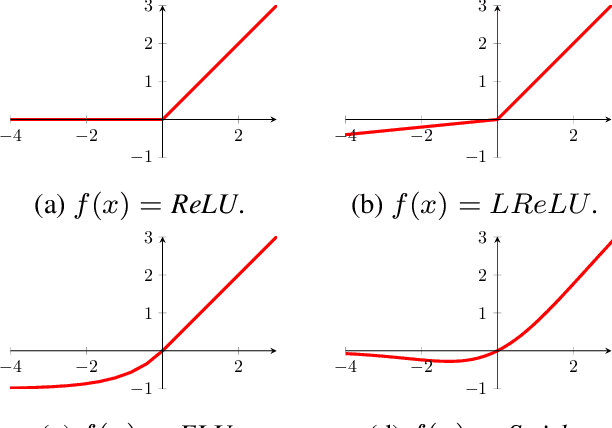
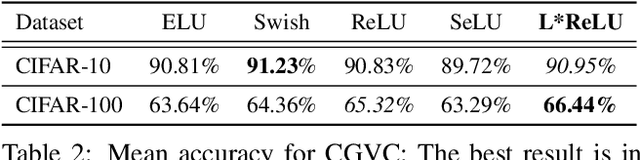
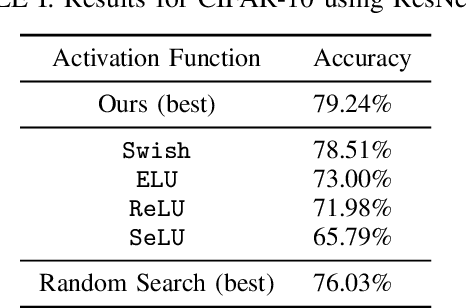
Deep neural networks paved the way for significant improvements in image visual categorization during the last years. However, even though the tasks are highly varying, differing in complexity and difficulty, existing solutions mostly build on the same architectural decisions. This also applies to the selection of activation functions (AFs), where most approaches build on Rectified Linear Units (ReLUs). In this paper, however, we show that the choice of a proper AF has a significant impact on the classification accuracy, in particular, if fine, subtle details are of relevance. Therefore, we propose to model the degree of absence and the presence of features via the AF by using piece-wise linear functions, which we refer to as L*ReLU. In this way, we can ensure the required properties, while still inheriting the benefits in terms of computational efficiency from ReLUs. We demonstrate our approach for the task of Fine-grained Visual Categorization (FGVC), running experiments on seven different benchmark datasets. The results do not only demonstrate superior results but also that for different tasks, having different characteristics, different AFs are selected.
The Quest for the Golden Activation Function
Aug 02, 2018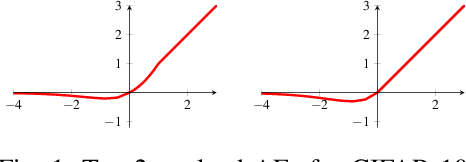
Deep Neural Networks have been shown to be beneficial for a variety of tasks, in particular allowing for end-to-end learning and reducing the requirement for manual design decisions. However, still many parameters have to be chosen in advance, also raising the need to optimize them. One important, but often ignored system parameter is the selection of a proper activation function. Thus, in this paper we target to demonstrate the importance of activation functions in general and show that for different tasks different activation functions might be meaningful. To avoid the manual design or selection of activation functions, we build on the idea of genetic algorithms to learn the best activation function for a given task. In addition, we introduce two new activation functions, ELiSH and HardELiSH, which can easily be incorporated in our framework. In this way, we demonstrate for three different image classification benchmarks that different activation functions are learned, also showing improved results compared to typically used baselines.