 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Activity Sequence Alignment via Implicit Clustering
Mar 16, 2025Self-supervised temporal sequence alignment can provide rich and effective representations for a wide range of applications. However, existing methods for achieving optimal performance are mostly limited to aligning sequences of the same activity only and require separate models to be trained for each activity. We propose a novel framework that overcomes these limitations using sequence alignment via implicit clustering. Specifically, our key idea is to perform implicit clip-level clustering while aligning frames in sequences. This coupled with our proposed dual augmentation technique enhances the network's ability to learn generalizable and discriminative representations. Our experiments show that our proposed method outperforms state-of-the-art results and highlight the generalization capability of our framework with multi activity and different modalities on three diverse datasets, H2O, PennAction, and IKEA ASM. We will release our code upon acceptance.
Space3D-Bench: Spatial 3D Question Answering Benchmark
Aug 29, 2024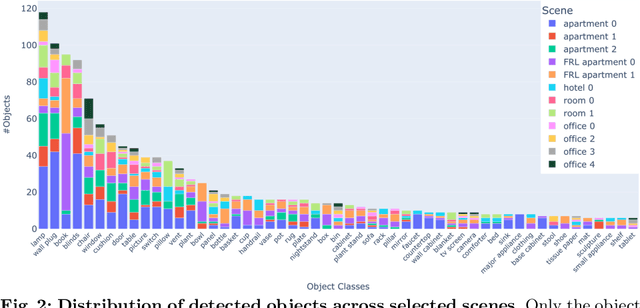
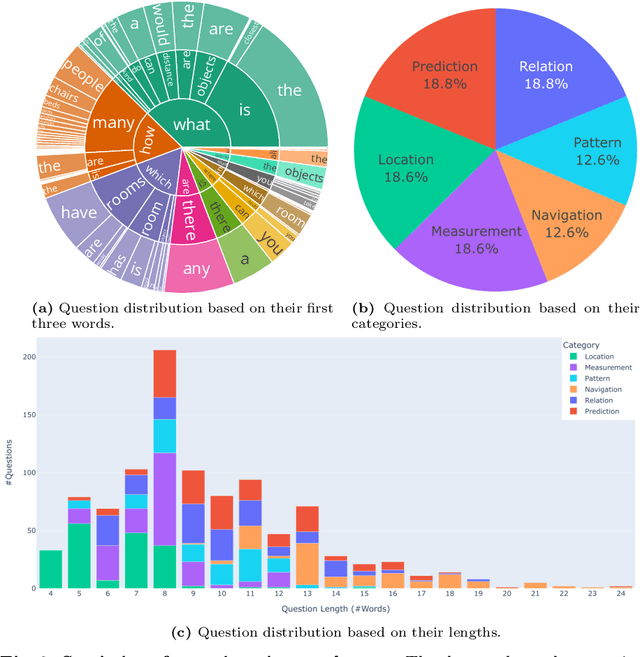
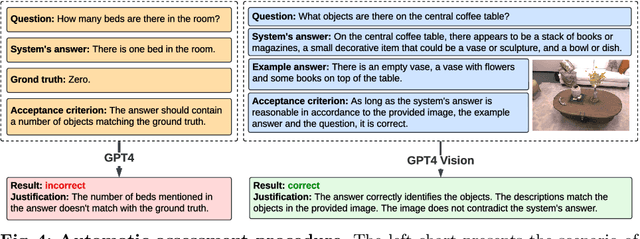
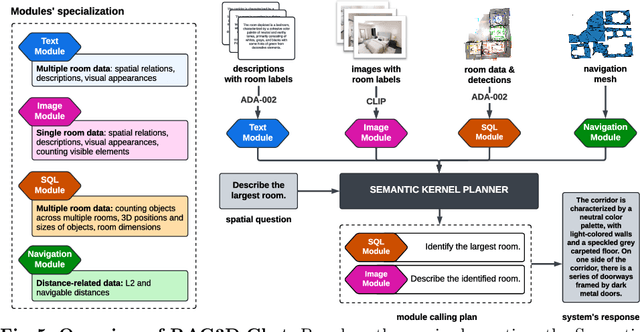
Answering questions about the spatial properties of the environment poses challenges for existing language and vision foundation models due to a lack of understanding of the 3D world notably in terms of relationships between objects. To push the field forward, multiple 3D Q&A datasets were proposed which, overall, provide a variety of questions, but they individually focus on particular aspects of 3D reasoning or are limited in terms of data modalities. To address this, we present Space3D-Bench - a collection of 1000 general spatial questions and answers related to scenes of the Replica dataset which offers a variety of data modalities: point clouds, posed RGB-D images, navigation meshes and 3D object detections. To ensure that the questions cover a wide range of 3D objectives, we propose an indoor spatial questions taxonomy inspired by geographic information systems and use it to balance the dataset accordingly. Moreover, we provide an assessment system that grades natural language responses based on predefined ground-truth answers by leveraging a Vision Language Model's comprehension of both text and images to compare the responses with ground-truth textual information or relevant visual data. Finally, we introduce a baseline called RAG3D-Chat integrating the world understanding of foundation models with rich context retrieval, achieving an accuracy of 67% on the proposed dataset.
SIGMA: An Open-Source Interactive System for Mixed-Reality Task Assistance Research
May 16, 2024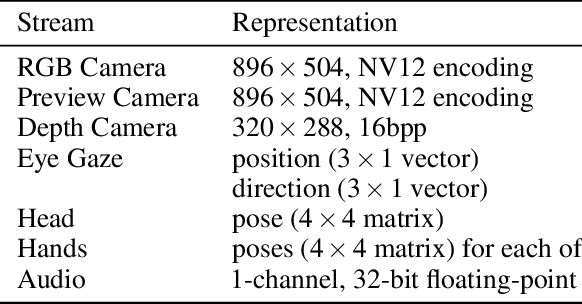


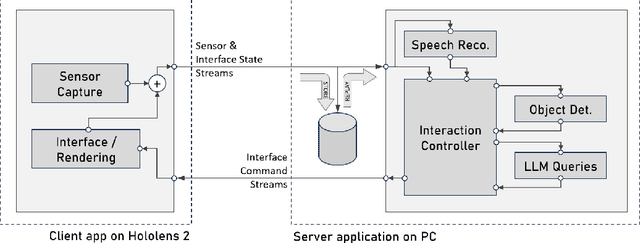
We introduce an open-source system called SIGMA (short for "Situated Interactive Guidance, Monitoring, and Assistance") as a platform for conducting research on task-assistive agents in mixed-reality scenarios. The system leverages the sensing and rendering affordances of a head-mounted mixed-reality device in conjunction with large language and vision models to guide users step by step through procedural tasks. We present the system's core capabilities, discuss its overall design and implementation, and outline directions for future research enabled by the system. SIGMA is easily extensible and provides a useful basis for future research at the intersection of mixed reality and AI. By open-sourcing an end-to-end implementation, we aim to lower the barrier to entry, accelerate research in this space, and chart a path towards community-driven end-to-end evaluation of large language, vision, and multimodal models in the context of real-world interactive applications.
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
Sep 29, 2023



Building an interactive AI assistant that can perceive, reason, and collaborate with humans in the real world has been a long-standing pursuit in the AI community. This work is part of a broader research effort to develop intelligent agents that can interactively guide humans through performing tasks in the physical world. As a first step in this direction, we introduce HoloAssist, a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. The task performer executes the task while wearing a mixed-reality headset that captures seven synchronized data streams. The task instructor watches the performer's egocentric video in real time and guides them verbally. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment. HoloAssist spans 166 hours of data captured by 350 unique instructor-performer pairs. Furthermore, we construct and present benchmarks on mistake detection, intervention type prediction, and hand forecasting, along with detailed analysis. We expect HoloAssist will provide an important resource for building AI assistants that can fluidly collaborate with humans in the real world. Data can be downloaded at https://holoassist.github.io/.
CaSAR: Contact-aware Skeletal Action Recognition
Sep 17, 2023



Skeletal Action recognition from an egocentric view is important for applications such as interfaces in AR/VR glasses and human-robot interaction, where the device has limited resources. Most of the existing skeletal action recognition approaches use 3D coordinates of hand joints and 8-corner rectangular bounding boxes of objects as inputs, but they do not capture how the hands and objects interact with each other within the spatial context. In this paper, we present a new framework called Contact-aware Skeletal Action Recognition (CaSAR). It uses novel representations of hand-object interaction that encompass spatial information: 1) contact points where the hand joints meet the objects, 2) distant points where the hand joints are far away from the object and nearly not involved in the current action. Our framework is able to learn how the hands touch or stay away from the objects for each frame of the action sequence, and use this information to predict the action class. We demonstrate that our approach achieves the state-of-the-art accuracy of 91.3% and 98.4% on two public datasets, H2O and FPHA, respectively.
MCTS with Refinement for Proposals Selection Games in Scene Understanding
Jul 07, 2022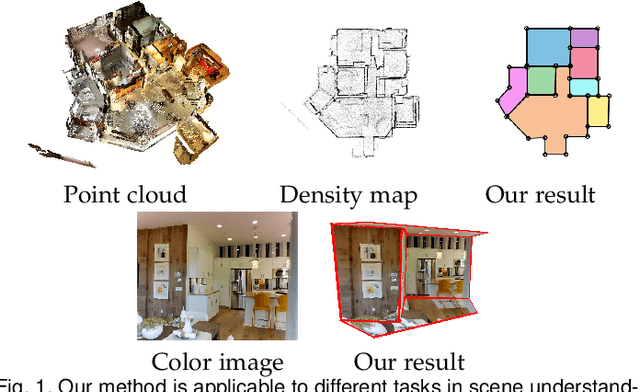
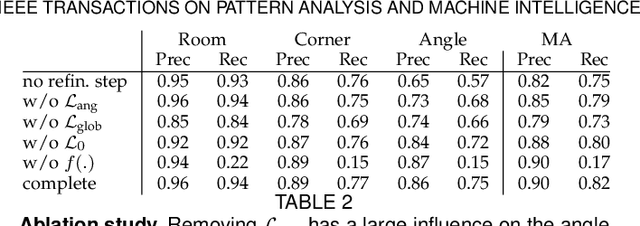
We propose a novel method applicable in many scene understanding problems that adapts the Monte Carlo Tree Search (MCTS) algorithm, originally designed to learn to play games of high-state complexity. From a generated pool of proposals, our method jointly selects and optimizes proposals that minimize the objective term. In our first application for floor plan reconstruction from point clouds, our method selects and refines the room proposals, modelled as 2D polygons, by optimizing on an objective function combining the fitness as predicted by a deep network and regularizing terms on the room shapes. We also introduce a novel differentiable method for rendering the polygonal shapes of these proposals. Our evaluations on the recent and challenging Structured3D and Floor-SP datasets show significant improvements over the state-of-the-art, without imposing hard constraints nor assumptions on the floor plan configurations. In our second application, we extend our approach to reconstruct general 3D room layouts from a color image and obtain accurate room layouts. We also show that our differentiable renderer can easily be extended for rendering 3D planar polygons and polygon embeddings. Our method shows high performance on the Matterport3D-Layout dataset, without introducing hard constraints on room layout configurations.
HandsFormer: Keypoint Transformer for Monocular 3D Pose Estimation ofHands and Object in Interaction
Apr 29, 2021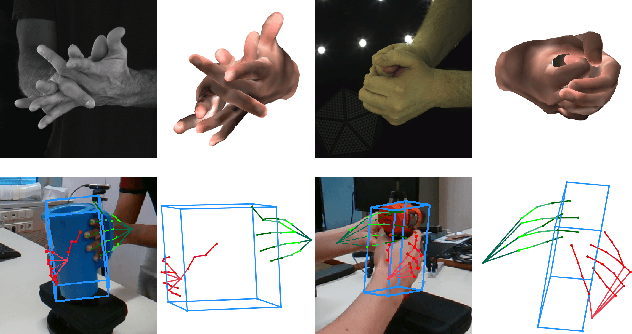
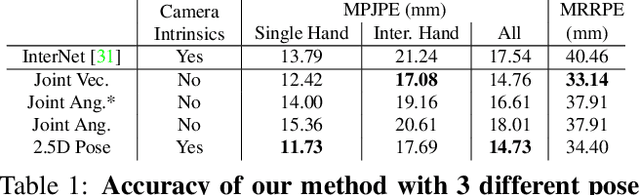
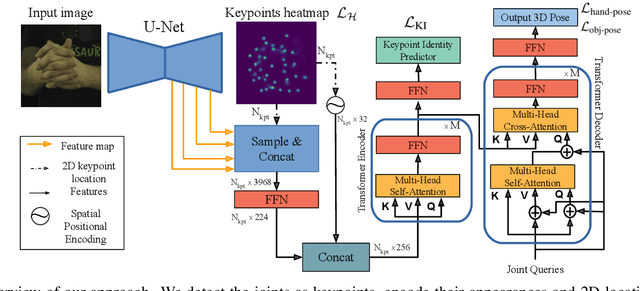

We propose a robust and accurate method for estimating the 3D poses of two hands in close interaction from a single color image. This is a very challenging problem, as large occlusions and many confusions between the joints may happen. Our method starts by extracting a set of potential 2D locations for the joints of both hands as extrema of a heatmap. We do not require that all locations correctly correspond to a joint, not that all the joints are detected. We use appearance and spatial encodings of these locations as input to a transformer, and leverage the attention mechanisms to sort out the correct configuration of the joints and output the 3D poses of both hands. Our approach thus allies the recognition power of a Transformer to the accuracy of heatmap-based methods. We also show it can be extended to estimate the 3D pose of an object manipulated by one or two hands. We evaluate our approach on the recent and challenging InterHand2.6M and HO-3D datasets. We obtain 17% improvement over the baseline. Moreover, we introduce the first dataset made of action sequences of two hands manipulating an object fully annotated in 3D and will make it publicly available.
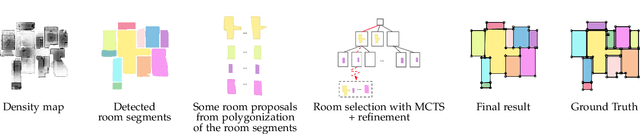
MonteFloor: Extending MCTS for Reconstructing Accurate Large-Scale Floor Plans
Mar 20, 2021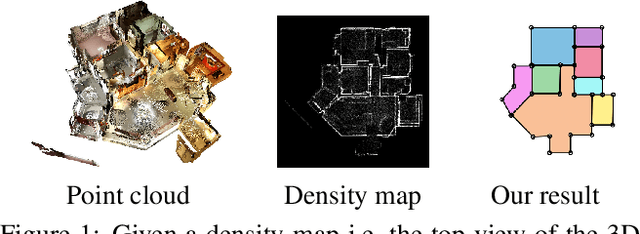
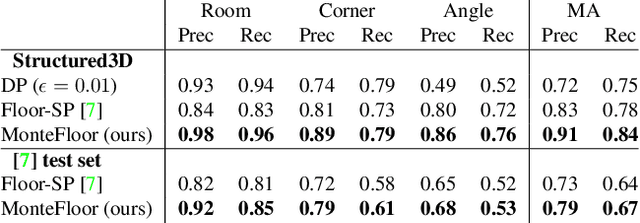

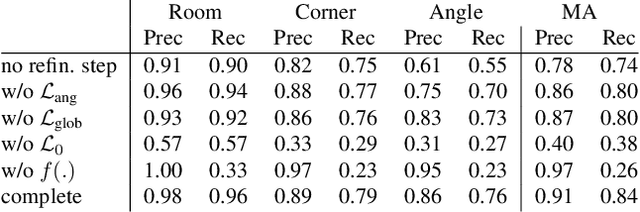
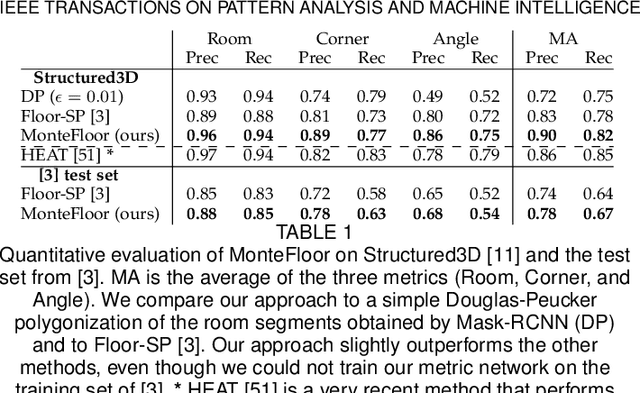
We propose a novel method for reconstructing floor plans from noisy 3D point clouds. Our main contribution is a principled approach that relies on the Monte Carlo Tree Search (MCTS) algorithm to maximize a suitable objective function efficiently despite the complexity of the problem. Like previous work, we first project the input point cloud to a top view to create a density map and extract room proposals from it. Our method selects and optimizes the polygonal shapes of these room proposals jointly to fit the density map and outputs an accurate vectorized floor map even for large complex scenes. To do this, we adapted MCTS, an algorithm originally designed to learn to play games, to select the room proposals by maximizing an objective function combining the fitness with the density map as predicted by a deep network and regularizing terms on the room shapes. We also introduce a refinement step to MCTS that adjusts the shape of the room proposals. For this step, we propose a novel differentiable method for rendering the polygonal shapes of these proposals. We evaluate our method on the recent and challenging Structured3D and Floor-SP datasets and show a significant improvement over the state-of-the-art, without imposing any hard constraints nor assumptions on the floor plan configurations.
ALCN: Adaptive Local Contrast Normalization
Apr 15, 2020
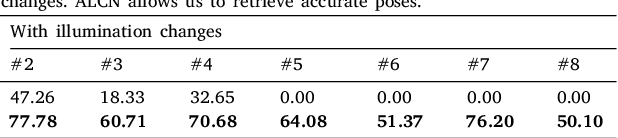
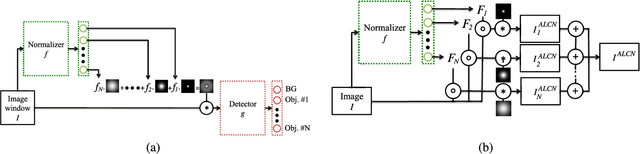

To make Robotics and Augmented Reality applications robust to illumination changes, the current trend is to train a Deep Network with training images captured under many different lighting conditions. Unfortunately, creating such a training set is a very unwieldy and complex task. We therefore propose a novel illumination normalization method that can easily be used for different problems with challenging illumination conditions. Our preliminary experiments show that among current normalization methods, the Difference-of Gaussians method remains a very good baseline, and we introduce a novel illumination normalization model that generalizes it. Our key insight is then that the normalization parameters should depend on the input image, and we aim to train a Convolutional Neural Network to predict these parameters from the input image. This, however, cannot be done in a supervised manner, as the optimal parameters are not known a priori. We thus designed a method to train this network jointly with another network that aims to recognize objects under different illuminations: The latter network performs well when the former network predicts good values for the normalization parameters. We show that our method significantly outperforms standard normalization methods and would also be appear to be universal since it does not have to be re-trained for each new application. Our method improves the robustness to light changes of state-of-the-art 3D object detection and face recognition methods.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
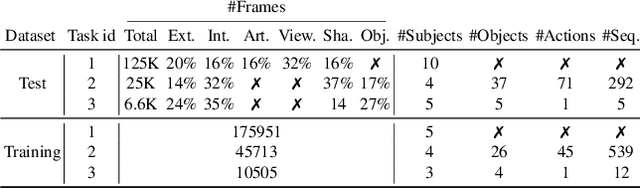
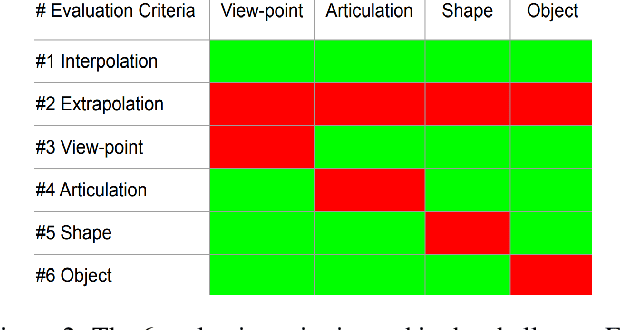
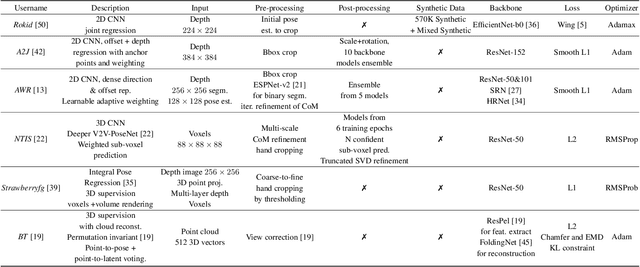
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.