 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Prompt Generation for Diverse Human-like Teaming and Communication with Large Language Models
Apr 04, 2025



Understanding how humans collaborate and communicate in teams is essential for improving human-agent teaming and AI-assisted decision-making. However, relying solely on data from large-scale user studies is impractical due to logistical, ethical, and practical constraints, necessitating synthetic models of multiple diverse human behaviors. Recently, agents powered by Large Language Models (LLMs) have been shown to emulate human-like behavior in social settings. But, obtaining a large set of diverse behaviors requires manual effort in the form of designing prompts. On the other hand, Quality Diversity (QD) optimization has been shown to be capable of generating diverse Reinforcement Learning (RL) agent behavior. In this work, we combine QD optimization with LLM-powered agents to iteratively search for prompts that generate diverse team behavior in a long-horizon, multi-step collaborative environment. We first show, through a human-subjects experiment (n=54 participants), that humans exhibit diverse coordination and communication behavior in this domain. We then show that our approach can effectively replicate trends from human teaming data and also capture behaviors that are not easily observed without collecting large amounts of data. Our findings highlight the combination of QD and LLM-powered agents as an effective tool for studying teaming and communication strategies in multi-agent collaboration.
Benchmark Real-time Adaptation and Communication Capabilities of Embodied Agent in Collaborative Scenarios
Nov 30, 2024



Advancements in Large Language Models (LLMs) have opened transformative possibilities for human-robot interaction, especially in collaborative environments. However, Real-time human-AI collaboration requires agents to adapt to unseen human behaviors while maintaining effective communication dynamically. Existing benchmarks fall short in evaluating such adaptability for embodied agents, focusing mostly on the task performance of the agent itself. To address this gap, we propose a novel benchmark that assesses agents' reactive adaptability and instantaneous communication capabilities at every step. Based on this benchmark, we propose a Monitor-then-Adapt framework (MonTA), combining strong adaptability and communication with real-time execution. MonTA contains three key LLM modules, a lightweight \textit{Monitor} for monitoring the need for adaptation in high frequency, and two proficient \textit{Adapters} for subtask and path adaptation reasoning in low frequency. Our results demonstrate that MonTA outperforms other baseline agents on our proposed benchmark. Further user studies confirm the high reasonability adaptation plan and consistent language instruction provided by our framework.
Self-supervised Feature Adaptation for 3D Industrial Anomaly Detection
Jan 17, 2024



Industrial anomaly detection is generally addressed as an unsupervised task that aims at locating defects with only normal training samples. Recently, numerous 2D anomaly detection methods have been proposed and have achieved promising results, however, using only the 2D RGB data as input is not sufficient to identify imperceptible geometric surface anomalies. Hence, in this work, we focus on multi-modal anomaly detection. Specifically, we investigate early multi-modal approaches that attempted to utilize models pre-trained on large-scale visual datasets, i.e., ImageNet, to construct feature databases. And we empirically find that directly using these pre-trained models is not optimal, it can either fail to detect subtle defects or mistake abnormal features as normal ones. This may be attributed to the domain gap between target industrial data and source data.Towards this problem, we propose a Local-to-global Self-supervised Feature Adaptation (LSFA) method to finetune the adaptors and learn task-oriented representation toward anomaly detection.Both intra-modal adaptation and cross-modal alignment are optimized from a local-to-global perspective in LSFA to ensure the representation quality and consistency in the inference stage.Extensive experiments demonstrate that our method not only brings a significant performance boost to feature embedding based approaches, but also outperforms previous State-of-The-Art (SoTA) methods prominently on both MVTec-3D AD and Eyecandies datasets, e.g., LSFA achieves 97.1% I-AUROC on MVTec-3D, surpass previous SoTA by +3.4%.
PVG: Progressive Vision Graph for Vision Recognition
Aug 01, 2023Convolution-based and Transformer-based vision backbone networks process images into the grid or sequence structures, respectively, which are inflexible for capturing irregular objects. Though Vision GNN (ViG) adopts graph-level features for complex images, it has some issues, such as inaccurate neighbor node selection, expensive node information aggregation calculation, and over-smoothing in the deep layers. To address the above problems, we propose a Progressive Vision Graph (PVG) architecture for vision recognition task. Compared with previous works, PVG contains three main components: 1) Progressively Separated Graph Construction (PSGC) to introduce second-order similarity by gradually increasing the channel of the global graph branch and decreasing the channel of local branch as the layer deepens; 2) Neighbor nodes information aggregation and update module by using Max pooling and mathematical Expectation (MaxE) to aggregate rich neighbor information; 3) Graph error Linear Unit (GraphLU) to enhance low-value information in a relaxed form to reduce the compression of image detail information for alleviating the over-smoothing. Extensive experiments on mainstream benchmarks demonstrate the superiority of PVG over state-of-the-art methods, e.g., our PVG-S obtains 83.0% Top-1 accuracy on ImageNet-1K that surpasses GNN-based ViG-S by +0.9 with the parameters reduced by 18.5%, while the largest PVG-B obtains 84.2% that has +0.5 improvement than ViG-B. Furthermore, our PVG-S obtains +1.3 box AP and +0.4 mask AP gains than ViG-S on COCO dataset.
* Accepted by ACM MM 2023
MixTeacher: Mining Promising Labels with Mixed Scale Teacher for Semi-Supervised Object Detection
Mar 16, 2023Scale variation across object instances remains a key challenge in object detection task. Despite the remarkable progress made by modern detection models, this challenge is particularly evident in the semi-supervised case. While existing semi-supervised object detection methods rely on strict conditions to filter high-quality pseudo labels from network predictions, we observe that objects with extreme scale tend to have low confidence, resulting in a lack of positive supervision for these objects. In this paper, we propose a novel framework that addresses the scale variation problem by introducing a mixed scale teacher to improve pseudo label generation and scale-invariant learning. Additionally, we propose mining pseudo labels using score promotion of predictions across scales, which benefits from better predictions from mixed scale features. Our extensive experiments on MS COCO and PASCAL VOC benchmarks under various semi-supervised settings demonstrate that our method achieves new state-of-the-art performance. The code and models are available at \url{https://github.com/lliuz/MixTeacher}.
Calibrated Teacher for Sparsely Annotated Object Detection
Mar 14, 2023
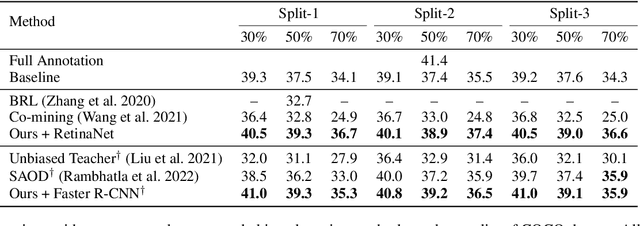
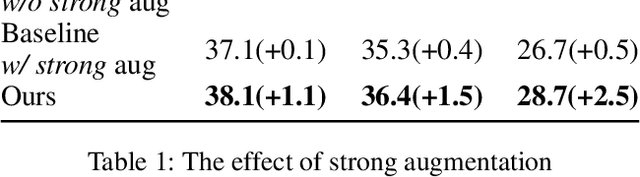
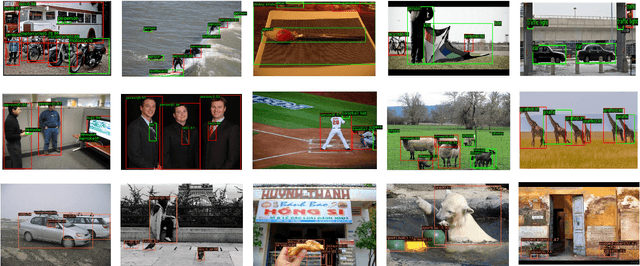
Fully supervised object detection requires training images in which all instances are annotated. This is actually impractical due to the high labor and time costs and the unavoidable missing annotations. As a result, the incomplete annotation in each image could provide misleading supervision and harm the training. Recent works on sparsely annotated object detection alleviate this problem by generating pseudo labels for the missing annotations. Such a mechanism is sensitive to the threshold of the pseudo label score. However, the effective threshold is different in different training stages and among different object detectors. Therefore, the current methods with fixed thresholds have sub-optimal performance, and are difficult to be applied to other detectors. In order to resolve this obstacle, we propose a Calibrated Teacher, of which the confidence estimation of the prediction is well calibrated to match its real precision. In this way, different detectors in different training stages would share a similar distribution of the output confidence, so that multiple detectors could share the same fixed threshold and achieve better performance. Furthermore, we present a simple but effective Focal IoU Weight (FIoU) for the classification loss. FIoU aims at reducing the loss weight of false negative samples caused by the missing annotation, and thus works as the complement of the teacher-student paradigm. Extensive experiments show that our methods set new state-of-the-art under all different sparse settings in COCO. Code will be available at https://github.com/Whileherham/CalibratedTeacher.
Learning from Noisy Labels with Decoupled Meta Label Purifier
Feb 17, 2023



Training deep neural networks(DNN) with noisy labels is challenging since DNN can easily memorize inaccurate labels, leading to poor generalization ability. Recently, the meta-learning based label correction strategy is widely adopted to tackle this problem via identifying and correcting potential noisy labels with the help of a small set of clean validation data. Although training with purified labels can effectively improve performance, solving the meta-learning problem inevitably involves a nested loop of bi-level optimization between model weights and hyper-parameters (i.e., label distribution). As compromise, previous methods resort to a coupled learning process with alternating update. In this paper, we empirically find such simultaneous optimization over both model weights and label distribution can not achieve an optimal routine, consequently limiting the representation ability of backbone and accuracy of corrected labels. From this observation, a novel multi-stage label purifier named DMLP is proposed. DMLP decouples the label correction process into label-free representation learning and a simple meta label purifier. In this way, DMLP can focus on extracting discriminative feature and label correction in two distinctive stages. DMLP is a plug-and-play label purifier, the purified labels can be directly reused in naive end-to-end network retraining or other robust learning methods, where state-of-the-art results are obtained on several synthetic and real-world noisy datasets, especially under high noise levels.
Self-supervised Likelihood Estimation with Energy Guidance for Anomaly Segmentation in Urban Scenes
Feb 15, 2023Robust autonomous driving requires agents to accurately identify unexpected areas in urban scenes. To this end, some critical issues remain open: how to design advisable metric to measure anomalies, and how to properly generate training samples of anomaly data? Previous effort usually resorts to uncertainty estimation and sample synthesis from classification tasks, which ignore the context information and sometimes requires auxiliary datasets with fine-grained annotations. On the contrary, in this paper, we exploit the strong context-dependent nature of segmentation task and design an energy-guided self-supervised frameworks for anomaly segmentation, which optimizes an anomaly head by maximizing the likelihood of self-generated anomaly pixels. To this end, we design two estimators for anomaly likelihood estimation, one is a simple task-agnostic binary estimator and the other depicts anomaly likelihood as residual of task-oriented energy model. Based on proposed estimators, we further incorporate our framework with likelihood-guided mask refinement process to extract informative anomaly pixels for model training. We conduct extensive experiments on challenging Fishyscapes and Road Anomaly benchmarks, demonstrating that without any auxiliary data or synthetic models, our method can still achieves competitive performance to other SOTA schemes.
Learning with Noisy labels via Self-supervised Adversarial Noisy Masking
Feb 15, 2023Collecting large-scale datasets is crucial for training deep models, annotating the data, however, inevitably yields noisy labels, which poses challenges to deep learning algorithms. Previous efforts tend to mitigate this problem via identifying and removing noisy samples or correcting their labels according to the statistical properties (e.g., loss values) among training samples. In this paper, we aim to tackle this problem from a new perspective, delving into the deep feature maps, we empirically find that models trained with clean and mislabeled samples manifest distinguishable activation feature distributions. From this observation, a novel robust training approach termed adversarial noisy masking is proposed. The idea is to regularize deep features with a label quality guided masking scheme, which adaptively modulates the input data and label simultaneously, preventing the model to overfit noisy samples. Further, an auxiliary task is designed to reconstruct input data, it naturally provides noise-free self-supervised signals to reinforce the generalization ability of deep models. The proposed method is simple and flexible, it is tested on both synthetic and real-world noisy datasets, where significant improvements are achieved over previous state-of-the-art methods.
Rethinking Mobile Block for Efficient Neural Models
Jan 10, 2023



This paper focuses on designing efficient models with low parameters and FLOPs for dense predictions. Even though CNN-based lightweight methods have achieved stunning results after years of research, trading-off model accuracy and constrained resources still need further improvements. This work rethinks the essential unity of efficient Inverted Residual Block in MobileNetv2 and effective Transformer in ViT, inductively abstracting a general concept of Meta-Mobile Block, and we argue that the specific instantiation is very important to model performance though sharing the same framework. Motivated by this phenomenon, we deduce a simple yet efficient modern \textbf{I}nverted \textbf{R}esidual \textbf{M}obile \textbf{B}lock (iRMB) for mobile applications, which absorbs CNN-like efficiency to model short-distance dependency and Transformer-like dynamic modeling capability to learn long-distance interactions. Furthermore, we design a ResNet-like 4-phase \textbf{E}fficient \textbf{MO}del (EMO) based only on a series of iRMBs for dense applications. Massive experiments on ImageNet-1K, COCO2017, and ADE20K benchmarks demonstrate the superiority of our EMO over state-of-the-art methods, \eg, our EMO-1M/2M/5M achieve 71.5, 75.1, and 78.4 Top-1 that surpass \textbf{SoTA} CNN-/Transformer-based models, while trading-off the model accuracy and efficiency well. Code: \url{https://github.com/zhangzjn/EMO}