 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Real-time Adaptation and Communication Capabilities of Embodied Agent in Collaborative Scenarios
Nov 30, 2024



Advancements in Large Language Models (LLMs) have opened transformative possibilities for human-robot interaction, especially in collaborative environments. However, Real-time human-AI collaboration requires agents to adapt to unseen human behaviors while maintaining effective communication dynamically. Existing benchmarks fall short in evaluating such adaptability for embodied agents, focusing mostly on the task performance of the agent itself. To address this gap, we propose a novel benchmark that assesses agents' reactive adaptability and instantaneous communication capabilities at every step. Based on this benchmark, we propose a Monitor-then-Adapt framework (MonTA), combining strong adaptability and communication with real-time execution. MonTA contains three key LLM modules, a lightweight \textit{Monitor} for monitoring the need for adaptation in high frequency, and two proficient \textit{Adapters} for subtask and path adaptation reasoning in low frequency. Our results demonstrate that MonTA outperforms other baseline agents on our proposed benchmark. Further user studies confirm the high reasonability adaptation plan and consistent language instruction provided by our framework.
DSBench: How Far Are Data Science Agents to Becoming Data Science Experts?
Sep 12, 2024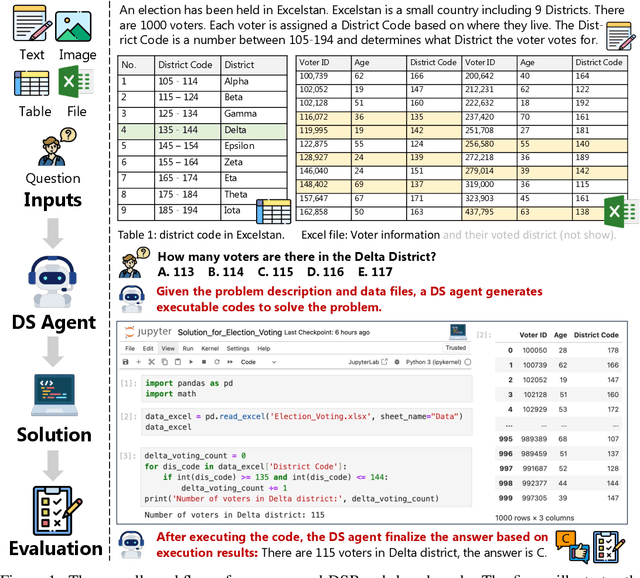
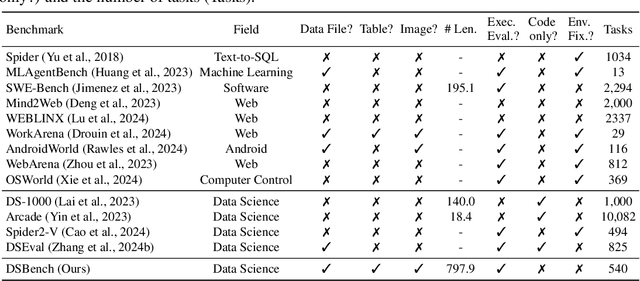
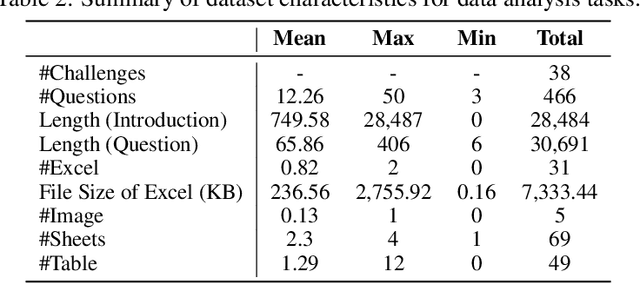
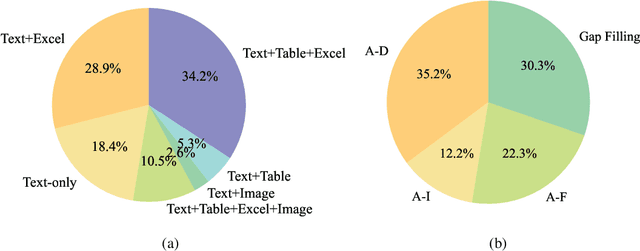
Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) have demonstrated impressive language/vision reasoning abilities, igniting the recent trend of building agents for targeted applications such as shopping assistants or AI software engineers. Recently, many data science benchmarks have been proposed to investigate their performance in the data science domain. However, existing data science benchmarks still fall short when compared to real-world data science applications due to their simplified settings. To bridge this gap, we introduce DSBench, a comprehensive benchmark designed to evaluate data science agents with realistic tasks. This benchmark includes 466 data analysis tasks and 74 data modeling tasks, sourced from Eloquence and Kaggle competitions. DSBench offers a realistic setting by encompassing long contexts, multimodal task backgrounds, reasoning with large data files and multi-table structures, and performing end-to-end data modeling tasks. Our evaluation of state-of-the-art LLMs, LVLMs, and agents shows that they struggle with most tasks, with the best agent solving only 34.12% of data analysis tasks and achieving a 34.74% Relative Performance Gap (RPG). These findings underscore the need for further advancements in developing more practical, intelligent, and autonomous data science agents.
From Words to Routes: Applying Large Language Models to Vehicle Routing
Mar 16, 2024



LLMs have shown impressive progress in robotics (e.g., manipulation and navigation) with natural language task descriptions. The success of LLMs in these tasks leads us to wonder: What is the ability of LLMs to solve vehicle routing problems (VRPs) with natural language task descriptions? In this work, we study this question in three steps. First, we construct a dataset with 21 types of single- or multi-vehicle routing problems. Second, we evaluate the performance of LLMs across four basic prompt paradigms of text-to-code generation, each involving different types of text input. We find that the basic prompt paradigm, which generates code directly from natural language task descriptions, performs the best for GPT-4, achieving 56% feasibility, 40% optimality, and 53% efficiency. Third, based on the observation that LLMs may not be able to provide correct solutions at the initial attempt, we propose a framework that enables LLMs to refine solutions through self-reflection, including self-debugging and self-verification. With GPT-4, our proposed framework achieves a 16% increase in feasibility, a 7% increase in optimality, and a 15% increase in efficiency. Moreover, we examine the sensitivity of GPT-4 to task descriptions, specifically focusing on how its performance changes when certain details are omitted from the task descriptions, yet the core meaning is preserved. Our findings reveal that such omissions lead to a notable decrease in performance: 4% in feasibility, 4% in optimality, and 5% in efficiency. Website: https://sites.google.com/view/words-to-routes/
Guaranteed Trust Region Optimization via Two-Phase KL Penalization
Dec 08, 2023



On-policy reinforcement learning (RL) has become a popular framework for solving sequential decision problems due to its computational efficiency and theoretical simplicity. Some on-policy methods guarantee every policy update is constrained to a trust region relative to the prior policy to ensure training stability. These methods often require computationally intensive non-linear optimization or require a particular form of action distribution. In this work, we show that applying KL penalization alone is nearly sufficient to enforce such trust regions. Then, we show that introducing a "fixup" phase is sufficient to guarantee a trust region is enforced on every policy update while adding fewer than 5% additional gradient steps in practice. The resulting algorithm, which we call FixPO, is able to train a variety of policy architectures and action spaces, is easy to implement, and produces results competitive with other trust region methods.
HyperPPO: A scalable method for finding small policies for robotic control
Sep 28, 2023



Models with fewer parameters are necessary for the neural control of memory-limited, performant robots. Finding these smaller neural network architectures can be time-consuming. We propose HyperPPO, an on-policy reinforcement learning algorithm that utilizes graph hypernetworks to estimate the weights of multiple neural architectures simultaneously. Our method estimates weights for networks that are much smaller than those in common-use networks yet encode highly performant policies. We obtain multiple trained policies at the same time while maintaining sample efficiency and provide the user the choice of picking a network architecture that satisfies their computational constraints. We show that our method scales well - more training resources produce faster convergence to higher-performing architectures. We demonstrate that the neural policies estimated by HyperPPO are capable of decentralized control of a Crazyflie2.1 quadrotor. Website: https://sites.google.com/usc.edu/hyperppo
Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
Sep 23, 2023End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
QuadSwarm: A Modular Multi-Quadrotor Simulator for Deep Reinforcement Learning with Direct Thrust Control
Jun 15, 2023Reinforcement learning (RL) has shown promise in creating robust policies for robotics tasks. However, contemporary RL algorithms are data-hungry, often requiring billions of environment transitions to train successful policies. This necessitates the use of fast and highly-parallelizable simulators. In addition to speed, such simulators need to model the physics of the robots and their interaction with the environment to a level acceptable for transferring policies learned in simulation to reality. We present QuadSwarm, a fast, reliable simulator for research in single and multi-robot RL for quadrotors that addresses both issues. QuadSwarm, with fast forward-dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. It provides multiple components tailored toward multi-robot RL, including diverse training scenarios, and provides domain randomization to facilitate the development and sim2real transfer of multi-quadrotor control policies. Initial experiments suggest that QuadSwarm achieves over 48,500 simulation samples per second (SPS) on a single quadrotor and over 62,000 SPS on eight quadrotors on a 16-core CPU. The code can be found in https://github.com/Zhehui-Huang/quad-swarm-rl.
Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement Learning
Sep 16, 2021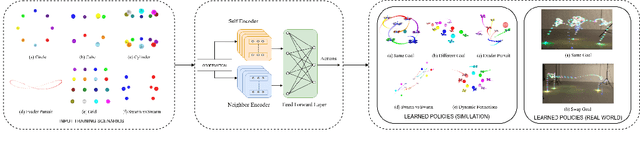
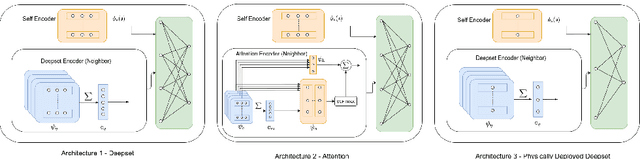

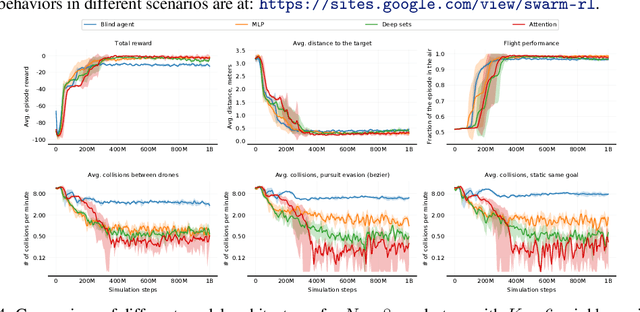
We demonstrate the possibility of learning drone swarm controllers that are zero-shot transferable to real quadrotors via large-scale multi-agent end-to-end reinforcement learning. We train policies parameterized by neural networks that are capable of controlling individual drones in a swarm in a fully decentralized manner. Our policies, trained in simulated environments with realistic quadrotor physics, demonstrate advanced flocking behaviors, perform aggressive maneuvers in tight formations while avoiding collisions with each other, break and re-establish formations to avoid collisions with moving obstacles, and efficiently coordinate in pursuit-evasion tasks. We analyze, in simulation, how different model architectures and parameters of the training regime influence the final performance of neural swarms. We demonstrate the successful deployment of the model learned in simulation to highly resource-constrained physical quadrotors performing stationkeeping and goal swapping behaviors. Code and video demonstrations are available at the project website https://sites.google.com/view/swarm-rl.
Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning
Jun 23, 2020
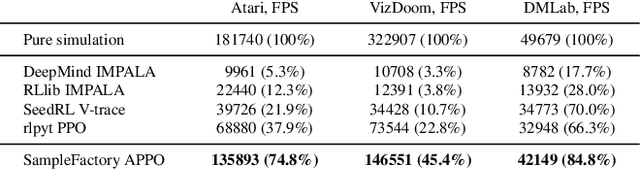


Increasing the scale of reinforcement learning experiments has allowed researchers to achieve unprecedented results in both training sophisticated agents for video games, and in sim-to-real transfer for robotics. Typically such experiments rely on large distributed systems and require expensive hardware setups, limiting wider access to this exciting area of research. In this work we aim to solve this problem by optimizing the efficiency and resource utilization of reinforcement learning algorithms instead of relying on distributed computation. We present the "Sample Factory", a high-throughput training system optimized for a single-machine setting. Our architecture combines a highly efficient, asynchronous, GPU-based sampler with off-policy correction techniques, allowing us to achieve throughput higher than $10^5$ environment frames/second on non-trivial control problems in 3D without sacrificing sample efficiency. We extend Sample Factory to support self-play and population-based training and apply these techniques to train highly capable agents for a multiplayer first-person shooter game. The source code is available at https://github.com/alex-petrenko/sample-factory