 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Signal Emitter Placement In Complex Environments
May 04, 2024Placement of electromagnetic signal emitting devices, such as light sources, has important usage in for signal coverage tasks. Automatic placement of these devices is challenging because of the complex interaction of the signal and environment due to reflection, refraction and scattering. In this work, we iteratively improve the placement of these devices by interleaving device placement and sensing actions, correcting errors in the model of the signal propagation. To this end, we propose a novel factor-graph based belief model which combines the measurements taken by the robot and an analytical light propagation model. This model allows accurately modelling the uncertainty of the light propagation with respect to the obstacles, which greatly improves the informative path planning routine. Additionally, we propose a method for determining when to re-plan the emitter placements to balance a trade-off between information about a specific configuration and frequent updating of the configuration. This method incorporates the uncertainty from belief model to adaptively determine when re-configuration is needed. We find that our system has a 9.8% median error reduction compared to a baseline system in simulations in the most difficult environment. We also run on-robot tests and determine that our system performs favorably compared to the baseline.
Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
Sep 23, 2023End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
MRNAV: Multi-Robot Aware Planning and Control Stack for Collision and Deadlock-free Navigation in Cluttered Environments
Aug 25, 2023Multi-robot collision-free and deadlock-free navigation in cluttered environments with static and dynamic obstacles is a fundamental problem for many applications. We introduce MRNAV, a framework for planning and control to effectively navigate in such environments. Our design utilizes short, medium, and long horizon decision making modules with qualitatively different properties, and defines the responsibilities of them. The decision making modules complement each other and provide the effective navigation capability. MRNAV is the first hierarchical approach combining these three levels of decision making modules and explicitly defining their responsibilities. We implement our design for simulated multi-quadrotor flight. In our evaluations, we show that all three modules are required for effective navigation in diverse situations. We show the long-term executability of our approach in an eight hour long wall time (six hour long simulation time) uninterrupted simulation without collisions or deadlocks.
DREAM: Decentralized Real-time Asynchronous Probabilistic Trajectory Planning for Collision-free Multi-Robot Navigation in Cluttered Environments
Jul 29, 2023


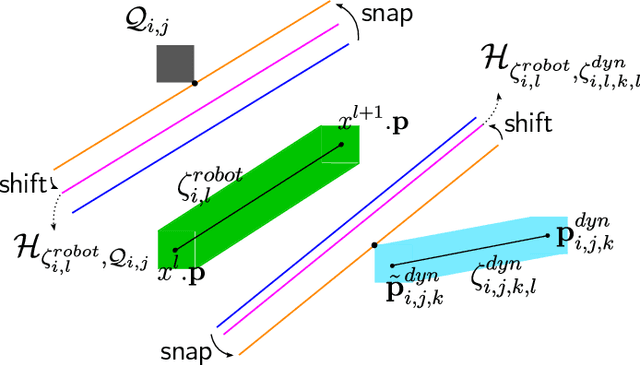
Collision-free navigation in cluttered environments with static and dynamic obstacles is essential for many multi-robot tasks. Dynamic obstacles may also be interactive, i.e., their behavior varies based on the behavior of other entities. We propose a novel representation for interactive behavior of dynamic obstacles and a decentralized real-time multi-robot trajectory planning algorithm allowing inter-robot collision and static and dynamic obstacle avoidance. Our planner simulates the behavior of dynamic obstacles during decision-making, accounting for interactivity. We account for the perception inaccuracy of static and prediction inaccuracy of dynamic obstacles. We handle asynchronous planning between teammates and message delays, drops, and re-orderings. We evaluate our algorithm in simulations using 25400 random cases and compare it against three state-of-the-art baselines using 2100 random cases. Our algorithm achieves up to 1.68x success rate using as low as 0.28x time in single-robot, and up to 2.15x success rate using as low as 0.36x time in multi-robot cases compared to the best baseline. We implement our planner on real quadrotors to show its real-world applicability.
RLSS: Real-time, Decentralized, Cooperative, Networkless Multi-Robot Trajectory Planning using Linear Spatial Separations
Feb 24, 2023Trajectory planning for multiple robots in shared environments is a challenging problem especially when there is limited communication available or no central entity. In this article, we present Real-time planning using Linear Spatial Separations, or RLSS: a real-time decentralized trajectory planning algorithm for cooperative multi-robot teams in static environments. The algorithm requires relatively few robot capabilities, namely sensing the positions of robots and obstacles without higher-order derivatives and the ability of distinguishing robots from obstacles. There is no communication requirement and the robots' dynamic limits are taken into account. RLSS generates and solves convex quadratic optimization problems that are kinematically feasible and guarantees collision avoidance if the resulting problems are feasible. We demonstrate the algorithm's performance in real-time in simulations and on physical robots. We compare RLSS to two state-of-the-art planners and show empirically that RLSS does avoid deadlocks and collisions in forest-like and maze-like environments, significantly improving prior work, which result in collisions and deadlocks in such environments.
Probabilistic Trajectory Planning for Static and Interaction-aware Dynamic Obstacle Avoidance
Feb 24, 2023



Collision-free mobile robot navigation is an important problem for many robotics applications, especially in cluttered environments. In such environments, obstacles can be static or dynamic. Dynamic obstacles can additionally be interactive, i.e. changing their behavior according to the behavior of other entities. The perception and prediction modules of robotic systems create probabilistic representations and predictions of such environments. In this paper, we propose a novel prediction representation for interactive behaviors of dynamic obstacles. Then, we propose a real-time trajectory planning algorithm that probabilistically avoids collisions against static and interactive dynamic obstacles, and produces dynamically feasible trajectories. During decision making, our planner simulates the interactive behavior of dynamic obstacles in response to the actions planning robot takes. We explicitly minimize collision probabilities against static and dynamic obstacles using a multi-objective search formulation. Then, we formulate a quadratic program to safely fit a smooth trajectory to the search result while attempting to preserve the collision probabilities computed during search. We evaluate our algorithm extensively in simulations to show its performance under different environments and configurations using 78000 randomly generated cases. We compare its performance to a state-of-the-art trajectory planning algorithm for static and dynamic obstacle avoidance using 4500 randomly generated cases. We show that our algorithm achieves up to 3.8x success rate using as low as 0.18x time the baseline uses. We implement our algorithm for physical quadrotors, and show its feasibility in the real world.
RLSS: Real-time Multi-Robot Trajectory Replanning using Linear Spatial Separations
Mar 13, 2021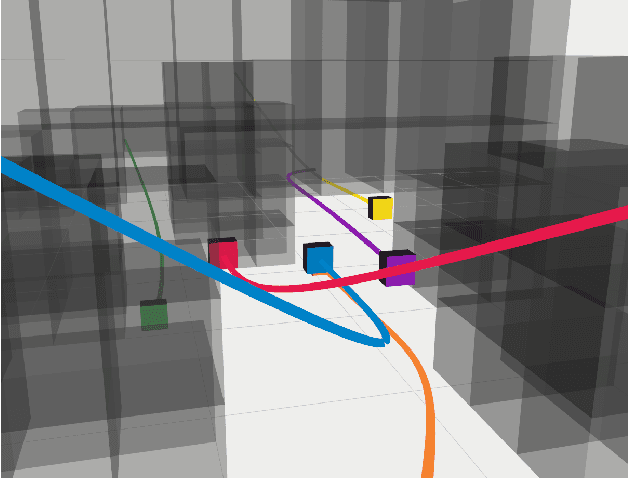
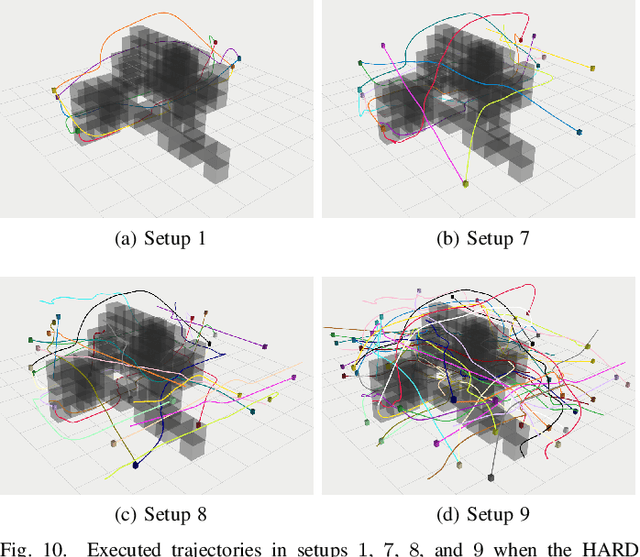
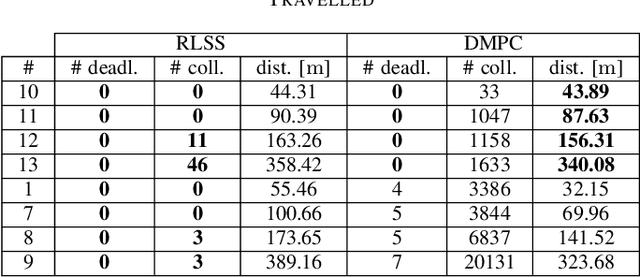
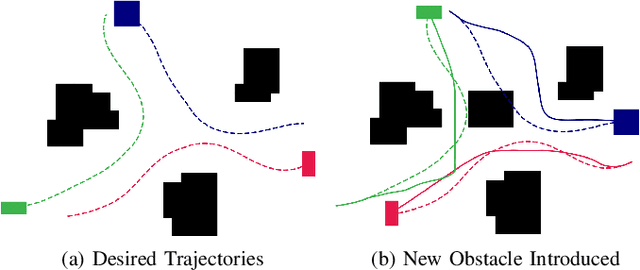
Trajectory replanning is a critical problem for multi-robot teams navigating dynamic environments. We present RLSS (Replanning using Linear Spatial Separations): a real-time trajectory replanning algorithm for cooperative multi-robot teams that uses linear spatial separations to enforce safety. Our algorithm handles the dynamic limits of the robots explicitly, is completely distributed, and is robust to environment changes, robot failures, and trajectory tracking errors. It requires no communication between robots and relies instead on local relative measurements only. We demonstrate that the algorithm works in real-time both in simulations and in experiments using physical robots. We compare our algorithm to a state-of-the-art online trajectory generation algorithm based on model predictive control, and show that our algorithm results in significantly fewer collisions in highly constrained environments, and effectively avoids deadlocks.