 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModTrack: Sensor-Agnostic Multi-View Tracking via Identity-Informed PHD Filtering with Covariance Propagation
Mar 16, 2026Multi-View Multi-Object Tracking (MV-MOT) aims to localize and maintain consistent identities of objects observed by multiple sensors. This task is challenging, as viewpoint changes and occlusion disrupt identity consistency across views and time. Recent end-to-end approaches address this by jointly learning 2D Bird's Eye View (BEV) representations and identity associations, achieving high tracking accuracy. However, these methods offer no principled uncertainty accounting and remain tightly coupled to their training configuration, limiting generalization across sensor layouts, modalities, or datasets without retraining. We propose ModTrack, a modular MV-MOT system that matches end-to-end performance while providing cross-modal, sensor-agnostic generalization and traceable uncertainty. ModTrack confines learning methods to just the \textit{Detection and Feature Extraction} stage of the MV-MOT pipeline, performing all fusion, association, and tracking with closed-form analytical methods. Our design reduces each sensor's output to calibrated position-covariance pairs $(\mathbf{z}, R)$; cross-view clustering and precision-weighted fusion then yield unified estimates $(\hat{\mathbf{z}}, \hat{R})$ for identity assignment and temporal tracking. A feedback-coupled, identity-informed Gaussian Mixture Probability Hypothesis Density (GM-PHD) filter with HMM motion modes uses these fused estimates to maintain identities under missed detections and heavy occlusion. ModTrack achieves 95.5 IDF1 and 91.4 MOTA on \textit{WildTrack}, surpassing all prior modular methods by over 21 points and rivaling the state-of-the-art end-to-end methods while providing deployment flexibility they cannot. Specifically, the same tracker core transfers unchanged to \textit{MultiviewX} and \textit{RadarScenes}, with only perception-module replacement required to extend to new domains and sensor modalities.
Multi-Agent Path Finding Among Dynamic Uncontrollable Agents with Statistical Safety Guarantees
Jul 29, 2025



Existing multi-agent path finding (MAPF) solvers do not account for uncertain behavior of uncontrollable agents. We present a novel variant of Enhanced Conflict-Based Search (ECBS), for both one-shot and lifelong MAPF in dynamic environments with uncontrollable agents. Our method consists of (1) training a learned predictor for the movement of uncontrollable agents, (2) quantifying the prediction error using conformal prediction (CP), a tool for statistical uncertainty quantification, and (3) integrating these uncertainty intervals into our modified ECBS solver. Our method can account for uncertain agent behavior, comes with statistical guarantees on collision-free paths for one-shot missions, and scales to lifelong missions with a receding horizon sequence of one-shot instances. We run our algorithm, CP-Solver, across warehouse and game maps, with competitive throughput and reduced collisions.
Robust Trajectory Generation and Control for Quadrotor Motion Planning with Field-of-View Control Barrier Certification
Feb 03, 2025
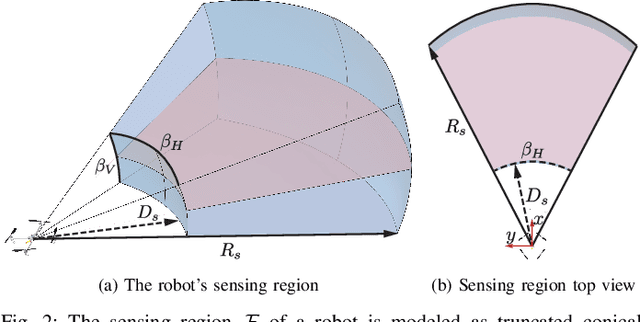
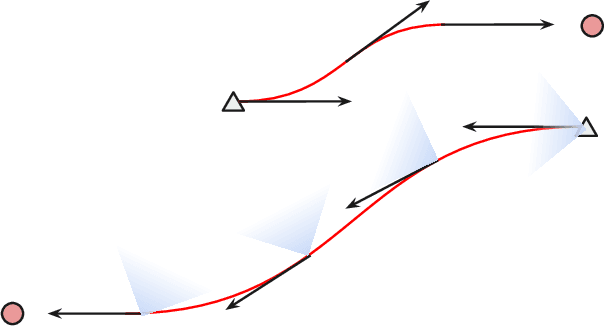
Many approaches to multi-robot coordination are susceptible to failure due to communication loss and uncertainty in estimation. We present a real-time communication-free distributed algorithm for navigating robots to their desired goals certified by control barrier functions, that model and control the onboard sensing behavior to keep neighbors in the limited field of view for position estimation. The approach is robust to temporary tracking loss and directly synthesizes control in real time to stabilize visual contact through control Lyapunov-barrier functions. The main contributions of this paper are a continuous-time robust trajectory generation and control method certified by control barrier functions for distributed multi-robot systems and a discrete optimization procedure, namely, MPC-CBF, to approximate the certified controller. In addition, we propose a linear surrogate of high-order control barrier function constraints and use sequential quadratic programming to solve MPC-CBF efficiently. We demonstrate results in simulation with 10 robots and physical experiments with 2 custom-built UAVs. To the best of our knowledge, this work is the first of its kind to generate a robust continuous-time trajectory and controller concurrently, certified by control barrier functions utilizing piecewise splines.
Hierarchical Trajectory (Re)Planning for a Large Scale Swarm
Jan 28, 2025
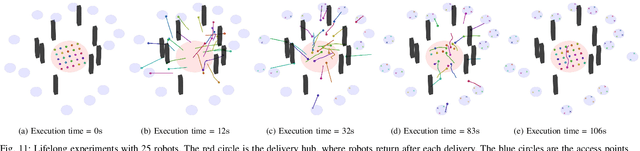
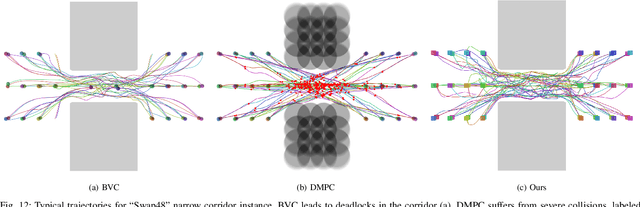
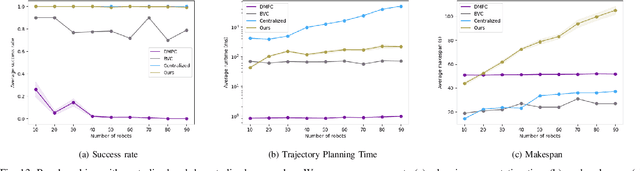
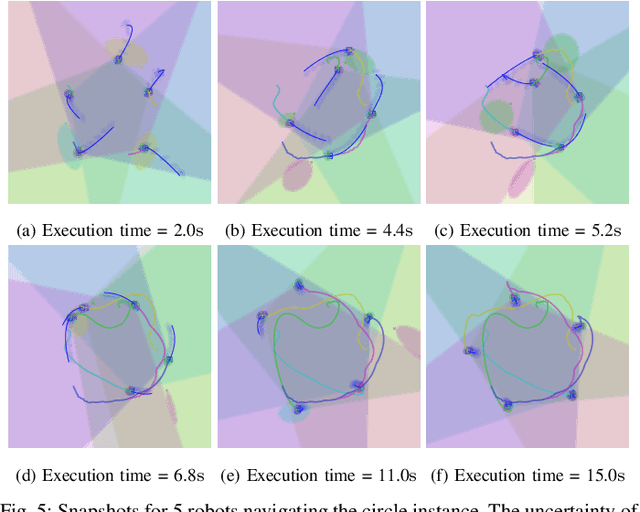
We consider the trajectory replanning problem for a large-scale swarm in a cluttered environment. Our path planner replans for robots by utilizing a hierarchical approach, dividing the workspace, and computing collision-free paths for robots within each cell in parallel. Distributed trajectory optimization generates a deadlock-free trajectory for efficient execution and maintains the control feasibility even when the optimization fails. Our hierarchical approach combines the benefits of both centralized and decentralized methods, achieving a high task success rate while providing real-time replanning capability. Compared to decentralized approaches, our approach effectively avoids deadlocks and collisions, significantly increasing the task success rate. We demonstrate the real-time performance of our algorithm with up to 142 robots in simulation, and a representative 24 physical Crazyflie nano-quadrotor experiment.
Hierarchical Large Scale Multirobot Path (Re)Planning
Jul 03, 2024We consider a large-scale multi-robot path planning problem in a cluttered environment. Our approach achieves real-time replanning by dividing the workspace into cells and utilizing a hierarchical planner. Specifically, multi-commodity flow-based high-level planners route robots through the cells to reduce congestion, while an anytime low-level planner computes collision-free paths for robots within each cell in parallel. Despite resulting in longer paths compared to the baseline multi-agent pathfinding algorithm, our method produces a solution with significant improvement in computation time. Specifically, we show empirical results of a 500-times speedup in computation time compared to the baseline multi-agent pathfinding approach on the environments we study. We account for the robot's embodiment and support non-stop execution when replanning continuously. We demonstrate the real-time performance of our algorithm with up to 142 robots in simulation, and a representative 32 physical Crazyflie nano-quadrotor experiment.
FireFly A Synthetic Dataset for Ember Detection in Wildfire
Aug 06, 2023This paper presents "FireFly", a synthetic dataset for ember detection created using Unreal Engine 4 (UE4), designed to overcome the current lack of ember-specific training resources. To create the dataset, we present a tool that allows the automated generation of the synthetic labeled dataset with adjustable parameters, enabling data diversity from various environmental conditions, making the dataset both diverse and customizable based on user requirements. We generated a total of 19,273 frames that have been used to evaluate FireFly on four popular object detection models. Further to minimize human intervention, we leveraged a trained model to create a semi-automatic labeling process for real-life ember frames. Moreover, we demonstrated an up to 8.57% improvement in mean Average Precision (mAP) in real-world wildfire scenarios compared to models trained exclusively on a small real dataset.
Conformal Predictive Safety Filter for RL Controllers in Dynamic Environments
Jun 05, 2023



The interest in using reinforcement learning (RL) controllers in safety-critical applications such as robot navigation around pedestrians motivates the development of additional safety mechanisms. Running RL-enabled systems among uncertain dynamic agents may result in high counts of collisions and failures to reach the goal. The system could be safer if the pre-trained RL policy was uncertainty-informed. For that reason, we propose conformal predictive safety filters that: 1) predict the other agents' trajectories, 2) use statistical techniques to provide uncertainty intervals around these predictions, and 3) learn an additional safety filter that closely follows the RL controller but avoids the uncertainty intervals. We use conformal prediction to learn uncertainty-informed predictive safety filters, which make no assumptions about the agents' distribution. The framework is modular and outperforms the existing controllers in simulation. We demonstrate our approach with multiple experiments in a collision avoidance gym environment and show that our approach minimizes the number of collisions without making overly-conservative predictions.
RLSS: Real-time, Decentralized, Cooperative, Networkless Multi-Robot Trajectory Planning using Linear Spatial Separations
Feb 24, 2023Trajectory planning for multiple robots in shared environments is a challenging problem especially when there is limited communication available or no central entity. In this article, we present Real-time planning using Linear Spatial Separations, or RLSS: a real-time decentralized trajectory planning algorithm for cooperative multi-robot teams in static environments. The algorithm requires relatively few robot capabilities, namely sensing the positions of robots and obstacles without higher-order derivatives and the ability of distinguishing robots from obstacles. There is no communication requirement and the robots' dynamic limits are taken into account. RLSS generates and solves convex quadratic optimization problems that are kinematically feasible and guarantees collision avoidance if the resulting problems are feasible. We demonstrate the algorithm's performance in real-time in simulations and on physical robots. We compare RLSS to two state-of-the-art planners and show empirically that RLSS does avoid deadlocks and collisions in forest-like and maze-like environments, significantly improving prior work, which result in collisions and deadlocks in such environments.
RLSS: Real-time Multi-Robot Trajectory Replanning using Linear Spatial Separations
Mar 13, 2021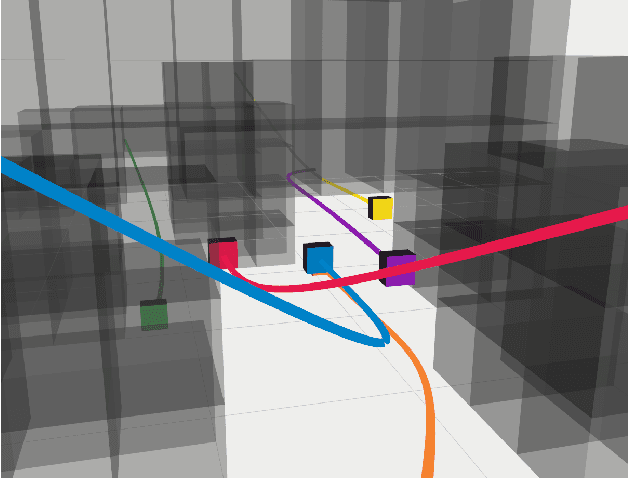
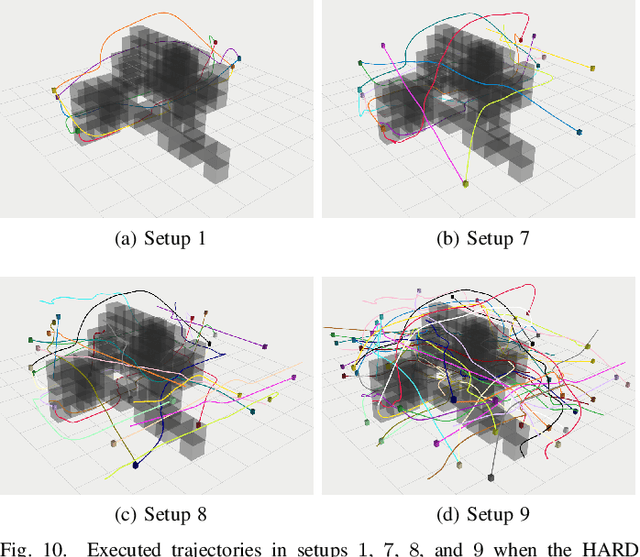
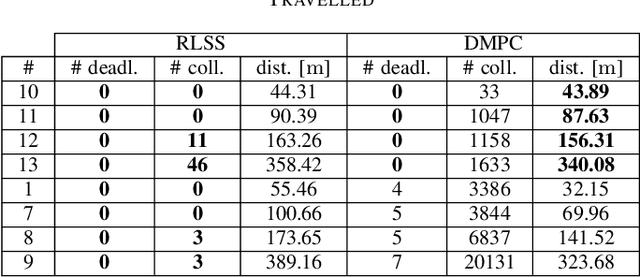
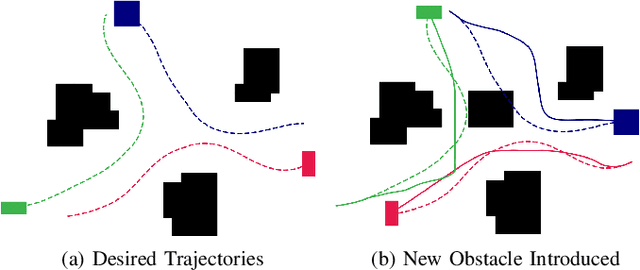
Trajectory replanning is a critical problem for multi-robot teams navigating dynamic environments. We present RLSS (Replanning using Linear Spatial Separations): a real-time trajectory replanning algorithm for cooperative multi-robot teams that uses linear spatial separations to enforce safety. Our algorithm handles the dynamic limits of the robots explicitly, is completely distributed, and is robust to environment changes, robot failures, and trajectory tracking errors. It requires no communication between robots and relies instead on local relative measurements only. We demonstrate that the algorithm works in real-time both in simulations and in experiments using physical robots. We compare our algorithm to a state-of-the-art online trajectory generation algorithm based on model predictive control, and show that our algorithm results in significantly fewer collisions in highly constrained environments, and effectively avoids deadlocks.
MAPFAST: A Deep Algorithm Selector for Multi Agent Path Finding using Shortest Path Embeddings
Feb 24, 2021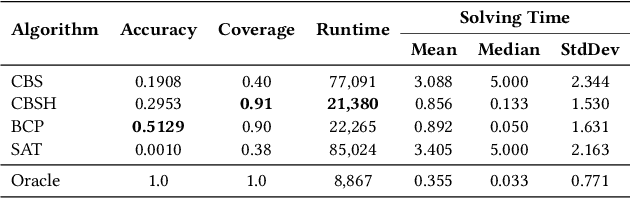
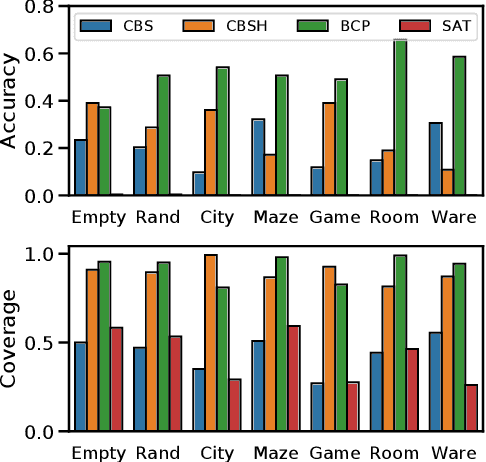
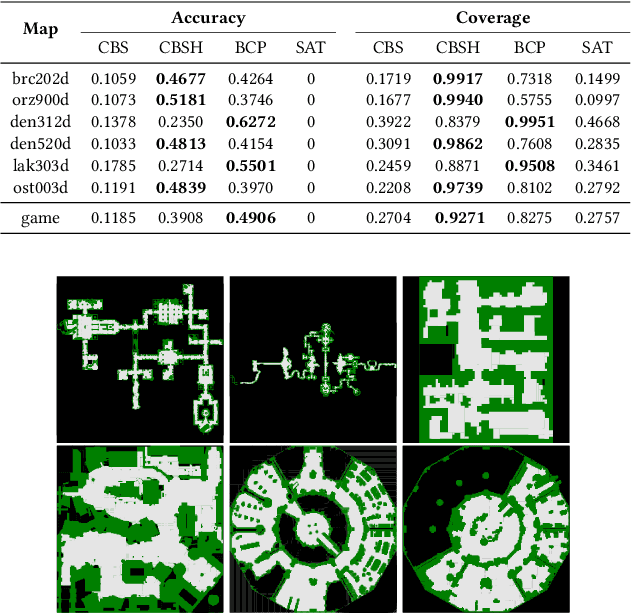
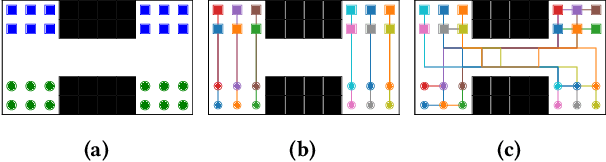
Solving the Multi-Agent Path Finding (MAPF) problem optimally is known to be NP-Hard for both make-span and total arrival time minimization. While many algorithms have been developed to solve MAPF problems, there is no dominating optimal MAPF algorithm that works well in all types of problems and no standard guidelines for when to use which algorithm. In this work, we develop the deep convolutional network MAPFAST (Multi-Agent Path Finding Algorithm SelecTor), which takes a MAPF problem instance and attempts to select the fastest algorithm to use from a portfolio of algorithms. We improve the performance of our model by including single-agent shortest paths in the instance embedding given to our model and by utilizing supplemental loss functions in addition to a classification loss. We evaluate our model on a large and diverse dataset of MAPF instances, showing that it outperforms all individual algorithms in its portfolio as well as the state-of-the-art optimal MAPF algorithm selector. We also provide an analysis of algorithm behavior in our dataset to gain a deeper understanding of optimal MAPF algorithms' strengths and weaknesses to help other researchers leverage different heuristics in algorithm designs.