 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Shortcuts to Reasoning: Robust Post-Training of Theory of Mind with Reinforcement Learning
Jun 08, 2026Theory of Mind (ToM) is a must-acquire skill for modern foundation model systems to operate effectively and safely in the real world. Recent works have explored honing ToM via post-training; however, we show that such progress is confounded by a pervasive "shortcut" issue: tasks can reach up to 99% accuracy by simply exploiting spurious causal correlations, leading to a false sense of ToM. Motivated by this, we first develop a framework to systematically examine ToM datasets for shortcuts and provide guidance for future development. We find that questions reducible to pure state tracking, such as "belief," are especially shortcut-prone compared to mind questions, such as "intention," where reasoning beyond tracking is required. Using four shortcut-free datasets across three ToM contexts, we then comprehensively study whether Reinforcement Fine-Tuning with verifiable rewards and explicit reasoning chains, called Thinking-RFT, elevates ToM beyond Supervised Fine-Tuning, or SFT. Our key findings are as follows. First, Thinking-RFT effectively improves ToM in all scenarios, with a 6% improvement over SFT, particularly in complex higher-order reasoning, with a 10% improvement over SFT, and multimodal cases, with a 7% improvement over SFT. It also generalizes notably better to unseen domains and higher-order queries while being more robust to counterfactuals. Second, ToM benefits specifically from the joint effect of reasoning and RL: Thinking-RFT outperforms Non-Thinking-RFT by 7% on average. Third, RFT works by learning to ground its reasoning on anchor cues, such as keywords and state changes, that correspond to causal factors. We believe our study is useful for developing effective and robust ToM post-training datasets and advancing critical ToM capabilities.
Agent-Sentry: Bounding LLM Agents via Execution Provenance
Mar 24, 2026Agentic computing systems, which autonomously spawn new functionalities based on natural language instructions, are becoming increasingly prevalent. While immensely capable, these systems raise serious security, privacy, and safety concerns. Fundamentally, the full set of functionalities offered by these systems, combined with their probabilistic execution flows, is not known beforehand. Given this lack of characterization, it is non-trivial to validate whether a system has successfully carried out the user's intended task or instead executed irrelevant actions, potentially as a consequence of compromise. In this paper, we propose Agent-Sentry, a framework that attempts to bound agentic systems to address this problem. Our key insight is that agentic systems are designed for specific use cases and therefore need not expose unbounded or unspecified functionalities. Once bounded, these systems become easier to scrutinize. Agent-Sentry operationalizes this insight by uncovering frequent functionalities offered by an agentic system, along with their execution traces, to construct behavioral bounds. It then learns a policy from these traces and blocks tool calls that deviate from learned behaviors or that misalign with user intent. Our evaluation shows that Agent-Sentry helps prevent over 90\% of attacks that attempt to trigger out-of-bounds executions, while preserving up to 98\% of system utility.
VRIQ: Benchmarking and Analyzing Visual-Reasoning IQ of VLMs
Feb 05, 2026Recent progress in Vision Language Models (VLMs) has raised the question of whether they can reliably perform nonverbal reasoning. To this end, we introduce VRIQ (Visual Reasoning IQ), a novel benchmark designed to assess and analyze the visual reasoning ability of VLMs. We evaluate models on two sets of tasks: abstract puzzle-style and natural-image reasoning tasks. We find that on abstract puzzles, performance remains near random with an average accuracy of around 28%, while natural tasks yield better but still weak results with 45% accuracy. We also find that tool-augmented reasoning demonstrates only modest improvements. To uncover the source of this weakness, we introduce diagnostic probes targeting perception and reasoning. Our analysis demonstrates that around 56% of failures arise from perception alone, 43% from both perception and reasoning, and only a mere 1% from reasoning alone. This motivates us to design fine-grained diagnostic probe questions targeting specific perception categories (e.g., shape, count, position, 3D/depth), revealing that certain categories cause more failures than others. Our benchmark and analysis establish that current VLMs, even with visual reasoning tools, remain unreliable abstract reasoners, mostly due to perception limitations, and offer a principled basis for improving visual reasoning in multimodal systems.
Preserving Privacy and Utility in LLM-Based Product Recommendations
May 02, 2025Large Language Model (LLM)-based recommendation systems leverage powerful language models to generate personalized suggestions by processing user interactions and preferences. Unlike traditional recommendation systems that rely on structured data and collaborative filtering, LLM-based models process textual and contextual information, often using cloud-based infrastructure. This raises privacy concerns, as user data is transmitted to remote servers, increasing the risk of exposure and reducing control over personal information. To address this, we propose a hybrid privacy-preserving recommendation framework which separates sensitive from nonsensitive data and only shares the latter with the cloud to harness LLM-powered recommendations. To restore lost recommendations related to obfuscated sensitive data, we design a de-obfuscation module that reconstructs sensitive recommendations locally. Experiments on real-world e-commerce datasets show that our framework achieves almost the same recommendation utility with a system which shares all data with an LLM, while preserving privacy to a large extend. Compared to obfuscation-only techniques, our approach improves HR@10 scores and category distribution alignment, offering a better balance between privacy and recommendation quality. Furthermore, our method runs efficiently on consumer-grade hardware, making privacy-aware LLM-based recommendation systems practical for real-world use.
SpinML: Customized Synthetic Data Generation for Private Training of Specialized ML Models
Mar 05, 2025Specialized machine learning (ML) models tailored to users needs and requests are increasingly being deployed on smart devices with cameras, to provide personalized intelligent services taking advantage of camera data. However, two primary challenges hinder the training of such models: the lack of publicly available labeled data suitable for specialized tasks and the inaccessibility of labeled private data due to concerns about user privacy. To address these challenges, we propose a novel system SpinML, where the server generates customized Synthetic image data to Privately traIN a specialized ML model tailored to the user request, with the usage of only a few sanitized reference images from the user. SpinML offers users fine-grained, object-level control over the reference images, which allows user to trade between the privacy and utility of the generated synthetic data according to their privacy preferences. Through experiments on three specialized model training tasks, we demonstrate that our proposed system can enhance the performance of specialized models without compromising users privacy preferences.
EEE-Bench: A Comprehensive Multimodal Electrical And Electronics Engineering Benchmark
Nov 03, 2024Recent studies on large language models (LLMs) and large multimodal models (LMMs) have demonstrated promising skills in various domains including science and mathematics. However, their capability in more challenging and real-world related scenarios like engineering has not been systematically studied. To bridge this gap, we propose EEE-Bench, a multimodal benchmark aimed at assessing LMMs' capabilities in solving practical engineering tasks, using electrical and electronics engineering (EEE) as the testbed. Our benchmark consists of 2860 carefully curated problems spanning 10 essential subdomains such as analog circuits, control systems, etc. Compared to benchmarks in other domains, engineering problems are intrinsically 1) more visually complex and versatile and 2) less deterministic in solutions. Successful solutions to these problems often demand more-than-usual rigorous integration of visual and textual information as models need to understand intricate images like abstract circuits and system diagrams while taking professional instructions, making them excellent candidates for LMM evaluations. Alongside EEE-Bench, we provide extensive quantitative evaluations and fine-grained analysis of 17 widely-used open and closed-sourced LLMs and LMMs. Our results demonstrate notable deficiencies of current foundation models in EEE, with an average performance ranging from 19.48% to 46.78%. Finally, we reveal and explore a critical shortcoming in LMMs which we term laziness: the tendency to take shortcuts by relying on the text while overlooking the visual context when reasoning for technical image problems. In summary, we believe EEE-Bench not only reveals some noteworthy limitations of LMMs but also provides a valuable resource for advancing research on their application in practical engineering tasks, driving future improvements in their capability to handle complex, real-world scenarios.
Efficient Toxic Content Detection by Bootstrapping and Distilling Large Language Models
Dec 13, 2023Toxic content detection is crucial for online services to remove inappropriate content that violates community standards. To automate the detection process, prior works have proposed varieties of machine learning (ML) approaches to train Language Models (LMs) for toxic content detection. However, both their accuracy and transferability across datasets are limited. Recently, Large Language Models (LLMs) have shown promise in toxic content detection due to their superior zero-shot and few-shot in-context learning ability as well as broad transferability on ML tasks. However, efficiently designing prompts for LLMs remains challenging. Moreover, the high run-time cost of LLMs may hinder their deployments in production. To address these challenges, in this work, we propose BD-LLM, a novel and efficient approach to Bootstrapping and Distilling LLMs for toxic content detection. Specifically, we design a novel prompting method named Decision-Tree-of-Thought (DToT) to bootstrap LLMs' detection performance and extract high-quality rationales. DToT can automatically select more fine-grained context to re-prompt LLMs when their responses lack confidence. Additionally, we use the rationales extracted via DToT to fine-tune student LMs. Our experimental results on various datasets demonstrate that DToT can improve the accuracy of LLMs by up to 4.6%. Furthermore, student LMs fine-tuned with rationales extracted via DToT outperform baselines on all datasets with up to 16.9\% accuracy improvement, while being more than 60x smaller than conventional LLMs. Finally, we observe that student LMs fine-tuned with rationales exhibit better cross-dataset transferability.
FireFly A Synthetic Dataset for Ember Detection in Wildfire
Aug 06, 2023This paper presents "FireFly", a synthetic dataset for ember detection created using Unreal Engine 4 (UE4), designed to overcome the current lack of ember-specific training resources. To create the dataset, we present a tool that allows the automated generation of the synthetic labeled dataset with adjustable parameters, enabling data diversity from various environmental conditions, making the dataset both diverse and customizable based on user requirements. We generated a total of 19,273 frames that have been used to evaluate FireFly on four popular object detection models. Further to minimize human intervention, we leveraged a trained model to create a semi-automatic labeling process for real-life ember frames. Moreover, we demonstrated an up to 8.57% improvement in mean Average Precision (mAP) in real-world wildfire scenarios compared to models trained exclusively on a small real dataset.
How Much Privacy Does Federated Learning with Secure Aggregation Guarantee?
Aug 03, 2022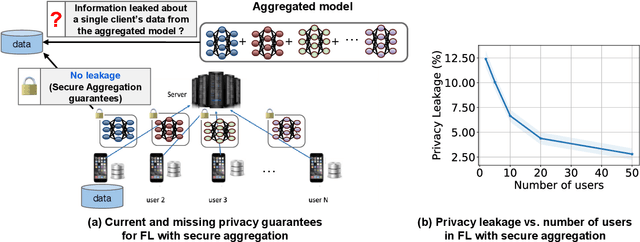
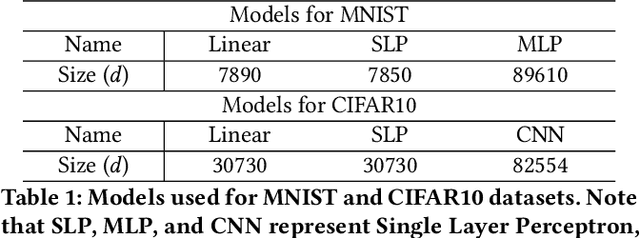
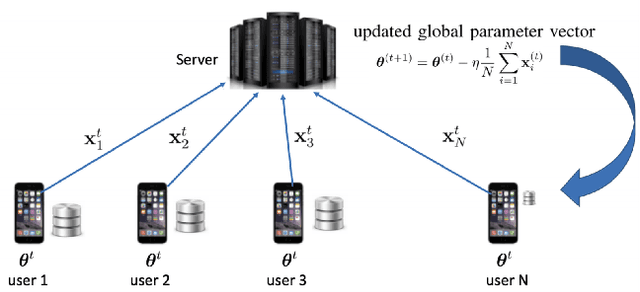
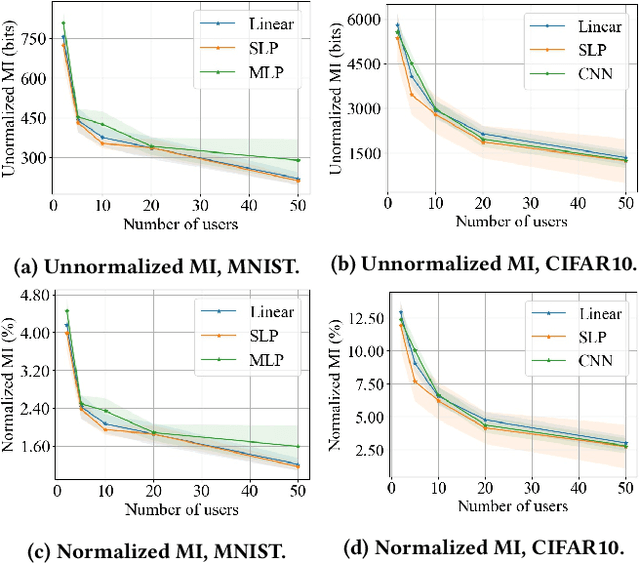
Federated learning (FL) has attracted growing interest for enabling privacy-preserving machine learning on data stored at multiple users while avoiding moving the data off-device. However, while data never leaves users' devices, privacy still cannot be guaranteed since significant computations on users' training data are shared in the form of trained local models. These local models have recently been shown to pose a substantial privacy threat through different privacy attacks such as model inversion attacks. As a remedy, Secure Aggregation (SA) has been developed as a framework to preserve privacy in FL, by guaranteeing the server can only learn the global aggregated model update but not the individual model updates. While SA ensures no additional information is leaked about the individual model update beyond the aggregated model update, there are no formal guarantees on how much privacy FL with SA can actually offer; as information about the individual dataset can still potentially leak through the aggregated model computed at the server. In this work, we perform a first analysis of the formal privacy guarantees for FL with SA. Specifically, we use Mutual Information (MI) as a quantification metric and derive upper bounds on how much information about each user's dataset can leak through the aggregated model update. When using the FedSGD aggregation algorithm, our theoretical bounds show that the amount of privacy leakage reduces linearly with the number of users participating in FL with SA. To validate our theoretical bounds, we use an MI Neural Estimator to empirically evaluate the privacy leakage under different FL setups on both the MNIST and CIFAR10 datasets. Our experiments verify our theoretical bounds for FedSGD, which show a reduction in privacy leakage as the number of users and local batch size grow, and an increase in privacy leakage with the number of training rounds.
A Unified Prediction Framework for Signal Maps
Feb 12, 2022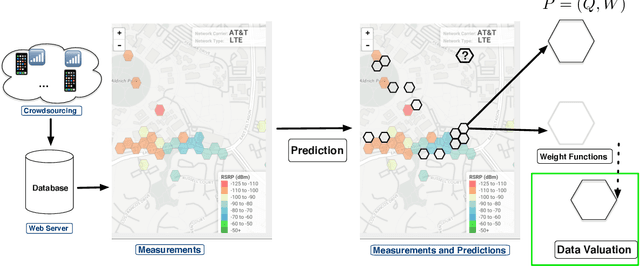
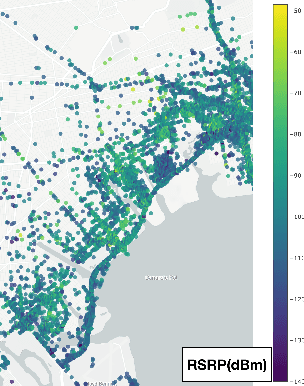
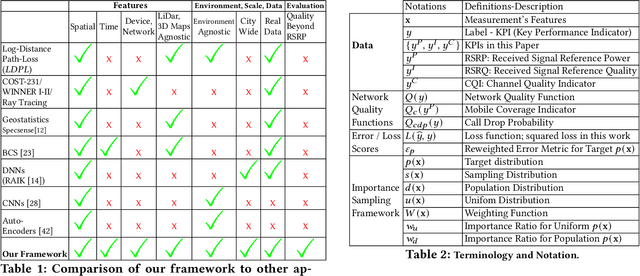

Signal maps are essential for the planning and operation of cellular networks. However, the measurements needed to create such maps are expensive, often biased, not always reflecting the metrics of interest, and posing privacy risks. In this paper, we develop a unified framework for predicting cellular signal maps from limited measurements. Our framework builds on a state-of-the-art random-forest predictor, or any other base predictor. We propose and combine three mechanisms that deal with the fact that not all measurements are equally important for a particular prediction task. First, we design quality-of-service functions ($Q$), including signal strength (RSRP) but also other metrics of interest to operators, i.e., coverage and call drop probability. By implicitly altering the loss function employed in learning, quality functions can also improve prediction for RSRP itself where it matters (e.g., MSE reduction up to 27% in the low signal strength regime, where errors are critical). Second, we introduce weight functions ($W$) to specify the relative importance of prediction at different locations and other parts of the feature space. We propose re-weighting based on importance sampling to obtain unbiased estimators when the sampling and target distributions are different. This yields improvements up to 20% for targets based on spatially uniform loss or losses based on user population density. Third, we apply the Data Shapley framework for the first time in this context: to assign values ($\phi$) to individual measurement points, which capture the importance of their contribution to the prediction task. This improves prediction (e.g., from 64% to 94% in recall for coverage loss) by removing points with negative values, and can also enable data minimization. We evaluate our methods and demonstrate significant improvement in prediction performance, using several real-world datasets.