 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoLike: Auditing Social Media Recommendations through User Interactions
Feb 13, 2025Modern social media platforms, such as TikTok, Facebook, and YouTube, rely on recommendation systems to personalize content for users based on user interactions with endless streams of content, such as "For You" pages. However, these complex algorithms can inadvertently deliver problematic content related to self-harm, mental health, and eating disorders. We introduce AutoLike, a framework to audit recommendation systems in social media platforms for topics of interest and their sentiments. To automate the process, we formulate the problem as a reinforcement learning problem. AutoLike drives the recommendation system to serve a particular type of content through interactions (e.g., liking). We apply the AutoLike framework to the TikTok platform as a case study. We evaluate how well AutoLike identifies TikTok content automatically across nine topics of interest; and conduct eight experiments to demonstrate how well it drives TikTok's recommendation system towards particular topics and sentiments. AutoLike has the potential to assist regulators in auditing recommendation systems for problematic content. (Warning: This paper contains qualitative examples that may be viewed as offensive or harmful.)
Maverick-Aware Shapley Valuation for Client Selection in Federated Learning
May 21, 2024



Federated Learning (FL) allows clients to train a model collaboratively without sharing their private data. One key challenge in practical FL systems is data heterogeneity, particularly in handling clients with rare data, also referred to as Mavericks. These clients own one or more data classes exclusively, and the model performance becomes poor without their participation. Thus, utilizing Mavericks throughout training is crucial. In this paper, we first design a Maverick-aware Shapley valuation that fairly evaluates the contribution of Mavericks. The main idea is to compute the clients' Shapley values (SV) class-wise, i.e., per label. Next, we propose FedMS, a Maverick-Shapley client selection mechanism for FL that intelligently selects the clients that contribute the most in each round, by employing our Maverick-aware SV-based contribution score. We show that, compared to an extensive list of baselines, FedMS achieves better model performance and fairer Shapley Rewards distribution.
PriPrune: Quantifying and Preserving Privacy in Pruned Federated Learning
Oct 30, 2023



Federated learning (FL) is a paradigm that allows several client devices and a server to collaboratively train a global model, by exchanging only model updates, without the devices sharing their local training data. These devices are often constrained in terms of communication and computation resources, and can further benefit from model pruning -- a paradigm that is widely used to reduce the size and complexity of models. Intuitively, by making local models coarser, pruning is expected to also provide some protection against privacy attacks in the context of FL. However this protection has not been previously characterized, formally or experimentally, and it is unclear if it is sufficient against state-of-the-art attacks. In this paper, we perform the first investigation of privacy guarantees for model pruning in FL. We derive information-theoretic upper bounds on the amount of information leaked by pruned FL models. We complement and validate these theoretical findings, with comprehensive experiments that involve state-of-the-art privacy attacks, on several state-of-the-art FL pruning schemes, using benchmark datasets. This evaluation provides valuable insights into the choices and parameters that can affect the privacy protection provided by pruning. Based on these insights, we introduce PriPrune -- a privacy-aware algorithm for local model pruning, which uses a personalized per-client defense mask and adapts the defense pruning rate so as to jointly optimize privacy and model performance. PriPrune is universal in that can be applied after any pruned FL scheme on the client, without modification, and protects against any inversion attack by the server. Our empirical evaluation demonstrates that PriPrune significantly improves the privacy-accuracy tradeoff compared to state-of-the-art pruned FL schemes that do not take privacy into account.
AutoFR: Automated Filter Rule Generation for Adblocking
Feb 25, 2022

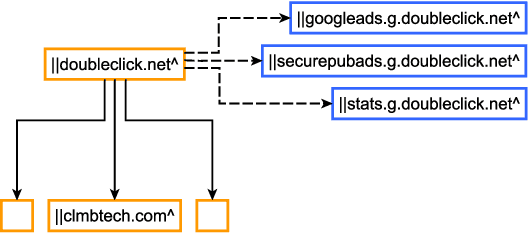

Adblocking relies on filter lists, which are manually curated and maintained by a small community of filter list authors. This manual process is laborious and does not scale well to a large number of sites and over time. We introduce AutoFR, a reinforcement learning framework to fully automate the process of filter rule creation and evaluation. We design an algorithm based on multi-arm bandits to generate filter rules while controlling the trade-off between blocking ads and avoiding breakage. We test our implementation of AutoFR on thousands of sites in terms of efficiency and effectiveness. AutoFR is efficient: it takes only a few minutes to generate filter rules for a site. AutoFR is also effective: it generates filter rules that can block 86% of the ads, as compared to 87% by EasyList while achieving comparable visual breakage. The filter rules generated by AutoFR generalize well to new and unseen sites. We envision AutoFR to assist the adblocking community in automated filter rule generation at scale.
A Unified Prediction Framework for Signal Maps
Feb 12, 2022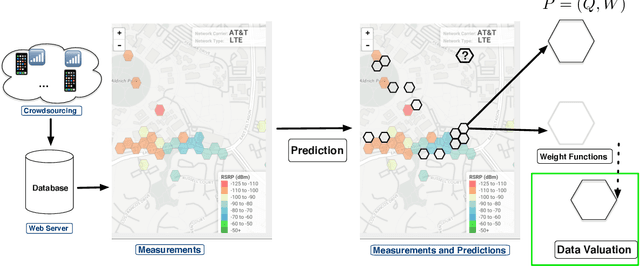
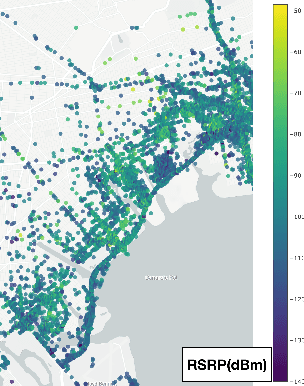
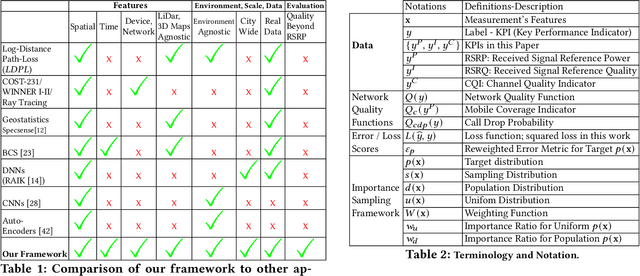

Signal maps are essential for the planning and operation of cellular networks. However, the measurements needed to create such maps are expensive, often biased, not always reflecting the metrics of interest, and posing privacy risks. In this paper, we develop a unified framework for predicting cellular signal maps from limited measurements. Our framework builds on a state-of-the-art random-forest predictor, or any other base predictor. We propose and combine three mechanisms that deal with the fact that not all measurements are equally important for a particular prediction task. First, we design quality-of-service functions ($Q$), including signal strength (RSRP) but also other metrics of interest to operators, i.e., coverage and call drop probability. By implicitly altering the loss function employed in learning, quality functions can also improve prediction for RSRP itself where it matters (e.g., MSE reduction up to 27% in the low signal strength regime, where errors are critical). Second, we introduce weight functions ($W$) to specify the relative importance of prediction at different locations and other parts of the feature space. We propose re-weighting based on importance sampling to obtain unbiased estimators when the sampling and target distributions are different. This yields improvements up to 20% for targets based on spatially uniform loss or losses based on user population density. Third, we apply the Data Shapley framework for the first time in this context: to assign values ($\phi$) to individual measurement points, which capture the importance of their contribution to the prediction task. This improves prediction (e.g., from 64% to 94% in recall for coverage loss) by removing points with negative values, and can also enable data minimization. We evaluate our methods and demonstrate significant improvement in prediction performance, using several real-world datasets.
Location Leakage in Federated Signal Maps
Dec 07, 2021

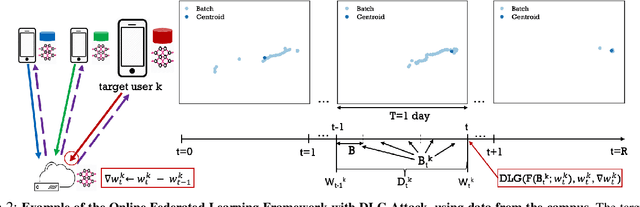

We consider the problem of predicting cellular network performance (signal maps) from measurements collected by several mobile devices. We formulate the problem within the online federated learning framework: (i) federated learning (FL) enables users to collaboratively train a model, while keeping their training data on their devices; (ii) measurements are collected as users move around over time and are used for local training in an online fashion. We consider an honest-but-curious server, who observes the updates from target users participating in FL and infers their location using a deep leakage from gradients (DLG) type of attack, originally developed to reconstruct training data of DNN image classifiers. We make the key observation that a DLG attack, applied to our setting, infers the average location of a batch of local data, and can thus be used to reconstruct the target users' trajectory at a coarse granularity. We show that a moderate level of privacy protection is already offered by the averaging of gradients, which is inherent to Federated Averaging. Furthermore, we propose an algorithm that devices can apply locally to curate the batches used for local updates, so as to effectively protect their location privacy without hurting utility. Finally, we show that the effect of multiple users participating in FL depends on the similarity of their trajectories. To the best of our knowledge, this is the first study of DLG attacks in the setting of FL from crowdsourced spatio-temporal data.
PingPong: Packet-Level Signatures for Smart Home Device Events
Sep 17, 2019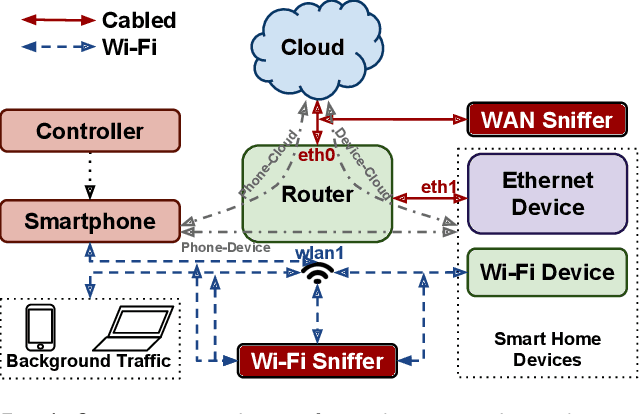
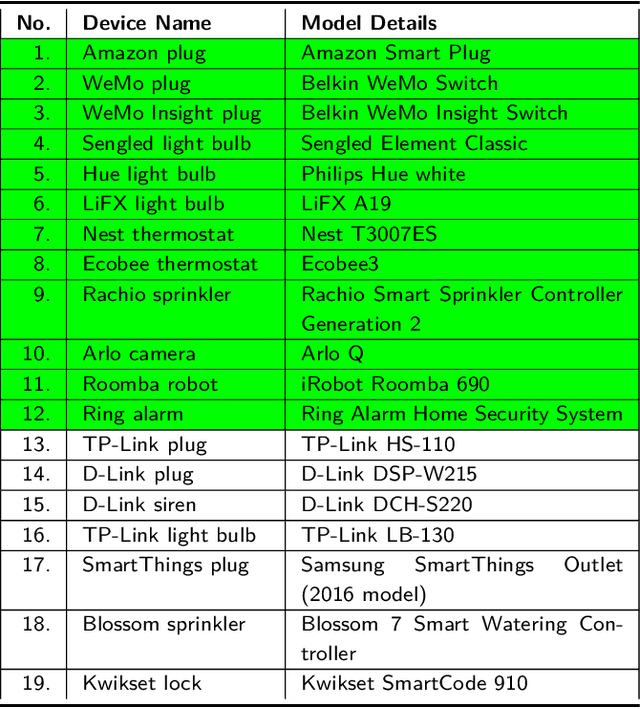
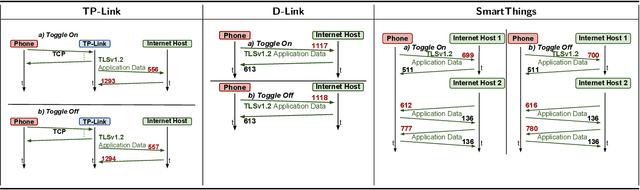
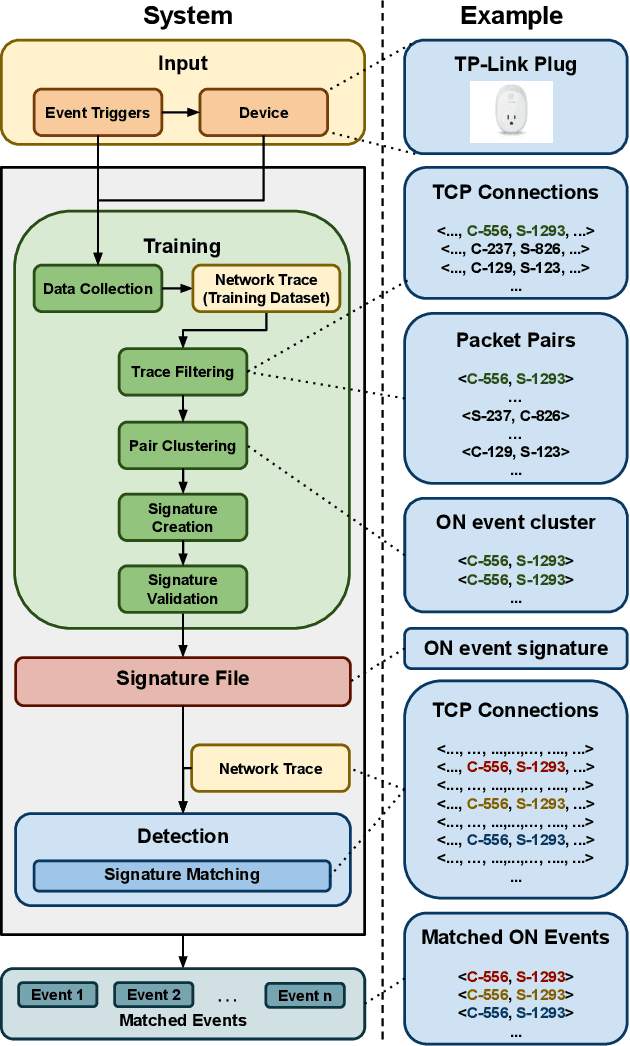
Smart home devices are vulnerable to passive inference attacks based on network traffic, even in the presence of encryption. In this paper, we present PingPong, a tool that can automatically extract packet-level signatures (i.e., simple sequences of packet lengths and directions) from the network traffic of smart home devices, and use those signatures to detect occurrences of specific device events (e.g., light bulb turning ON/OFF). We evaluated PingPong on popular smart home devices ranging from smart plugs to thermostats and home security systems. We have successfully: (1) extracted packet-level signatures from 18 devices (11 of which are the most popular smart home devices on Amazon) from 15 popular vendors, (2) used those signatures to detect occurrences of specific device events with an average recall of more than 97%, and (3) shown that the signatures are unique among tens of millions of packets of real world network traffic.
A Federated Learning Approach for Mobile Packet Classification
Jul 30, 2019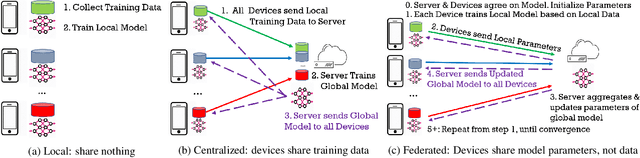



In order to improve mobile data transparency, a number of network-based approaches have been proposed to inspect packets generated by mobile devices and detect personally identifiable information (PII), ad requests, or other activities. State-of-the-art approaches train classifiers based on features extracted from HTTP packets. So far, these classifiers have only been trained in a centralized way, where mobile users label and upload their packet logs to a central server, which then trains a global classifier and shares it with the users to apply on their devices. However, packet logs used as training data may contain sensitive information that users may not want to share/upload. In this paper, we apply, for the first time, a Federated Learning approach to mobile packet classification, which allows mobile devices to collaborate and train a global model, without sharing raw training data. Methodological challenges we address in this context include: model and feature selection, and tuning the Federated Learning parameters. We apply our framework to two different packet classification tasks (i.e., to predict PII exposure or ad requests in HTTP packets) and we demonstrate its effectiveness in terms of classification performance, communication and computation cost, using three real-world datasets.
PhishDef: URL Names Say It All
Sep 12, 2010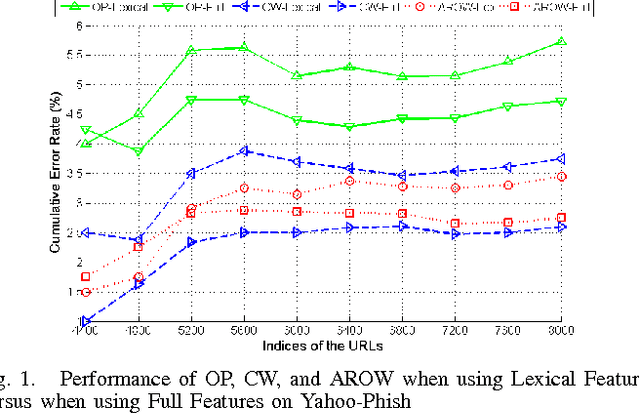
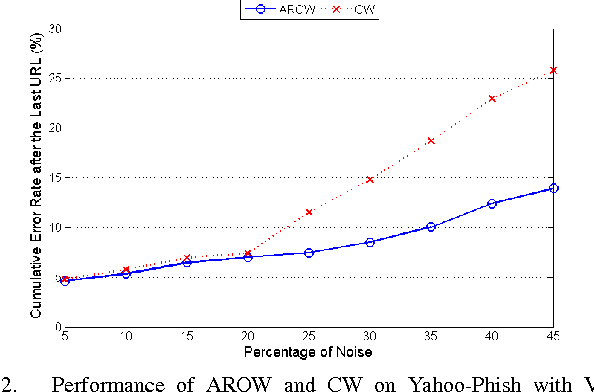


Phishing is an increasingly sophisticated method to steal personal user information using sites that pretend to be legitimate. In this paper, we take the following steps to identify phishing URLs. First, we carefully select lexical features of the URLs that are resistant to obfuscation techniques used by attackers. Second, we evaluate the classification accuracy when using only lexical features, both automatically and hand-selected, vs. when using additional features. We show that lexical features are sufficient for all practical purposes. Third, we thoroughly compare several classification algorithms, and we propose to use an online method (AROW) that is able to overcome noisy training data. Based on the insights gained from our analysis, we propose PhishDef, a phishing detection system that uses only URL names and combines the above three elements. PhishDef is a highly accurate method (when compared to state-of-the-art approaches over real datasets), lightweight (thus appropriate for online and client-side deployment), proactive (based on online classification rather than blacklists), and resilient to training data inaccuracies (thus enabling the use of large noisy training data).