 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaverick-Aware Shapley Valuation for Client Selection in Federated Learning
May 21, 2024



Federated Learning (FL) allows clients to train a model collaboratively without sharing their private data. One key challenge in practical FL systems is data heterogeneity, particularly in handling clients with rare data, also referred to as Mavericks. These clients own one or more data classes exclusively, and the model performance becomes poor without their participation. Thus, utilizing Mavericks throughout training is crucial. In this paper, we first design a Maverick-aware Shapley valuation that fairly evaluates the contribution of Mavericks. The main idea is to compute the clients' Shapley values (SV) class-wise, i.e., per label. Next, we propose FedMS, a Maverick-Shapley client selection mechanism for FL that intelligently selects the clients that contribute the most in each round, by employing our Maverick-aware SV-based contribution score. We show that, compared to an extensive list of baselines, FedMS achieves better model performance and fairer Shapley Rewards distribution.
MIAShield: Defending Membership Inference Attacks via Preemptive Exclusion of Members
Mar 02, 2022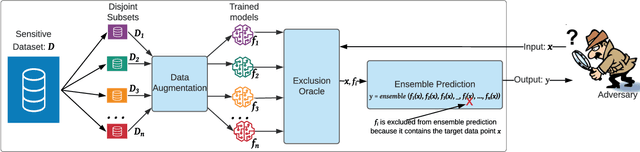

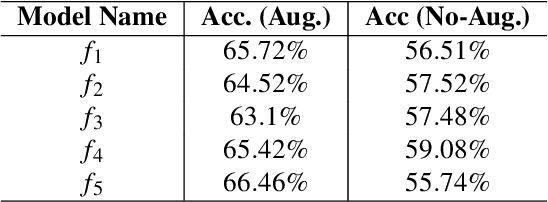
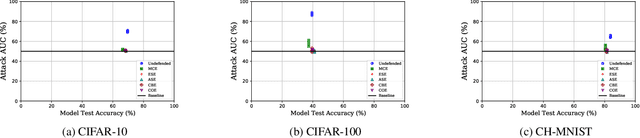
In membership inference attacks (MIAs), an adversary observes the predictions of a model to determine whether a sample is part of the model's training data. Existing MIA defenses conceal the presence of a target sample through strong regularization, knowledge distillation, confidence masking, or differential privacy. We propose MIAShield, a new MIA defense based on preemptive exclusion of member samples instead of masking the presence of a member. The key insight in MIAShield is weakening the strong membership signal that stems from the presence of a target sample by preemptively excluding it at prediction time without compromising model utility. To that end, we design and evaluate a suite of preemptive exclusion oracles leveraging model-confidence, exact or approximate sample signature, and learning-based exclusion of member data points. To be practical, MIAShield splits a training data into disjoint subsets and trains each subset to build an ensemble of models. The disjointedness of subsets ensures that a target sample belongs to only one subset, which isolates the sample to facilitate the preemptive exclusion goal. We evaluate MIAShield on three benchmark image classification datasets. We show that MIAShield effectively mitigates membership inference (near random guess) for a wide range of MIAs, achieves far better privacy-utility trade-off compared with state-of-the-art defenses, and remains resilient against an adaptive adversary.
DP-UTIL: Comprehensive Utility Analysis of Differential Privacy in Machine Learning
Dec 24, 2021
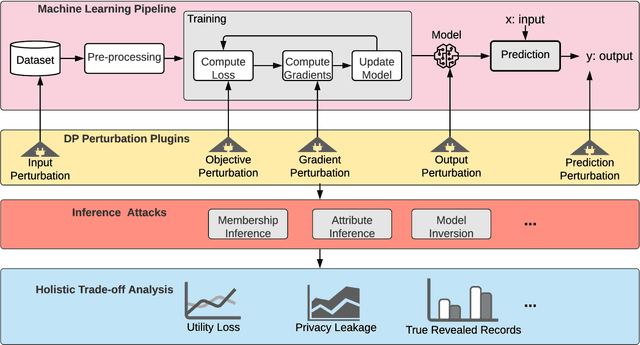


Differential Privacy (DP) has emerged as a rigorous formalism to reason about quantifiable privacy leakage. In machine learning (ML), DP has been employed to limit inference/disclosure of training examples. Prior work leveraged DP across the ML pipeline, albeit in isolation, often focusing on mechanisms such as gradient perturbation. In this paper, we present, DP-UTIL, a holistic utility analysis framework of DP across the ML pipeline with focus on input perturbation, objective perturbation, gradient perturbation, output perturbation, and prediction perturbation. Given an ML task on privacy-sensitive data, DP-UTIL enables a ML privacy practitioner perform holistic comparative analysis on the impact of DP in these five perturbation spots, measured in terms of model utility loss, privacy leakage, and the number of truly revealed training samples. We evaluate DP-UTIL over classification tasks on vision, medical, and financial datasets, using two representative learning algorithms (logistic regression and deep neural network) against membership inference attack as a case study attack. One of the highlights of our results is that prediction perturbation consistently achieves the lowest utility loss on all models across all datasets. In logistic regression models, objective perturbation results in lowest privacy leakage compared to other perturbation techniques. For deep neural networks, gradient perturbation results in lowest privacy leakage. Moreover, our results on true revealed records suggest that as privacy leakage increases a differentially private model reveals more number of member samples. Overall, our findings suggest that to make informed decisions as to which perturbation mechanism to use, a ML privacy practitioner needs to examine the dynamics between optimization techniques (convex vs. non-convex), perturbation mechanisms, number of classes, and privacy budget.
PRICURE: Privacy-Preserving Collaborative Inference in a Multi-Party Setting
Feb 19, 2021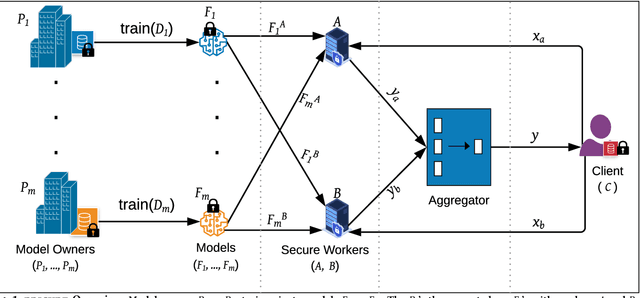

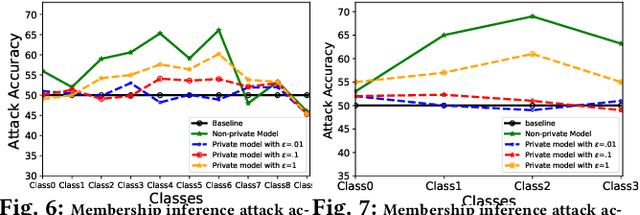
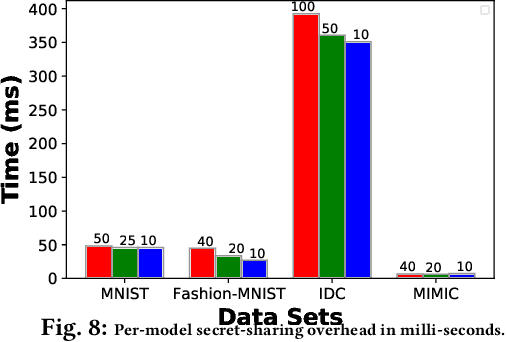
When multiple parties that deal with private data aim for a collaborative prediction task such as medical image classification, they are often constrained by data protection regulations and lack of trust among collaborating parties. If done in a privacy-preserving manner, predictive analytics can benefit from the collective prediction capability of multiple parties holding complementary datasets on the same machine learning task. This paper presents PRICURE, a system that combines complementary strengths of secure multi-party computation (SMPC) and differential privacy (DP) to enable privacy-preserving collaborative prediction among multiple model owners. SMPC enables secret-sharing of private models and client inputs with non-colluding secure servers to compute predictions without leaking model parameters and inputs. DP masks true prediction results via noisy aggregation so as to deter a semi-honest client who may mount membership inference attacks. We evaluate PRICURE on neural networks across four datasets including benchmark medical image classification datasets. Our results suggest PRICURE guarantees privacy for tens of model owners and clients with acceptable accuracy loss. We also show that DP reduces membership inference attack exposure without hurting accuracy.