 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepLeak: Privacy Enhancing Hardening of Model Explanations Against Membership Leakage
Jan 06, 2026Machine learning (ML) explainability is central to algorithmic transparency in high-stakes settings such as predictive diagnostics and loan approval. However, these same domains require rigorous privacy guaranties, creating tension between interpretability and privacy. Although prior work has shown that explanation methods can leak membership information, practitioners still lack systematic guidance on selecting or deploying explanation techniques that balance transparency with privacy. We present DeepLeak, a system to audit and mitigate privacy risks in post-hoc explanation methods. DeepLeak advances the state-of-the-art in three ways: (1) comprehensive leakage profiling: we develop a stronger explanation-aware membership inference attack (MIA) to quantify how much representative explanation methods leak membership information under default configurations; (2) lightweight hardening strategies: we introduce practical, model-agnostic mitigations, including sensitivity-calibrated noise, attribution clipping, and masking, that substantially reduce membership leakage while preserving explanation utility; and (3) root-cause analysis: through controlled experiments, we pinpoint algorithmic properties (e.g., attribution sparsity and sensitivity) that drive leakage. Evaluating 15 explanation techniques across four families on image benchmarks, DeepLeak shows that default settings can leak up to 74.9% more membership information than previously reported. Our mitigations cut leakage by up to 95% (minimum 46.5%) with only <=3.3% utility loss on average. DeepLeak offers a systematic, reproducible path to safer explainability in privacy-sensitive ML.
DeepProv: Behavioral Characterization and Repair of Neural Networks via Inference Provenance Graph Analysis
Sep 30, 2025



Deep neural networks (DNNs) are increasingly being deployed in high-stakes applications, from self-driving cars to biometric authentication. However, their unpredictable and unreliable behaviors in real-world settings require new approaches to characterize and ensure their reliability. This paper introduces DeepProv, a novel and customizable system designed to capture and characterize the runtime behavior of DNNs during inference by using their underlying graph structure. Inspired by system audit provenance graphs, DeepProv models the computational information flow of a DNN's inference process through Inference Provenance Graphs (IPGs). These graphs provide a detailed structural representation of the behavior of DNN, allowing both empirical and structural analysis. DeepProv uses these insights to systematically repair DNNs for specific objectives, such as improving robustness, privacy, or fairness. We instantiate DeepProv with adversarial robustness as the goal of model repair and conduct extensive case studies to evaluate its effectiveness. Our results demonstrate its effectiveness and scalability across diverse classification tasks, attack scenarios, and model complexities. DeepProv automatically identifies repair actions at the node and edge-level within IPGs, significantly enhancing the robustness of the model. In particular, applying DeepProv repair strategies to just a single layer of a DNN yields an average 55% improvement in adversarial accuracy. Moreover, DeepProv complements existing defenses, achieving substantial gains in adversarial robustness. Beyond robustness, we demonstrate the broader potential of DeepProv as an adaptable system to characterize DNN behavior in other critical areas, such as privacy auditing and fairness analysis.
Morphence-2.0: Evasion-Resilient Moving Target Defense Powered by Out-of-Distribution Detection
Jun 15, 2022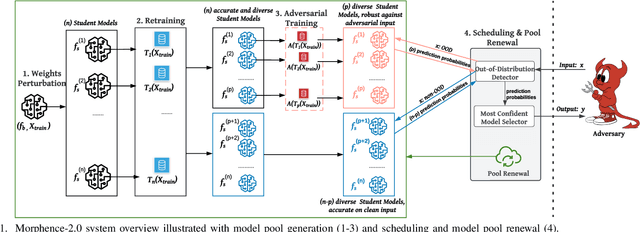
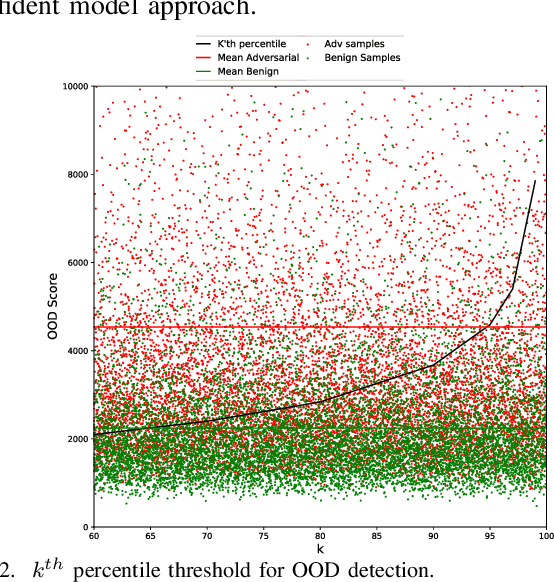
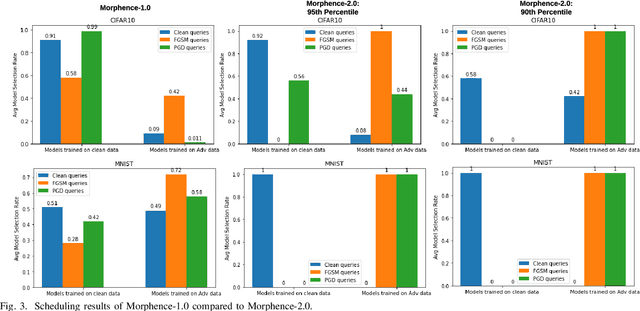
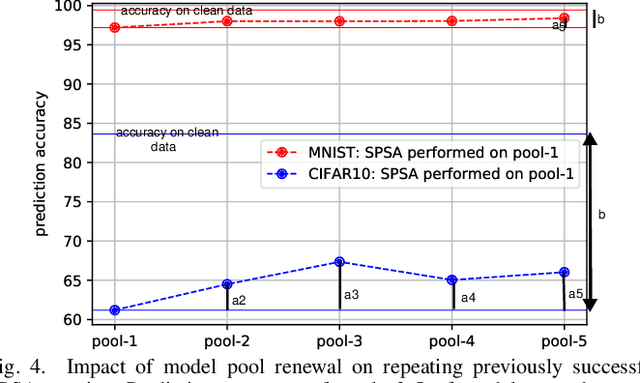
Evasion attacks against machine learning models often succeed via iterative probing of a fixed target model, whereby an attack that succeeds once will succeed repeatedly. One promising approach to counter this threat is making a model a moving target against adversarial inputs. To this end, we introduce Morphence-2.0, a scalable moving target defense (MTD) powered by out-of-distribution (OOD) detection to defend against adversarial examples. By regularly moving the decision function of a model, Morphence-2.0 makes it significantly challenging for repeated or correlated attacks to succeed. Morphence-2.0 deploys a pool of models generated from a base model in a manner that introduces sufficient randomness when it responds to prediction queries. Via OOD detection, Morphence-2.0 is equipped with a scheduling approach that assigns adversarial examples to robust decision functions and benign samples to an undefended accurate models. To ensure repeated or correlated attacks fail, the deployed pool of models automatically expires after a query budget is reached and the model pool is seamlessly replaced by a new model pool generated in advance. We evaluate Morphence-2.0 on two benchmark image classification datasets (MNIST and CIFAR10) against 4 reference attacks (3 white-box and 1 black-box). Morphence-2.0 consistently outperforms prior defenses while preserving accuracy on clean data and reducing attack transferability. We also show that, when powered by OOD detection, Morphence-2.0 is able to precisely make an input-based movement of the model's decision function that leads to higher prediction accuracy on both adversarial and benign queries.
MIAShield: Defending Membership Inference Attacks via Preemptive Exclusion of Members
Mar 02, 2022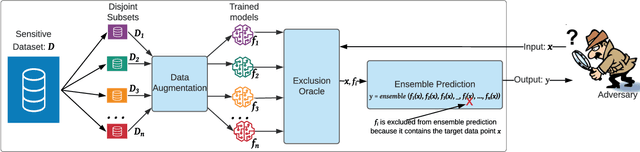

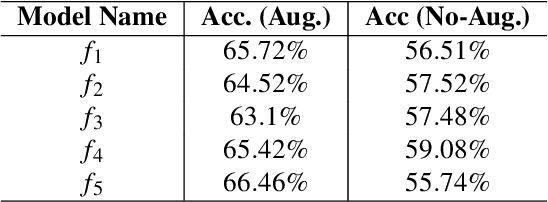
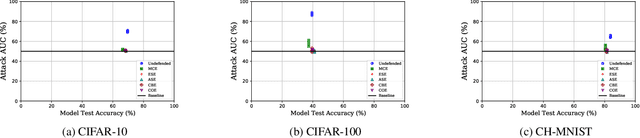
In membership inference attacks (MIAs), an adversary observes the predictions of a model to determine whether a sample is part of the model's training data. Existing MIA defenses conceal the presence of a target sample through strong regularization, knowledge distillation, confidence masking, or differential privacy. We propose MIAShield, a new MIA defense based on preemptive exclusion of member samples instead of masking the presence of a member. The key insight in MIAShield is weakening the strong membership signal that stems from the presence of a target sample by preemptively excluding it at prediction time without compromising model utility. To that end, we design and evaluate a suite of preemptive exclusion oracles leveraging model-confidence, exact or approximate sample signature, and learning-based exclusion of member data points. To be practical, MIAShield splits a training data into disjoint subsets and trains each subset to build an ensemble of models. The disjointedness of subsets ensures that a target sample belongs to only one subset, which isolates the sample to facilitate the preemptive exclusion goal. We evaluate MIAShield on three benchmark image classification datasets. We show that MIAShield effectively mitigates membership inference (near random guess) for a wide range of MIAs, achieves far better privacy-utility trade-off compared with state-of-the-art defenses, and remains resilient against an adaptive adversary.
Rethinking Machine Learning Robustness via its Link with the Out-of-Distribution Problem
Feb 18, 2022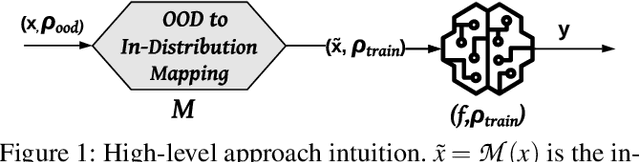
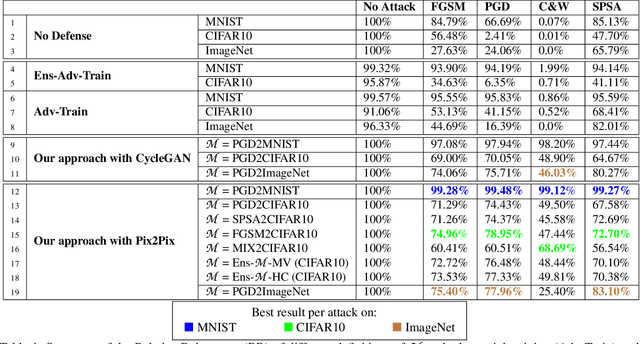
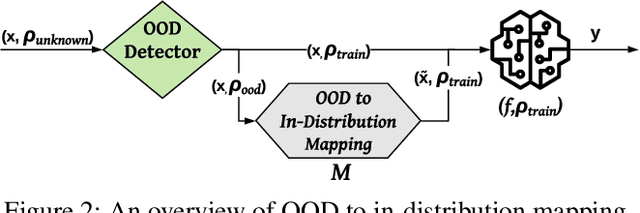

Despite multiple efforts made towards robust machine learning (ML) models, their vulnerability to adversarial examples remains a challenging problem that calls for rethinking the defense strategy. In this paper, we take a step back and investigate the causes behind ML models' susceptibility to adversarial examples. In particular, we focus on exploring the cause-effect link between adversarial examples and the out-of-distribution (OOD) problem. To that end, we propose an OOD generalization method that stands against both adversary-induced and natural distribution shifts. Through an OOD to in-distribution mapping intuition, our approach translates OOD inputs to the data distribution used to train and test the model. Through extensive experiments on three benchmark image datasets of different scales (MNIST, CIFAR10, and ImageNet) and by leveraging image-to-image translation methods, we confirm that the adversarial examples problem is a special case of the wider OOD generalization problem. Across all datasets, we show that our translation-based approach consistently improves robustness to OOD adversarial inputs and outperforms state-of-the-art defenses by a significant margin, while preserving the exact accuracy on benign (in-distribution) data. Furthermore, our method generalizes on naturally OOD inputs such as darker or sharper images
DP-UTIL: Comprehensive Utility Analysis of Differential Privacy in Machine Learning
Dec 24, 2021
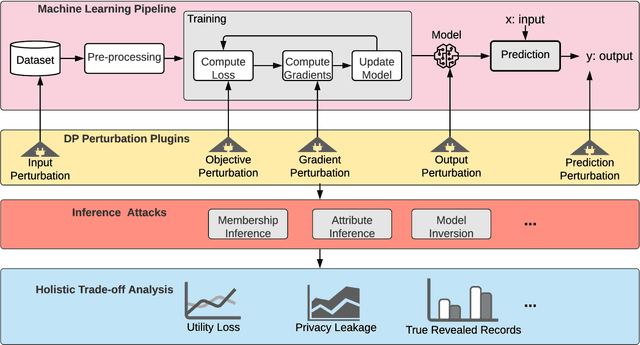


Differential Privacy (DP) has emerged as a rigorous formalism to reason about quantifiable privacy leakage. In machine learning (ML), DP has been employed to limit inference/disclosure of training examples. Prior work leveraged DP across the ML pipeline, albeit in isolation, often focusing on mechanisms such as gradient perturbation. In this paper, we present, DP-UTIL, a holistic utility analysis framework of DP across the ML pipeline with focus on input perturbation, objective perturbation, gradient perturbation, output perturbation, and prediction perturbation. Given an ML task on privacy-sensitive data, DP-UTIL enables a ML privacy practitioner perform holistic comparative analysis on the impact of DP in these five perturbation spots, measured in terms of model utility loss, privacy leakage, and the number of truly revealed training samples. We evaluate DP-UTIL over classification tasks on vision, medical, and financial datasets, using two representative learning algorithms (logistic regression and deep neural network) against membership inference attack as a case study attack. One of the highlights of our results is that prediction perturbation consistently achieves the lowest utility loss on all models across all datasets. In logistic regression models, objective perturbation results in lowest privacy leakage compared to other perturbation techniques. For deep neural networks, gradient perturbation results in lowest privacy leakage. Moreover, our results on true revealed records suggest that as privacy leakage increases a differentially private model reveals more number of member samples. Overall, our findings suggest that to make informed decisions as to which perturbation mechanism to use, a ML privacy practitioner needs to examine the dynamics between optimization techniques (convex vs. non-convex), perturbation mechanisms, number of classes, and privacy budget.
EG-Booster: Explanation-Guided Booster of ML Evasion Attacks
Sep 02, 2021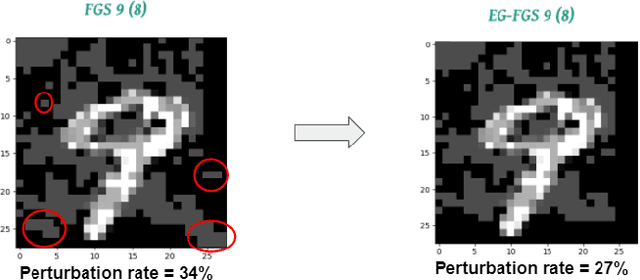
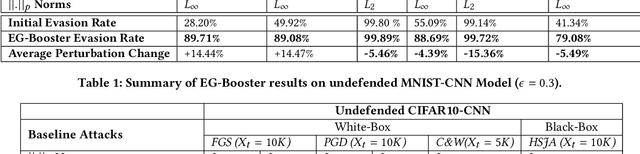
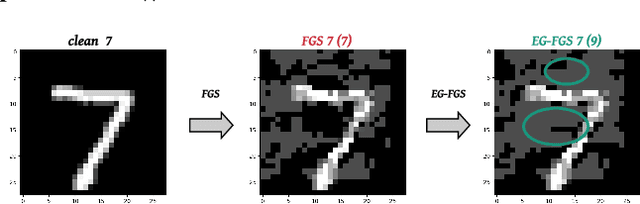

The widespread usage of machine learning (ML) in a myriad of domains has raised questions about its trustworthiness in security-critical environments. Part of the quest for trustworthy ML is robustness evaluation of ML models to test-time adversarial examples. Inline with the trustworthy ML goal, a useful input to potentially aid robustness evaluation is feature-based explanations of model predictions. In this paper, we present a novel approach called EG-Booster that leverages techniques from explainable ML to guide adversarial example crafting for improved robustness evaluation of ML models before deploying them in security-critical settings. The key insight in EG-Booster is the use of feature-based explanations of model predictions to guide adversarial example crafting by adding consequential perturbations likely to result in model evasion and avoiding non-consequential ones unlikely to contribute to evasion. EG-Booster is agnostic to model architecture, threat model, and supports diverse distance metrics used previously in the literature. We evaluate EG-Booster using image classification benchmark datasets, MNIST and CIFAR10. Our findings suggest that EG-Booster significantly improves evasion rate of state-of-the-art attacks while performing less number of perturbations. Through extensive experiments that covers four white-box and three black-box attacks, we demonstrate the effectiveness of EG-Booster against two undefended neural networks trained on MNIST and CIFAR10, and another adversarially-trained ResNet model trained on CIFAR10. Furthermore, we introduce a stability assessment metric and evaluate the reliability of our explanation-based approach by observing the similarity between the model's classification outputs across multiple runs of EG-Booster.
Morphence: Moving Target Defense Against Adversarial Examples
Sep 02, 2021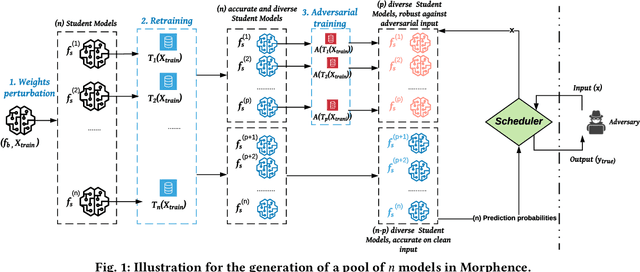
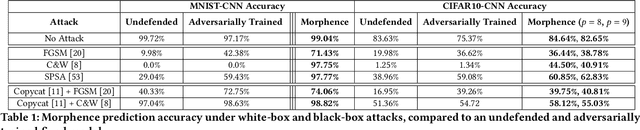
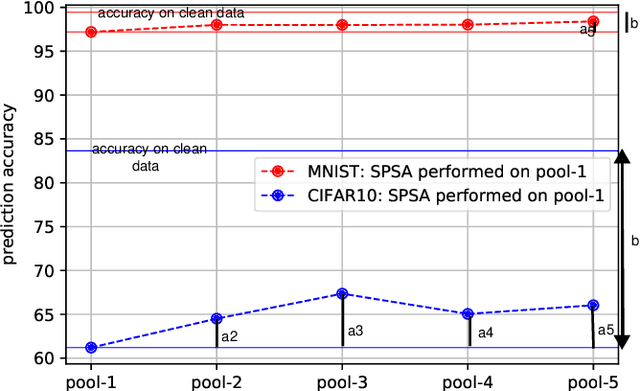
Robustness to adversarial examples of machine learning models remains an open topic of research. Attacks often succeed by repeatedly probing a fixed target model with adversarial examples purposely crafted to fool it. In this paper, we introduce Morphence, an approach that shifts the defense landscape by making a model a moving target against adversarial examples. By regularly moving the decision function of a model, Morphence makes it significantly challenging for repeated or correlated attacks to succeed. Morphence deploys a pool of models generated from a base model in a manner that introduces sufficient randomness when it responds to prediction queries. To ensure repeated or correlated attacks fail, the deployed pool of models automatically expires after a query budget is reached and the model pool is seamlessly replaced by a new model pool generated in advance. We evaluate Morphence on two benchmark image classification datasets (MNIST and CIFAR10) against five reference attacks (2 white-box and 3 black-box). In all cases, Morphence consistently outperforms the thus-far effective defense, adversarial training, even in the face of strong white-box attacks, while preserving accuracy on clean data.
Explanation-Guided Diagnosis of Machine Learning Evasion Attacks
Jun 30, 2021

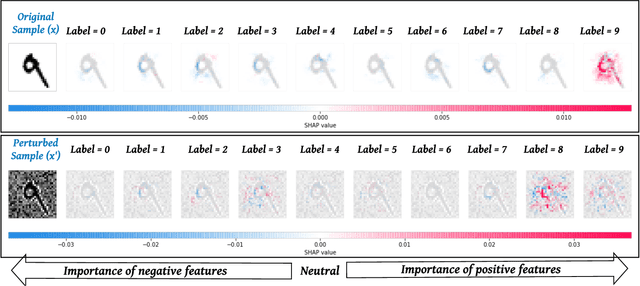
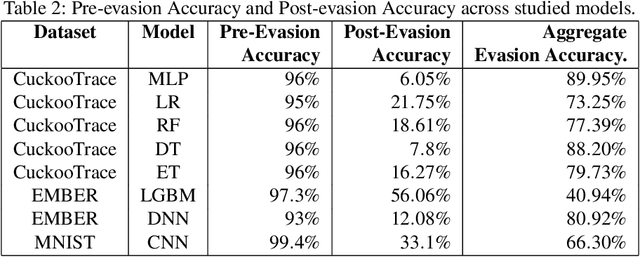
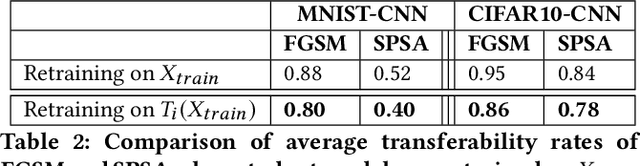
Machine Learning (ML) models are susceptible to evasion attacks. Evasion accuracy is typically assessed using aggregate evasion rate, and it is an open question whether aggregate evasion rate enables feature-level diagnosis on the effect of adversarial perturbations on evasive predictions. In this paper, we introduce a novel framework that harnesses explainable ML methods to guide high-fidelity assessment of ML evasion attacks. Our framework enables explanation-guided correlation analysis between pre-evasion perturbations and post-evasion explanations. Towards systematic assessment of ML evasion attacks, we propose and evaluate a novel suite of model-agnostic metrics for sample-level and dataset-level correlation analysis. Using malware and image classifiers, we conduct comprehensive evaluations across diverse model architectures and complementary feature representations. Our explanation-guided correlation analysis reveals correlation gaps between adversarial samples and the corresponding perturbations performed on them. Using a case study on explanation-guided evasion, we show the broader usage of our methodology for assessing robustness of ML models.
PRICURE: Privacy-Preserving Collaborative Inference in a Multi-Party Setting
Feb 19, 2021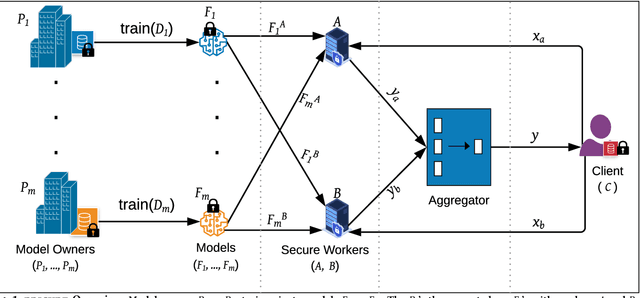

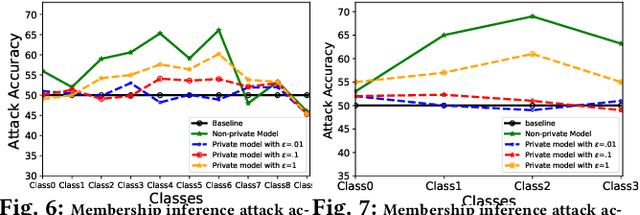
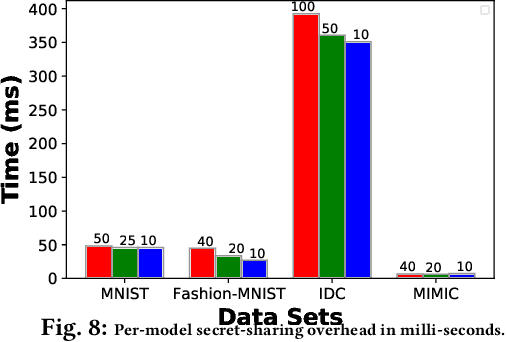
When multiple parties that deal with private data aim for a collaborative prediction task such as medical image classification, they are often constrained by data protection regulations and lack of trust among collaborating parties. If done in a privacy-preserving manner, predictive analytics can benefit from the collective prediction capability of multiple parties holding complementary datasets on the same machine learning task. This paper presents PRICURE, a system that combines complementary strengths of secure multi-party computation (SMPC) and differential privacy (DP) to enable privacy-preserving collaborative prediction among multiple model owners. SMPC enables secret-sharing of private models and client inputs with non-colluding secure servers to compute predictions without leaking model parameters and inputs. DP masks true prediction results via noisy aggregation so as to deter a semi-honest client who may mount membership inference attacks. We evaluate PRICURE on neural networks across four datasets including benchmark medical image classification datasets. Our results suggest PRICURE guarantees privacy for tens of model owners and clients with acceptable accuracy loss. We also show that DP reduces membership inference attack exposure without hurting accuracy.