 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEG-Booster: Explanation-Guided Booster of ML Evasion Attacks
Paper and Code
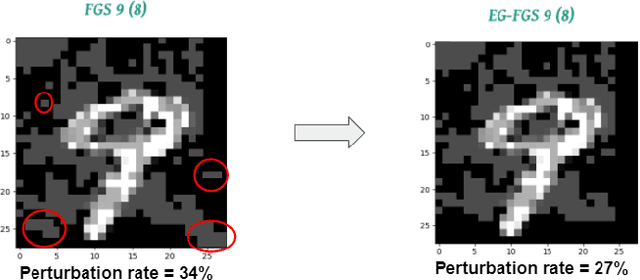
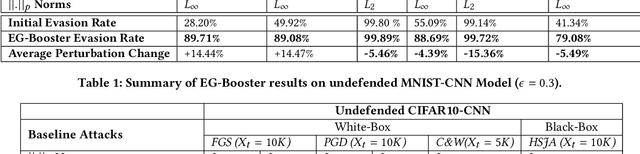
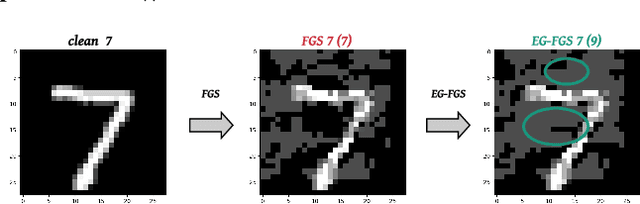

The widespread usage of machine learning (ML) in a myriad of domains has raised questions about its trustworthiness in security-critical environments. Part of the quest for trustworthy ML is robustness evaluation of ML models to test-time adversarial examples. Inline with the trustworthy ML goal, a useful input to potentially aid robustness evaluation is feature-based explanations of model predictions. In this paper, we present a novel approach called EG-Booster that leverages techniques from explainable ML to guide adversarial example crafting for improved robustness evaluation of ML models before deploying them in security-critical settings. The key insight in EG-Booster is the use of feature-based explanations of model predictions to guide adversarial example crafting by adding consequential perturbations likely to result in model evasion and avoiding non-consequential ones unlikely to contribute to evasion. EG-Booster is agnostic to model architecture, threat model, and supports diverse distance metrics used previously in the literature. We evaluate EG-Booster using image classification benchmark datasets, MNIST and CIFAR10. Our findings suggest that EG-Booster significantly improves evasion rate of state-of-the-art attacks while performing less number of perturbations. Through extensive experiments that covers four white-box and three black-box attacks, we demonstrate the effectiveness of EG-Booster against two undefended neural networks trained on MNIST and CIFAR10, and another adversarially-trained ResNet model trained on CIFAR10. Furthermore, we introduce a stability assessment metric and evaluate the reliability of our explanation-based approach by observing the similarity between the model's classification outputs across multiple runs of EG-Booster.