 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation-Guided Diagnosis of Machine Learning Evasion Attacks
Paper and Code
Jun 30, 2021

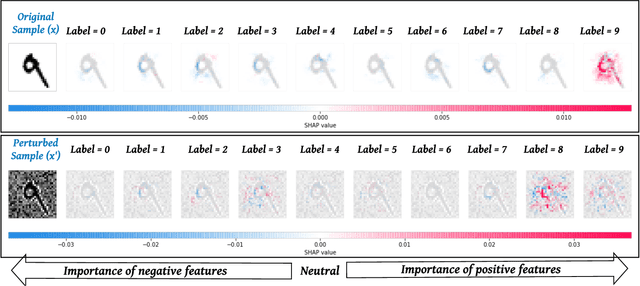
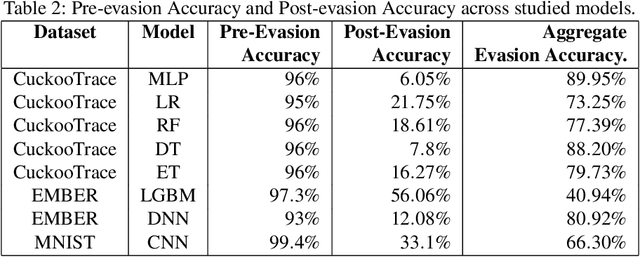
Machine Learning (ML) models are susceptible to evasion attacks. Evasion accuracy is typically assessed using aggregate evasion rate, and it is an open question whether aggregate evasion rate enables feature-level diagnosis on the effect of adversarial perturbations on evasive predictions. In this paper, we introduce a novel framework that harnesses explainable ML methods to guide high-fidelity assessment of ML evasion attacks. Our framework enables explanation-guided correlation analysis between pre-evasion perturbations and post-evasion explanations. Towards systematic assessment of ML evasion attacks, we propose and evaluate a novel suite of model-agnostic metrics for sample-level and dataset-level correlation analysis. Using malware and image classifiers, we conduct comprehensive evaluations across diverse model architectures and complementary feature representations. Our explanation-guided correlation analysis reveals correlation gaps between adversarial samples and the corresponding perturbations performed on them. Using a case study on explanation-guided evasion, we show the broader usage of our methodology for assessing robustness of ML models.