 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-UTIL: Comprehensive Utility Analysis of Differential Privacy in Machine Learning
Paper and Code

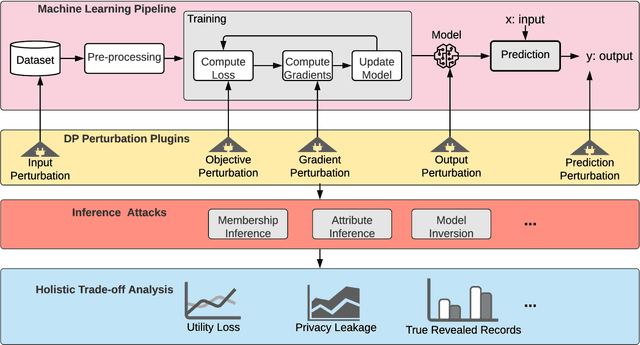


Differential Privacy (DP) has emerged as a rigorous formalism to reason about quantifiable privacy leakage. In machine learning (ML), DP has been employed to limit inference/disclosure of training examples. Prior work leveraged DP across the ML pipeline, albeit in isolation, often focusing on mechanisms such as gradient perturbation. In this paper, we present, DP-UTIL, a holistic utility analysis framework of DP across the ML pipeline with focus on input perturbation, objective perturbation, gradient perturbation, output perturbation, and prediction perturbation. Given an ML task on privacy-sensitive data, DP-UTIL enables a ML privacy practitioner perform holistic comparative analysis on the impact of DP in these five perturbation spots, measured in terms of model utility loss, privacy leakage, and the number of truly revealed training samples. We evaluate DP-UTIL over classification tasks on vision, medical, and financial datasets, using two representative learning algorithms (logistic regression and deep neural network) against membership inference attack as a case study attack. One of the highlights of our results is that prediction perturbation consistently achieves the lowest utility loss on all models across all datasets. In logistic regression models, objective perturbation results in lowest privacy leakage compared to other perturbation techniques. For deep neural networks, gradient perturbation results in lowest privacy leakage. Moreover, our results on true revealed records suggest that as privacy leakage increases a differentially private model reveals more number of member samples. Overall, our findings suggest that to make informed decisions as to which perturbation mechanism to use, a ML privacy practitioner needs to examine the dynamics between optimization techniques (convex vs. non-convex), perturbation mechanisms, number of classes, and privacy budget.