 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Machine Learning Robustness via its Link with the Out-of-Distribution Problem
Paper and Code
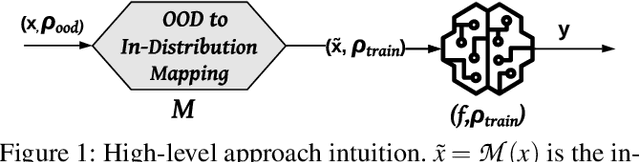
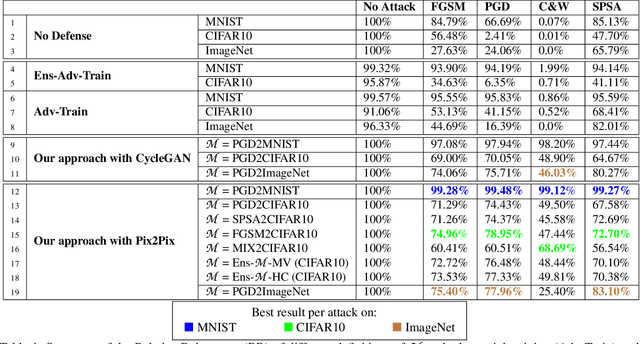
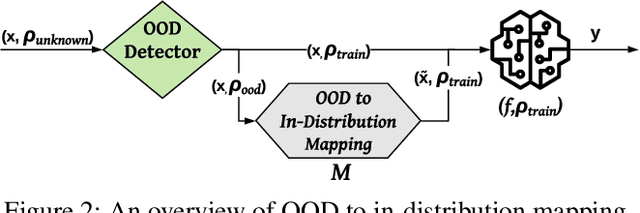

Despite multiple efforts made towards robust machine learning (ML) models, their vulnerability to adversarial examples remains a challenging problem that calls for rethinking the defense strategy. In this paper, we take a step back and investigate the causes behind ML models' susceptibility to adversarial examples. In particular, we focus on exploring the cause-effect link between adversarial examples and the out-of-distribution (OOD) problem. To that end, we propose an OOD generalization method that stands against both adversary-induced and natural distribution shifts. Through an OOD to in-distribution mapping intuition, our approach translates OOD inputs to the data distribution used to train and test the model. Through extensive experiments on three benchmark image datasets of different scales (MNIST, CIFAR10, and ImageNet) and by leveraging image-to-image translation methods, we confirm that the adversarial examples problem is a special case of the wider OOD generalization problem. Across all datasets, we show that our translation-based approach consistently improves robustness to OOD adversarial inputs and outperforms state-of-the-art defenses by a significant margin, while preserving the exact accuracy on benign (in-distribution) data. Furthermore, our method generalizes on naturally OOD inputs such as darker or sharper images