 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIAShield: Defending Membership Inference Attacks via Preemptive Exclusion of Members
Paper and Code
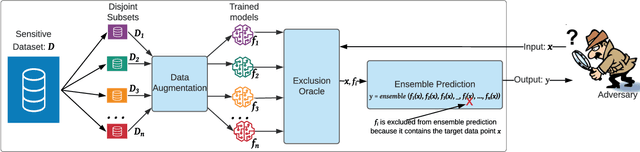

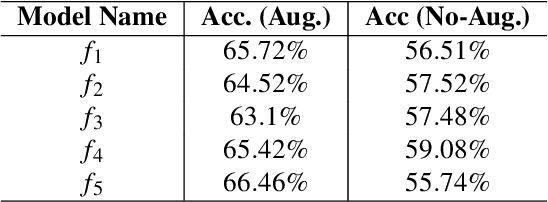
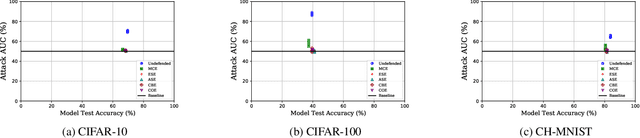
In membership inference attacks (MIAs), an adversary observes the predictions of a model to determine whether a sample is part of the model's training data. Existing MIA defenses conceal the presence of a target sample through strong regularization, knowledge distillation, confidence masking, or differential privacy. We propose MIAShield, a new MIA defense based on preemptive exclusion of member samples instead of masking the presence of a member. The key insight in MIAShield is weakening the strong membership signal that stems from the presence of a target sample by preemptively excluding it at prediction time without compromising model utility. To that end, we design and evaluate a suite of preemptive exclusion oracles leveraging model-confidence, exact or approximate sample signature, and learning-based exclusion of member data points. To be practical, MIAShield splits a training data into disjoint subsets and trains each subset to build an ensemble of models. The disjointedness of subsets ensures that a target sample belongs to only one subset, which isolates the sample to facilitate the preemptive exclusion goal. We evaluate MIAShield on three benchmark image classification datasets. We show that MIAShield effectively mitigates membership inference (near random guess) for a wide range of MIAs, achieves far better privacy-utility trade-off compared with state-of-the-art defenses, and remains resilient against an adaptive adversary.