 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphence: Moving Target Defense Against Adversarial Examples
Paper and Code
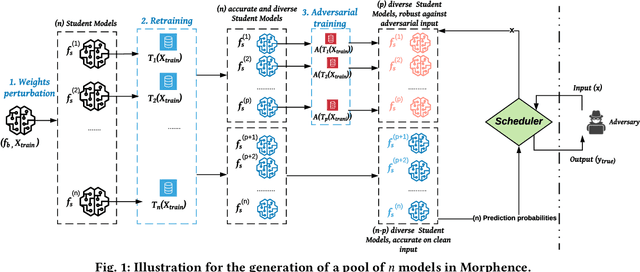
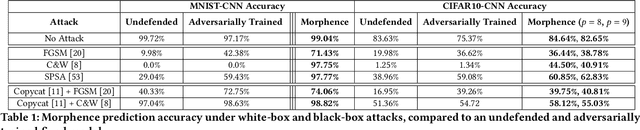
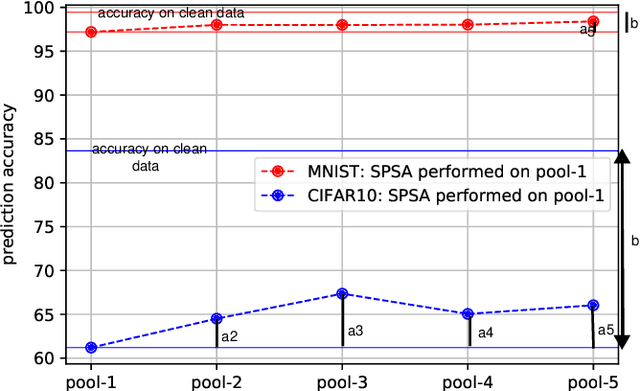
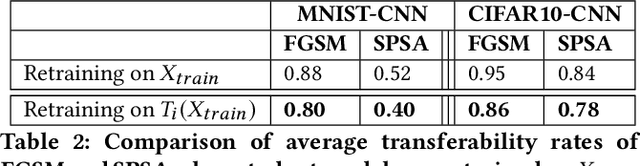
Robustness to adversarial examples of machine learning models remains an open topic of research. Attacks often succeed by repeatedly probing a fixed target model with adversarial examples purposely crafted to fool it. In this paper, we introduce Morphence, an approach that shifts the defense landscape by making a model a moving target against adversarial examples. By regularly moving the decision function of a model, Morphence makes it significantly challenging for repeated or correlated attacks to succeed. Morphence deploys a pool of models generated from a base model in a manner that introduces sufficient randomness when it responds to prediction queries. To ensure repeated or correlated attacks fail, the deployed pool of models automatically expires after a query budget is reached and the model pool is seamlessly replaced by a new model pool generated in advance. We evaluate Morphence on two benchmark image classification datasets (MNIST and CIFAR10) against five reference attacks (2 white-box and 3 black-box). In all cases, Morphence consistently outperforms the thus-far effective defense, adversarial training, even in the face of strong white-box attacks, while preserving accuracy on clean data.