 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaverick-Aware Shapley Valuation for Client Selection in Federated Learning
May 21, 2024



Federated Learning (FL) allows clients to train a model collaboratively without sharing their private data. One key challenge in practical FL systems is data heterogeneity, particularly in handling clients with rare data, also referred to as Mavericks. These clients own one or more data classes exclusively, and the model performance becomes poor without their participation. Thus, utilizing Mavericks throughout training is crucial. In this paper, we first design a Maverick-aware Shapley valuation that fairly evaluates the contribution of Mavericks. The main idea is to compute the clients' Shapley values (SV) class-wise, i.e., per label. Next, we propose FedMS, a Maverick-Shapley client selection mechanism for FL that intelligently selects the clients that contribute the most in each round, by employing our Maverick-aware SV-based contribution score. We show that, compared to an extensive list of baselines, FedMS achieves better model performance and fairer Shapley Rewards distribution.
PriPrune: Quantifying and Preserving Privacy in Pruned Federated Learning
Oct 30, 2023



Federated learning (FL) is a paradigm that allows several client devices and a server to collaboratively train a global model, by exchanging only model updates, without the devices sharing their local training data. These devices are often constrained in terms of communication and computation resources, and can further benefit from model pruning -- a paradigm that is widely used to reduce the size and complexity of models. Intuitively, by making local models coarser, pruning is expected to also provide some protection against privacy attacks in the context of FL. However this protection has not been previously characterized, formally or experimentally, and it is unclear if it is sufficient against state-of-the-art attacks. In this paper, we perform the first investigation of privacy guarantees for model pruning in FL. We derive information-theoretic upper bounds on the amount of information leaked by pruned FL models. We complement and validate these theoretical findings, with comprehensive experiments that involve state-of-the-art privacy attacks, on several state-of-the-art FL pruning schemes, using benchmark datasets. This evaluation provides valuable insights into the choices and parameters that can affect the privacy protection provided by pruning. Based on these insights, we introduce PriPrune -- a privacy-aware algorithm for local model pruning, which uses a personalized per-client defense mask and adapts the defense pruning rate so as to jointly optimize privacy and model performance. PriPrune is universal in that can be applied after any pruned FL scheme on the client, without modification, and protects against any inversion attack by the server. Our empirical evaluation demonstrates that PriPrune significantly improves the privacy-accuracy tradeoff compared to state-of-the-art pruned FL schemes that do not take privacy into account.
The Tradeoff Between Privacy and Accuracy in Anomaly Detection Using Federated XGBoost
Jul 16, 2019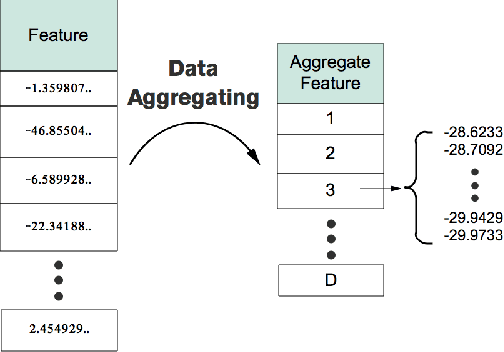

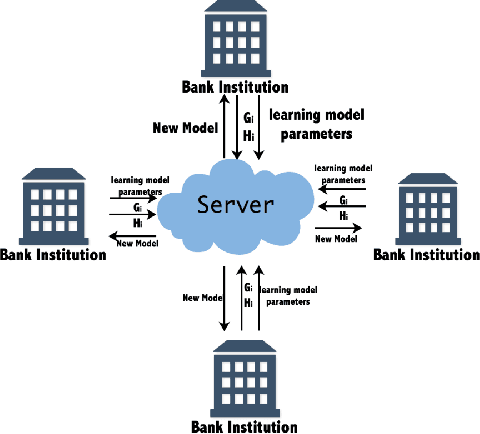
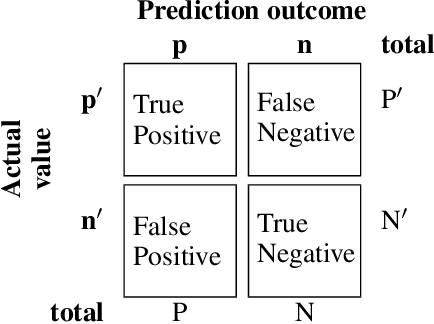
Privacy has raised considerable concerns recently, especially with the advent of information explosion and numerous data mining techniques to explore the information inside large volumes of data. In this context, a new distributed learning paradigm termed federated learning becomes prominent recently to tackle the privacy issues in distributed learning, where only learning models will be transmitted from the distributed nodes to servers without revealing users' own data and hence protecting the privacy of users. In this paper, we propose a horizontal federated XGBoost algorithm to solve the federated anomaly detection problem, where the anomaly detection aims to identify abnormalities from extremely unbalanced datasets and can be considered as a special classification problem. Our proposed federated XGBoost algorithm incorporates data aggregation and sparse federated update processes to balance the tradeoff between privacy and learning performance. In particular, we introduce the virtual data sample by aggregating a group of users' data together at a single distributed node. We compute parameters based on these virtual data samples in the local nodes and aggregate the learning model in the central server. In the learning model upgrading process, we focus more on the wrongly classified data before in the virtual sample and hence to generate sparse learning model parameters. By carefully controlling the size of these groups of samples, we can achieve a tradeoff between privacy and learning performance. Our experimental results show the effectiveness of our proposed scheme by comparing with existing state-of-the-arts.