 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tradeoff Between Privacy and Accuracy in Anomaly Detection Using Federated XGBoost
Jul 16, 2019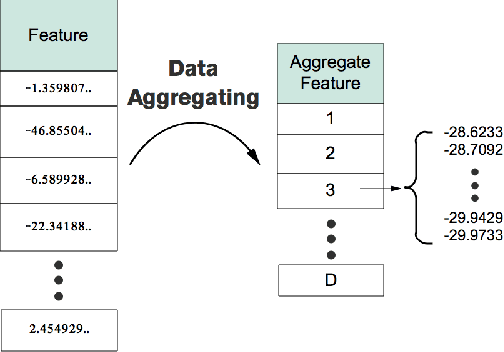

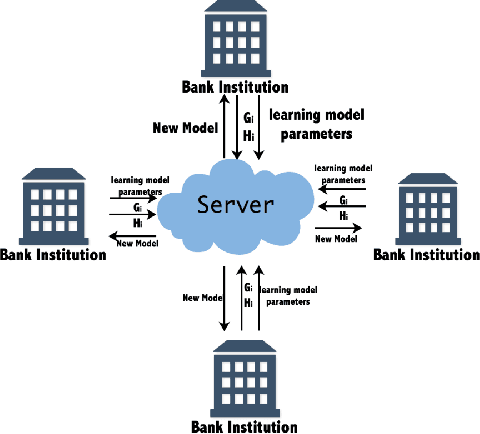
Privacy has raised considerable concerns recently, especially with the advent of information explosion and numerous data mining techniques to explore the information inside large volumes of data. In this context, a new distributed learning paradigm termed federated learning becomes prominent recently to tackle the privacy issues in distributed learning, where only learning models will be transmitted from the distributed nodes to servers without revealing users' own data and hence protecting the privacy of users. In this paper, we propose a horizontal federated XGBoost algorithm to solve the federated anomaly detection problem, where the anomaly detection aims to identify abnormalities from extremely unbalanced datasets and can be considered as a special classification problem. Our proposed federated XGBoost algorithm incorporates data aggregation and sparse federated update processes to balance the tradeoff between privacy and learning performance. In particular, we introduce the virtual data sample by aggregating a group of users' data together at a single distributed node. We compute parameters based on these virtual data samples in the local nodes and aggregate the learning model in the central server. In the learning model upgrading process, we focus more on the wrongly classified data before in the virtual sample and hence to generate sparse learning model parameters. By carefully controlling the size of these groups of samples, we can achieve a tradeoff between privacy and learning performance. Our experimental results show the effectiveness of our proposed scheme by comparing with existing state-of-the-arts.
A Many-Objective Evolutionary Algorithm with Two Interacting Processes: Cascade Clustering and Reference Point Incremental Learning
Oct 04, 2018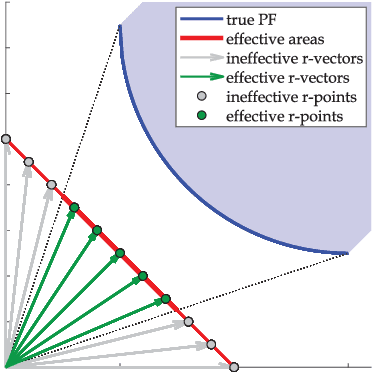
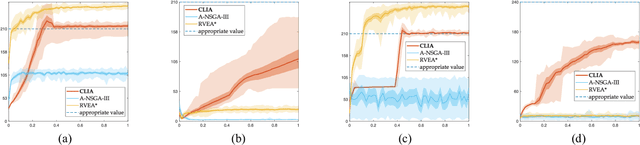
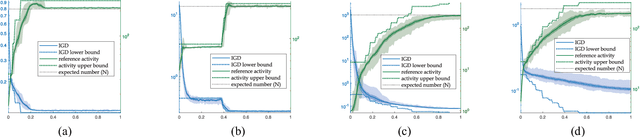
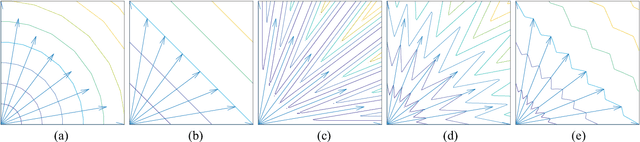
Researches have shown difficulties in obtaining proximity while maintaining diversity for solving many-objective optimization problems (MaOPs). The complexities of the true Pareto Front (PF) pose serious challenges for the reference vector based algorithms for their insufficient adaptability to the characteristics of the true PF with no priori. This paper proposes a many-objective optimization Algorithm with two Interacting processes: cascade Clustering and reference point incremental Learning (CLIA). In the population selection process based on cascade clustering, using the reference vectors provided by the incremental learning process, the non-dominated and the dominated individuals are clustered and sorted with different manners in a cascade style and are selected by round-robin for better proximity and diversity. In the reference vector adaptation process based on reference point incremental learning, using the feedbacks from the clustering process, the proper distribution of reference points is gradually obtained by incremental learning and the reference vectors are accordingly repositioned. The advantages of CLIA lie not only in its effective and efficient performance, but also in the versatility to deal with diverse characteristics of the true PF, only using the interactions between the two processes without incurring extra evaluations. The experimental studies on many benchmark problems show that CLIA is competitive, efficient and versatile compared with the state-of-the-art algorithms.
* 15 pages
ORGB: Offset Correction in RGB Color Space for Illumination-Robust Image Processing
Aug 03, 2017
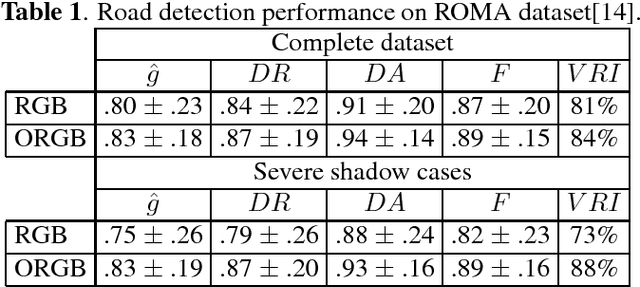
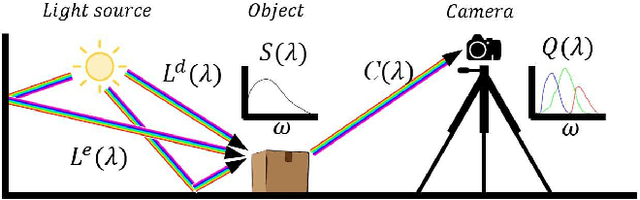
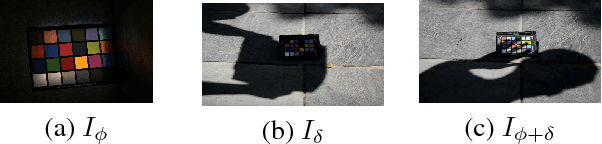
Single materials have colors which form straight lines in RGB space. However, in severe shadow cases, those lines do not intersect the origin, which is inconsistent with the description of most literature. This paper is concerned with the detection and correction of the offset between the intersection and origin. First, we analyze the reason for forming that offset via an optical imaging model. Second, we present a simple and effective way to detect and remove the offset. The resulting images, named ORGB, have almost the same appearance as the original RGB images while are more illumination-robust for color space conversion. Besides, image processing using ORGB instead of RGB is free from the interference of shadows. Finally, the proposed offset correction method is applied to road detection task, improving the performance both in quantitative and qualitative evaluations.