 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Addressing Delusions for Target-Directed Decision-Making
Oct 10, 2024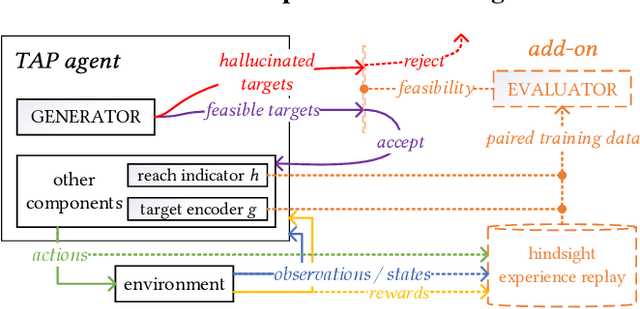

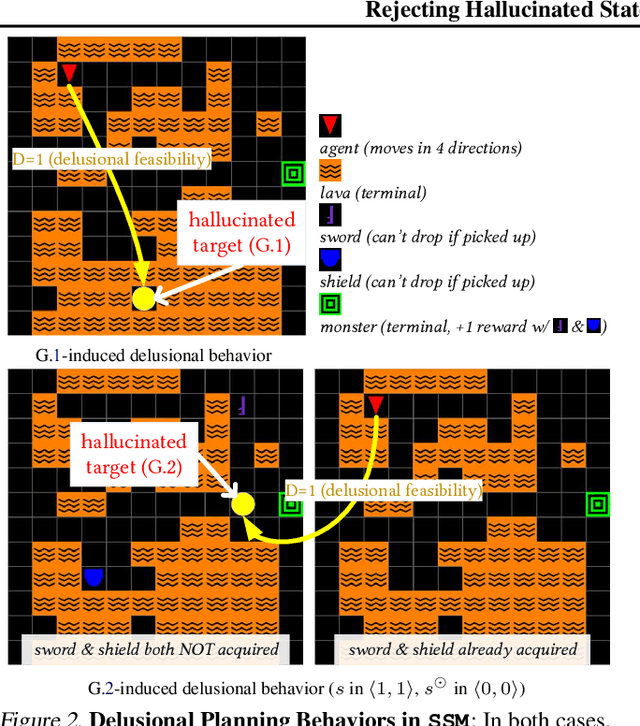
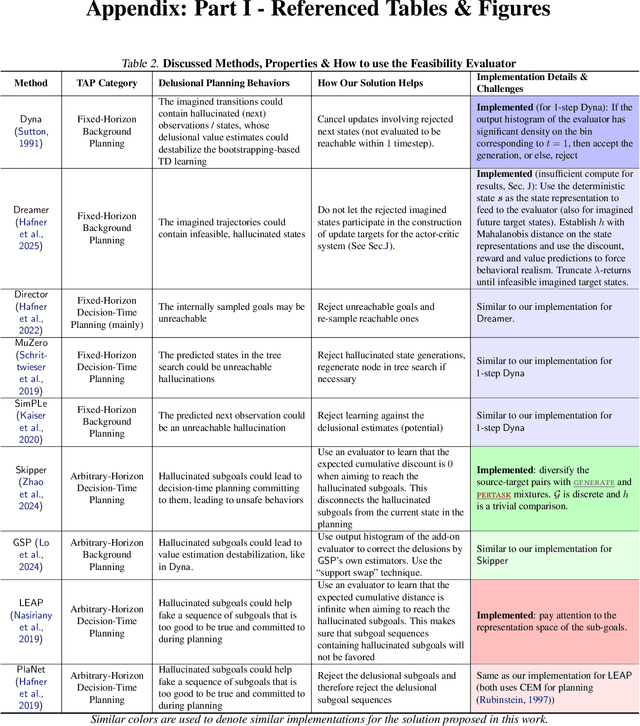
We are interested in target-directed agents, which produce targets during decision-time planning, to guide their behaviors and achieve better generalization during evaluation. Improper training of these agents can result in delusions: the agent may come to hold false beliefs about the targets, which cannot be properly rejected, leading to unwanted behaviors and damaging out-of-distribution generalization. We identify different types of delusions by using intuitive examples in carefully controlled environments, and investigate their causes. We demonstrate how delusions can be addressed for agents trained by hindsight relabeling, a mainstream approach in for training target-directed RL agents. We validate empirically the effectiveness of the proposed solutions in correcting delusional behaviors and improving out-of-distribution generalization.
Combining Spatial and Temporal Abstraction in Planning for Better Generalization
Sep 30, 2023
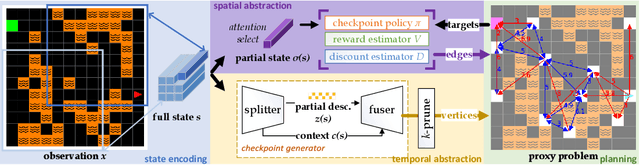
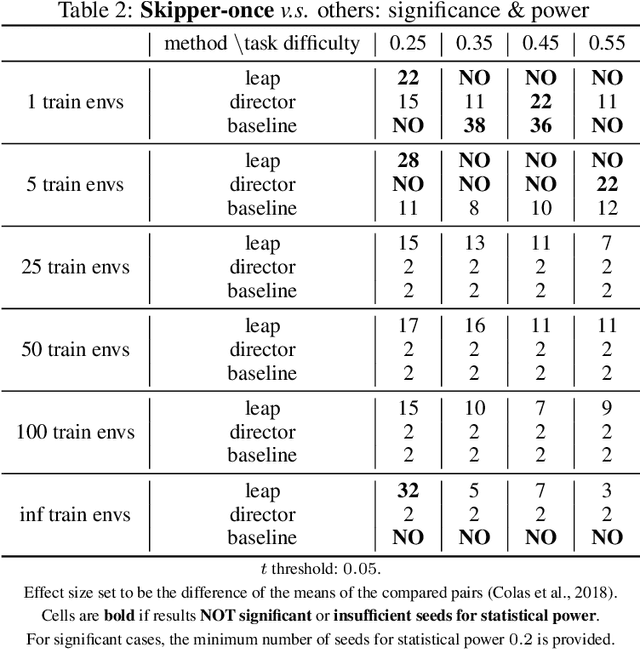
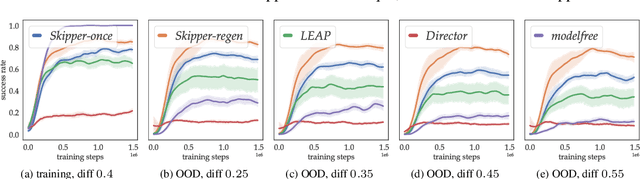
Inspired by human conscious planning, we propose Skipper, a model-based reinforcement learning agent that utilizes spatial and temporal abstractions to generalize learned skills in novel situations. It automatically decomposes the task at hand into smaller-scale, more manageable subtasks and hence enables sparse decision-making and focuses its computation on the relevant parts of the environment. This relies on the definition of a high-level proxy problem represented as a directed graph, in which vertices and edges are learned end-to-end using hindsight. Our theoretical analyses provide performance guarantees under appropriate assumptions and establish where our approach is expected to be helpful. Generalization-focused experiments validate Skipper's significant advantage in zero-shot generalization, compared to existing state-of-the-art hierarchical planning methods.
Complete the Missing Half: Augmenting Aggregation Filtering with Diversification for Graph Convolutional Neural Networks
Dec 21, 2022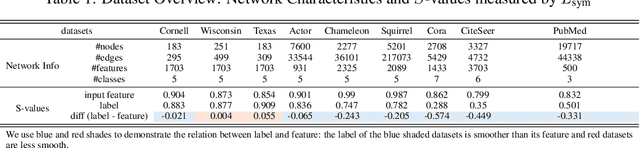
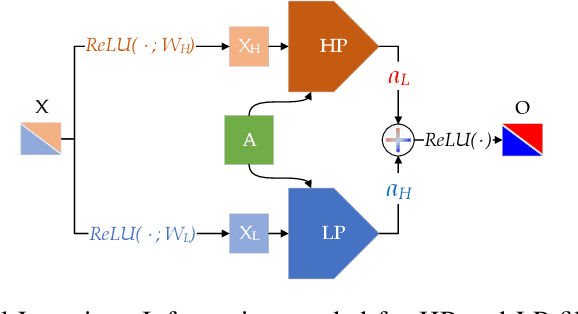

The core operation of current Graph Neural Networks (GNNs) is the aggregation enabled by the graph Laplacian or message passing, which filters the neighborhood information of nodes. Though effective for various tasks, in this paper, we show that they are potentially a problematic factor underlying all GNN models for learning on certain datasets, as they force the node representations similar, making the nodes gradually lose their identity and become indistinguishable. Hence, we augment the aggregation operations with their dual, i.e. diversification operators that make the node more distinct and preserve the identity. Such augmentation replaces the aggregation with a two-channel filtering process that, in theory, is beneficial for enriching the node representations. In practice, the proposed two-channel filters can be easily patched on existing GNN methods with diverse training strategies, including spectral and spatial (message passing) methods. In the experiments, we observe desired characteristics of the models and significant performance boost upon the baselines on 9 node classification tasks.
Revisiting Heterophily For Graph Neural Networks
Oct 14, 2022
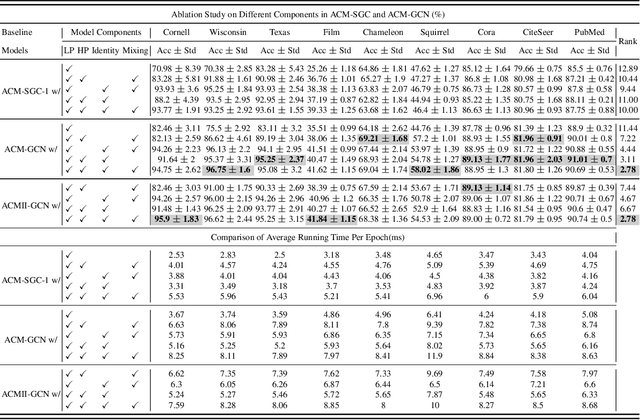
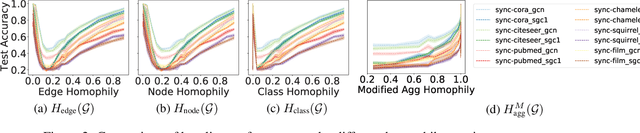
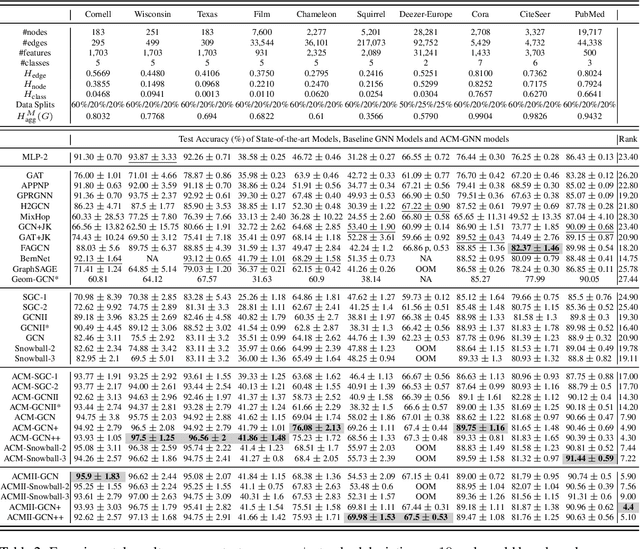
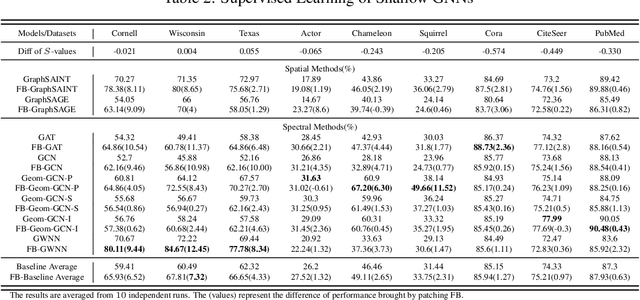
Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by using graph structures based on the relational inductive bias (homophily assumption). While GNNs have been commonly believed to outperform NNs in real-world tasks, recent work has identified a non-trivial set of datasets where their performance compared to NNs is not satisfactory. Heterophily has been considered the main cause of this empirical observation and numerous works have been put forward to address it. In this paper, we first revisit the widely used homophily metrics and point out that their consideration of only graph-label consistency is a shortcoming. Then, we study heterophily from the perspective of post-aggregation node similarity and define new homophily metrics, which are potentially advantageous compared to existing ones. Based on this investigation, we prove that some harmful cases of heterophily can be effectively addressed by local diversification operation. Then, we propose the Adaptive Channel Mixing (ACM), a framework to adaptively exploit aggregation, diversification and identity channels node-wisely to extract richer localized information for diverse node heterophily situations. ACM is more powerful than the commonly used uni-channel framework for node classification tasks on heterophilic graphs and is easy to be implemented in baseline GNN layers. When evaluated on 10 benchmark node classification tasks, ACM-augmented baselines consistently achieve significant performance gain, exceeding state-of-the-art GNNs on most tasks without incurring significant computational burden.
Temporal Abstractions-Augmented Temporally Contrastive Learning: An Alternative to the Laplacian in RL
Mar 21, 2022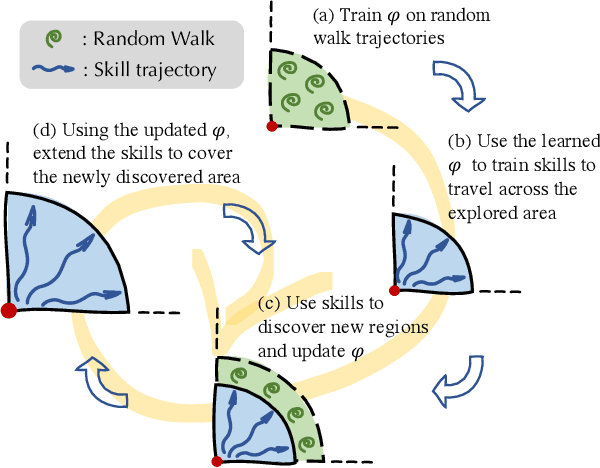
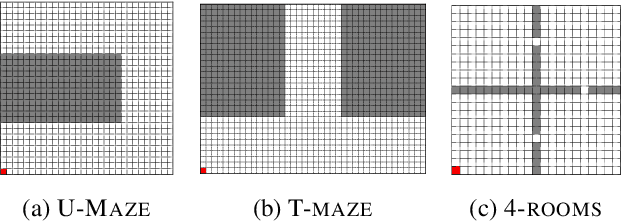

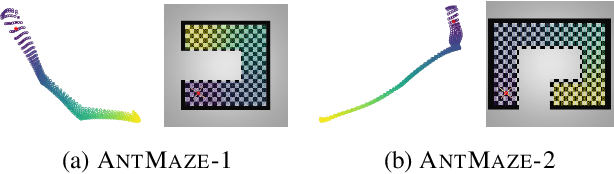
In reinforcement learning, the graph Laplacian has proved to be a valuable tool in the task-agnostic setting, with applications ranging from skill discovery to reward shaping. Recently, learning the Laplacian representation has been framed as the optimization of a temporally-contrastive objective to overcome its computational limitations in large (or continuous) state spaces. However, this approach requires uniform access to all states in the state space, overlooking the exploration problem that emerges during the representation learning process. In this work, we propose an alternative method that is able to recover, in a non-uniform-prior setting, the expressiveness and the desired properties of the Laplacian representation. We do so by combining the representation learning with a skill-based covering policy, which provides a better training distribution to extend and refine the representation. We also show that a simple augmentation of the representation objective with the learned temporal abstractions improves dynamics-awareness and helps exploration. We find that our method succeeds as an alternative to the Laplacian in the non-uniform setting and scales to challenging continuous control environments. Finally, even if our method is not optimized for skill discovery, the learned skills can successfully solve difficult continuous navigation tasks with sparse rewards, where standard skill discovery approaches are no so effective.
Is Heterophily A Real Nightmare For Graph Neural Networks To Do Node Classification?
Sep 12, 2021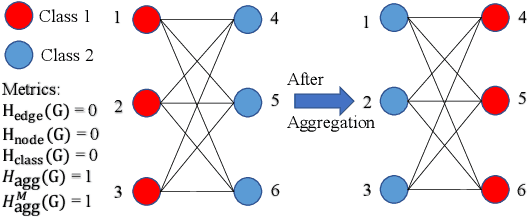
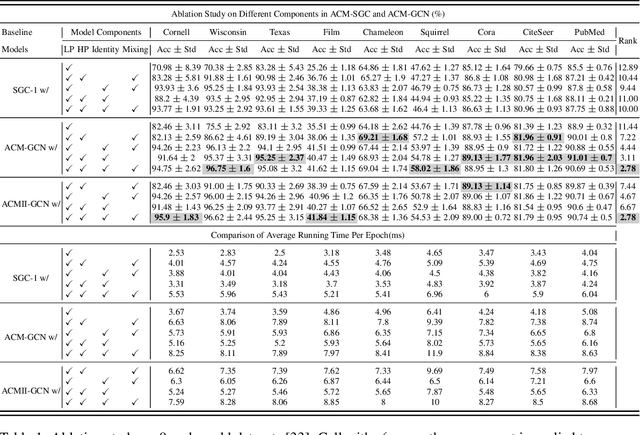
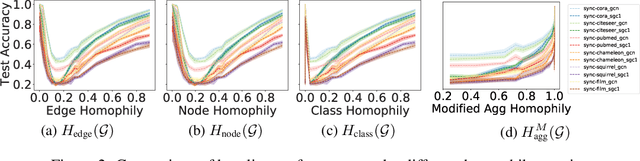
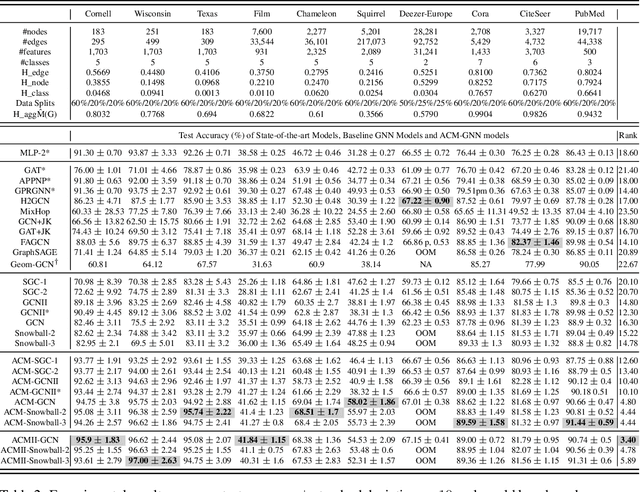
Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by using the graph structures based on the relational inductive bias (homophily assumption). Though GNNs are believed to outperform NNs in real-world tasks, performance advantages of GNNs over graph-agnostic NNs seem not generally satisfactory. Heterophily has been considered as a main cause and numerous works have been put forward to address it. In this paper, we first show that not all cases of heterophily are harmful for GNNs with aggregation operation. Then, we propose new metrics based on a similarity matrix which considers the influence of both graph structure and input features on GNNs. The metrics demonstrate advantages over the commonly used homophily metrics by tests on synthetic graphs. From the metrics and the observations, we find some cases of harmful heterophily can be addressed by diversification operation. With this fact and knowledge of filterbanks, we propose the Adaptive Channel Mixing (ACM) framework to adaptively exploit aggregation, diversification and identity channels in each GNN layer to address harmful heterophily. We validate the ACM-augmented baselines with 10 real-world node classification tasks. They consistently achieve significant performance gain and exceed the state-of-the-art GNNs on most of the tasks without incurring significant computational burden.
A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning
Jun 03, 2021
We present an end-to-end, model-based deep reinforcement learning agent which dynamically attends to relevant parts of its state, in order to plan and to generalize better out-of-distribution. The agent's architecture uses a set representation and a bottleneck mechanism, forcing the number of entities to which the agent attends at each planning step to be small. In experiments with customized MiniGrid environments with different dynamics, we observe that the design allows agents to learn to plan effectively, by attending to the relevant objects, leading to better out-of-distribution generalization.
Complete the Missing Half: Augmenting Aggregation Filtering with Diversification for Graph Convolutional Networks
Sep 15, 2020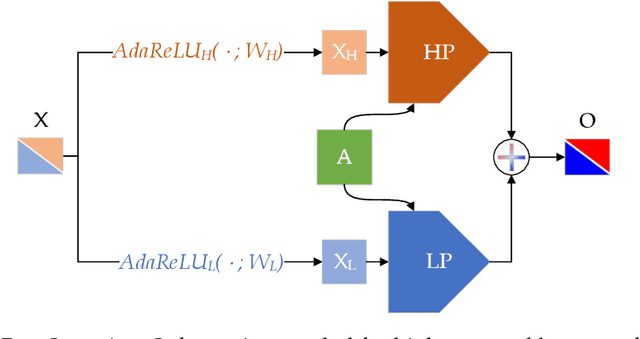
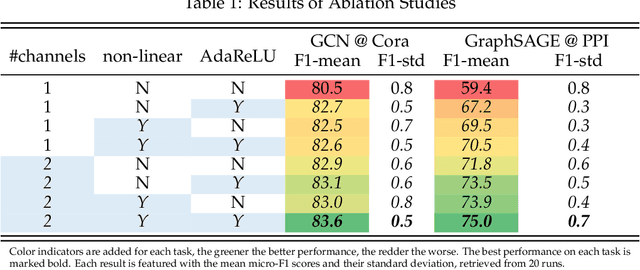
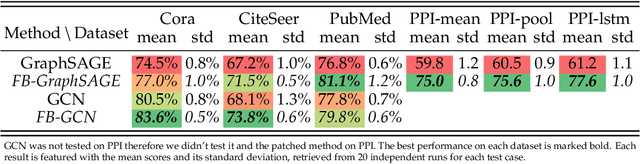
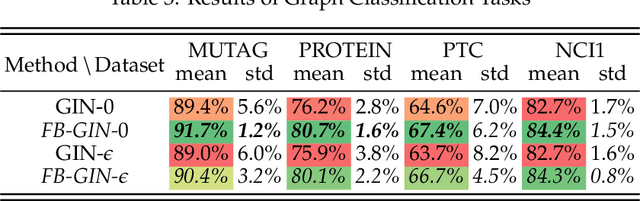
The core operation of current Graph Neural Networks (GNNs) is the aggregation enabled by the graph Laplacian or message passing, which filters the neighborhood node information. Though effective for various tasks, in this paper, we show that they are potentially a problematic factor underlying all GNN methods for learning on certain datasets, as they force the node representations similar, making the nodes gradually lose their identity and become indistinguishable. Hence, we augment the aggregation operations with their dual, i.e. diversification operators that make the node more distinct and preserve the identity. Such augmentation replaces the aggregation with a two-channel filtering process that, in theory, is beneficial for enriching the node representations. In practice, the proposed two-channel filters can be easily patched on existing GNN methods with diverse training strategies, including spectral and spatial (message passing) methods. In the experiments, we observe desired characteristics of the models and significant performance boost upon the baselines on 9 node classification tasks.
Training Matters: Unlocking Potentials of Deeper Graph Convolutional Neural Networks
Aug 20, 2020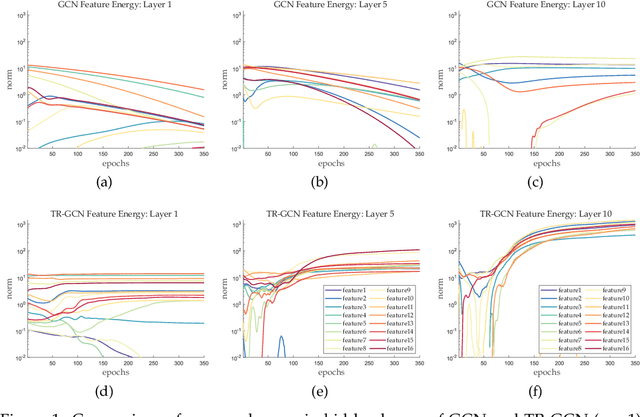
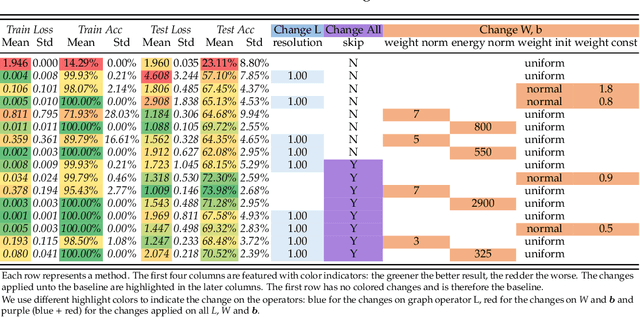
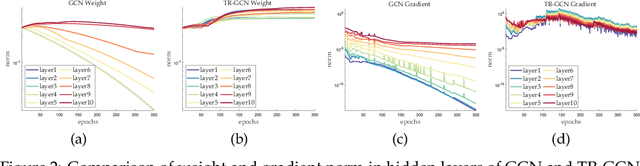
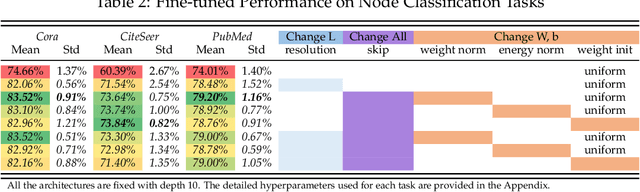
The performance limit of Graph Convolutional Networks (GCNs) and the fact that we cannot stack more of them to increase the performance, which we usually do for other deep learning paradigms, are pervasively thought to be caused by the limitations of the GCN layers, including insufficient expressive power, etc. However, if so, for a fixed architecture, it would be unlikely to lower the training difficulty and to improve performance by changing only the training procedure, which we show in this paper not only possible but possible in several ways. This paper first identify the training difficulty of GCNs from the perspective of graph signal energy loss. More specifically, we find that the loss of energy in the backward pass during training nullifies the learning of the layers closer to the input. Then, we propose several methodologies to mitigate the training problem by slightly modifying the GCN operator, from the energy perspective. After empirical validation, we confirm that these changes of operator lead to significant decrease in the training difficulties and notable performance boost, without changing the composition of parameters. With these, we conclude that the root cause of the problem is more likely the training difficulty than the others.
META-Learning Eligibility Traces for More Sample Efficient Temporal Difference Learning
Jun 16, 2020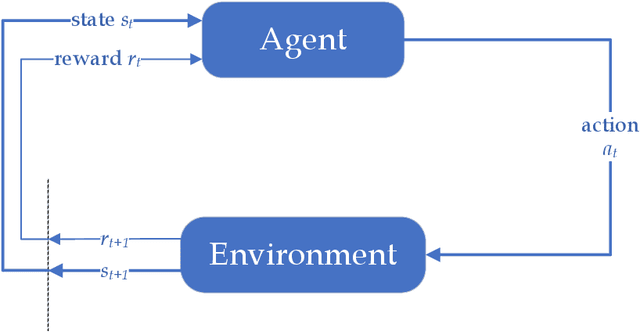
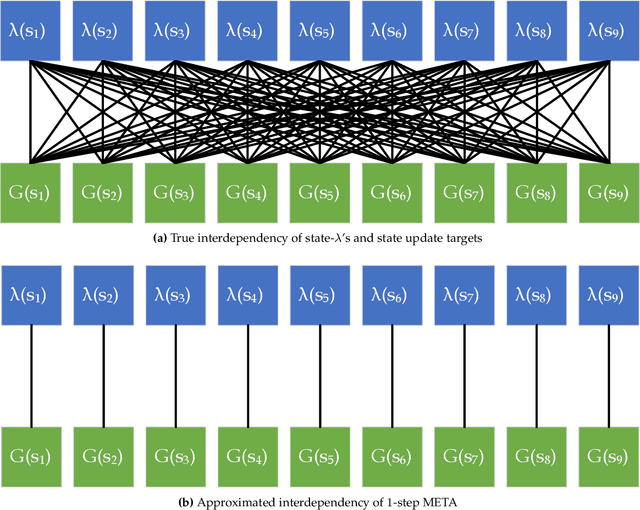
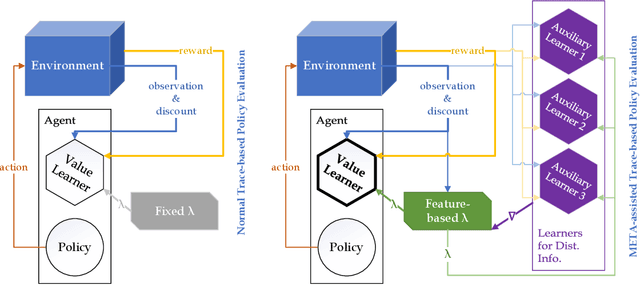
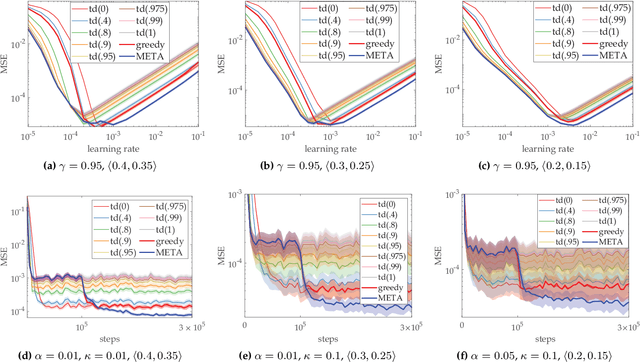
Temporal-Difference (TD) learning is a standard and very successful reinforcement learning approach, at the core of both algorithms that learn the value of a given policy, as well as algorithms which learn how to improve policies. TD-learning with eligibility traces provides a way to do temporal credit assignment, i.e. decide which portion of a reward should be assigned to predecessor states that occurred at different previous times, controlled by a parameter $\lambda$. However, tuning this parameter can be time-consuming, and not tuning it can lead to inefficient learning. To improve the sample efficiency of TD-learning, we propose a meta-learning method for adjusting the eligibility trace parameter, in a state-dependent manner. The adaptation is achieved with the help of auxiliary learners that learn distributional information about the update targets online, incurring roughly the same computational complexity per step as the usual value learner. Our approach can be used both in on-policy and off-policy learning. We prove that, under some assumptions, the proposed method improves the overall quality of the update targets, by minimizing the overall target error. This method can be viewed as a plugin which can also be used to assist prediction with function approximation by meta-learning feature (observation)-based $\lambda$ online, or even in the control case to assist policy improvement. Our empirical evaluation demonstrates significant performance improvements, as well as improved robustness of the proposed algorithm to learning rate variation.