 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Denoising Knowledge Graphs For Retrieval Augmented Generation
Oct 16, 2025Retrieval-Augmented Generation (RAG) systems enable large language models (LLMs) instant access to relevant information for the generative process, demonstrating their superior performance in addressing common LLM challenges such as hallucination, factual inaccuracy, and the knowledge cutoff. Graph-based RAG further extends this paradigm by incorporating knowledge graphs (KGs) to leverage rich, structured connections for more precise and inferential responses. A critical challenge, however, is that most Graph-based RAG systems rely on LLMs for automated KG construction, often yielding noisy KGs with redundant entities and unreliable relationships. This noise degrades retrieval and generation performance while also increasing computational cost. Crucially, current research does not comprehensively address the denoising problem for LLM-generated KGs. In this paper, we introduce DEnoised knowledge Graphs for Retrieval Augmented Generation (DEG-RAG), a framework that addresses these challenges through: (1) entity resolution, which eliminates redundant entities, and (2) triple reflection, which removes erroneous relations. Together, these techniques yield more compact, higher-quality KGs that significantly outperform their unprocessed counterparts. Beyond the methods, we conduct a systematic evaluation of entity resolution for LLM-generated KGs, examining different blocking strategies, embedding choices, similarity metrics, and entity merging techniques. To the best of our knowledge, this is the first comprehensive exploration of entity resolution in LLM-generated KGs. Our experiments demonstrate that this straightforward approach not only drastically reduces graph size but also consistently improves question answering performance across diverse popular Graph-based RAG variants.
FanChuan: A Multilingual and Graph-Structured Benchmark For Parody Detection and Analysis
Feb 23, 2025



Parody is an emerging phenomenon on social media, where individuals imitate a role or position opposite to their own, often for humor, provocation, or controversy. Detecting and analyzing parody can be challenging and is often reliant on context, yet it plays a crucial role in understanding cultural values, promoting subcultures, and enhancing self-expression. However, the study of parody is hindered by limited available data and deficient diversity in current datasets. To bridge this gap, we built seven parody datasets from both English and Chinese corpora, with 14,755 annotated users and 21,210 annotated comments in total. To provide sufficient context information, we also collect replies and construct user-interaction graphs to provide richer contextual information, which is lacking in existing datasets. With these datasets, we test traditional methods and Large Language Models (LLMs) on three key tasks: (1) parody detection, (2) comment sentiment analysis with parody, and (3) user sentiment analysis with parody. Our extensive experiments reveal that parody-related tasks still remain challenging for all models, and contextual information plays a critical role. Interestingly, we find that, in certain scenarios, traditional sentence embedding methods combined with simple classifiers can outperform advanced LLMs, i.e. DeepSeek-R1 and GPT-o3, highlighting parody as a significant challenge for LLMs.
Rethinking Structure Learning For Graph Neural Networks
Nov 12, 2024
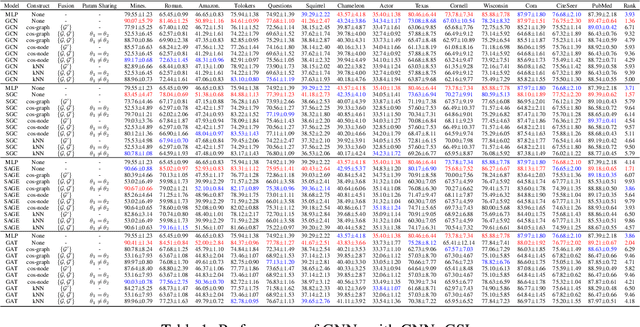
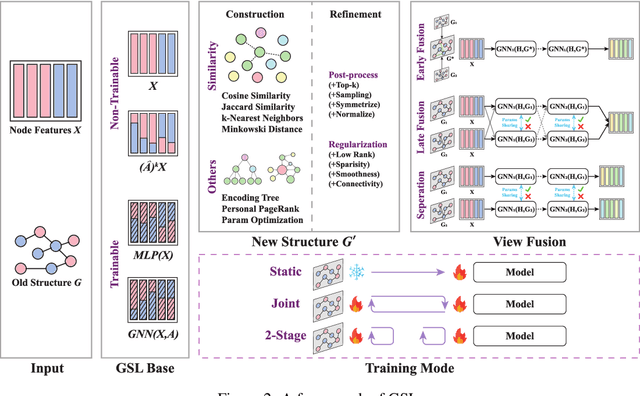

To improve the performance of Graph Neural Networks (GNNs), Graph Structure Learning (GSL) has been extensively applied to reconstruct or refine original graph structures, effectively addressing issues like heterophily, over-squashing, and noisy structures. While GSL is generally thought to improve GNN performance, it often leads to longer training times and more hyperparameter tuning. Besides, the distinctions among current GSL methods remain ambiguous from the perspective of GNN training, and there is a lack of theoretical analysis to quantify their effectiveness. Recent studies further suggest that, under fair comparisons with the same hyperparameter tuning, GSL does not consistently outperform baseline GNNs. This motivates us to ask a critical question: is GSL really useful for GNNs? To address this question, this paper makes two key contributions. First, we propose a new GSL framework, which includes three steps: GSL base (the representation used for GSL) construction, new structure construction, and view fusion, to better understand the effectiveness of GSL in GNNs. Second, after graph convolution, we analyze the differences in mutual information (MI) between node representations derived from the original topology and those from the newly constructed topology. Surprisingly, our empirical observations and theoretical analysis show that no matter which type of graph structure construction methods are used, after feeding the same GSL bases to the newly constructed graph, there is no MI gain compared to the original GSL bases. To fairly reassess the effectiveness of GSL, we conduct ablation experiments and find that it is the pretrained GSL bases that enhance GNN performance, and in most cases, GSL cannot improve GNN performance. This finding encourages us to rethink the essential components in GNNs, such as self-training and structural encoding, in GNN design rather than GSL.
Is Graph Convolution Always Beneficial For Every Feature?
Nov 12, 2024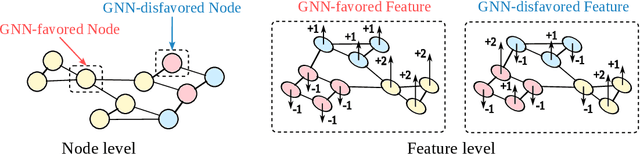

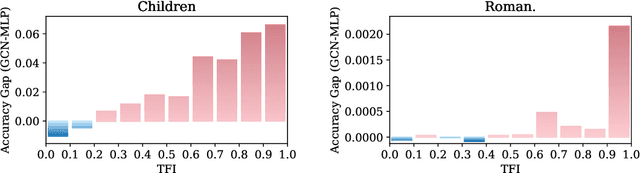

Graph Neural Networks (GNNs) have demonstrated strong capabilities in processing structured data. While traditional GNNs typically treat each feature dimension equally during graph convolution, we raise an important question: Is the graph convolution operation equally beneficial for each feature? If not, the convolution operation on certain feature dimensions can possibly lead to harmful effects, even worse than the convolution-free models. In prior studies, to assess the impacts of graph convolution on features, people proposed metrics based on feature homophily to measure feature consistency with the graph topology. However, these metrics have shown unsatisfactory alignment with GNN performance and have not been effectively employed to guide feature selection in GNNs. To address these limitations, we introduce a novel metric, Topological Feature Informativeness (TFI), to distinguish between GNN-favored and GNN-disfavored features, where its effectiveness is validated through both theoretical analysis and empirical observations. Based on TFI, we propose a simple yet effective Graph Feature Selection (GFS) method, which processes GNN-favored and GNN-disfavored features separately, using GNNs and non-GNN models. Compared to original GNNs, GFS significantly improves the extraction of useful topological information from each feature with comparable computational costs. Extensive experiments show that after applying GFS to 8 baseline and state-of-the-art (SOTA) GNN architectures across 10 datasets, 83.75% of the GFS-augmented cases show significant performance boosts. Furthermore, our proposed TFI metric outperforms other feature selection methods. These results validate the effectiveness of both GFS and TFI. Additionally, we demonstrate that GFS's improvements are robust to hyperparameter tuning, highlighting its potential as a universal method for enhancing various GNN architectures.
Flexible Diffusion Scopes with Parameterized Laplacian for Heterophilic Graph Learning
Sep 15, 2024



The ability of Graph Neural Networks (GNNs) to capture long-range and global topology information is limited by the scope of conventional graph Laplacian, leading to unsatisfactory performance on some datasets, particularly on heterophilic graphs. To address this limitation, we propose a new class of parameterized Laplacian matrices, which provably offers more flexibility in controlling the diffusion distance between nodes than the conventional graph Laplacian, allowing long-range information to be adaptively captured through diffusion on graph. Specifically, we first prove that the diffusion distance and spectral distance on graph have an order-preserving relationship. With this result, we demonstrate that the parameterized Laplacian can accelerate the diffusion of long-range information, and the parameters in the Laplacian enable flexibility of the diffusion scopes. Based on the theoretical results, we propose topology-guided rewiring mechanism to capture helpful long-range neighborhood information for heterophilic graphs. With this mechanism and the new Laplacian, we propose two GNNs with flexible diffusion scopes: namely the Parameterized Diffusion based Graph Convolutional Networks (PD-GCN) and Graph Attention Networks (PD-GAT). Synthetic experiments reveal the high correlations between the parameters of the new Laplacian and the performance of parameterized GNNs under various graph homophily levels, which verifies that our new proposed GNNs indeed have the ability to adjust the parameters to adaptively capture the global information for different levels of heterophilic graphs. They also outperform the state-of-the-art (SOTA) models on 6 out of 7 real-world benchmark datasets, which further confirms their superiority.
Are Heterophily-Specific GNNs and Homophily Metrics Really Effective? Evaluation Pitfalls and New Benchmarks
Sep 09, 2024



Over the past decade, Graph Neural Networks (GNNs) have achieved great success on machine learning tasks with relational data. However, recent studies have found that heterophily can cause significant performance degradation of GNNs, especially on node-level tasks. Numerous heterophilic benchmark datasets have been put forward to validate the efficacy of heterophily-specific GNNs and various homophily metrics have been designed to help people recognize these malignant datasets. Nevertheless, there still exist multiple pitfalls that severely hinder the proper evaluation of new models and metrics. In this paper, we point out three most serious pitfalls: 1) a lack of hyperparameter tuning; 2) insufficient model evaluation on the real challenging heterophilic datasets; 3) missing quantitative evaluation benchmark for homophily metrics on synthetic graphs. To overcome these challenges, we first train and fine-tune baseline models on $27$ most widely used benchmark datasets, categorize them into three distinct groups: malignant, benign and ambiguous heterophilic datasets, and identify the real challenging subsets of tasks. To our best knowledge, we are the first to propose such taxonomy. Then, we re-evaluate $10$ heterophily-specific state-of-the-arts (SOTA) GNNs with fine-tuned hyperparameters on different groups of heterophilic datasets. Based on the model performance, we reassess their effectiveness on addressing heterophily challenge. At last, we evaluate $11$ popular homophily metrics on synthetic graphs with three different generation approaches. To compare the metrics strictly, we propose the first quantitative evaluation method based on Fr\'echet distance.
Reactzyme: A Benchmark for Enzyme-Reaction Prediction
Aug 24, 2024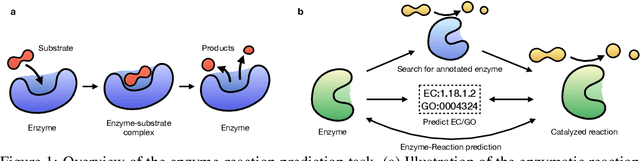

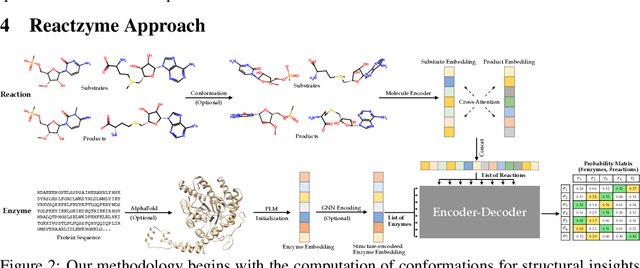
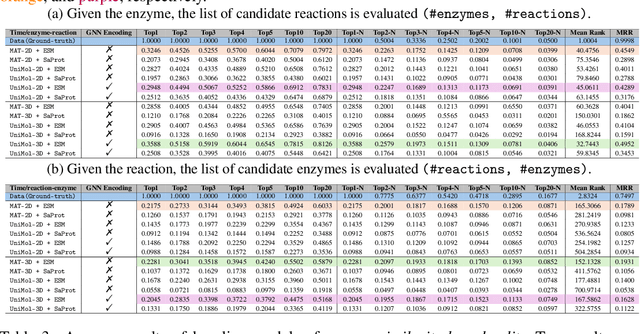
Enzymes, with their specific catalyzed reactions, are necessary for all aspects of life, enabling diverse biological processes and adaptations. Predicting enzyme functions is essential for understanding biological pathways, guiding drug development, enhancing bioproduct yields, and facilitating evolutionary studies. Addressing the inherent complexities, we introduce a new approach to annotating enzymes based on their catalyzed reactions. This method provides detailed insights into specific reactions and is adaptable to newly discovered reactions, diverging from traditional classifications by protein family or expert-derived reaction classes. We employ machine learning algorithms to analyze enzyme reaction datasets, delivering a much more refined view on the functionality of enzymes. Our evaluation leverages the largest enzyme-reaction dataset to date, derived from the SwissProt and Rhea databases with entries up to January 8, 2024. We frame the enzyme-reaction prediction as a retrieval problem, aiming to rank enzymes by their catalytic ability for specific reactions. With our model, we can recruit proteins for novel reactions and predict reactions in novel proteins, facilitating enzyme discovery and function annotation.
The Heterophilic Graph Learning Handbook: Benchmarks, Models, Theoretical Analysis, Applications and Challenges
Jul 12, 2024



Homophily principle, \ie{} nodes with the same labels or similar attributes are more likely to be connected, has been commonly believed to be the main reason for the superiority of Graph Neural Networks (GNNs) over traditional Neural Networks (NNs) on graph-structured data, especially on node-level tasks. However, recent work has identified a non-trivial set of datasets where GNN's performance compared to the NN's is not satisfactory. Heterophily, i.e. low homophily, has been considered the main cause of this empirical observation. People have begun to revisit and re-evaluate most existing graph models, including graph transformer and its variants, in the heterophily scenario across various kinds of graphs, e.g. heterogeneous graphs, temporal graphs and hypergraphs. Moreover, numerous graph-related applications are found to be closely related to the heterophily problem. In the past few years, considerable effort has been devoted to studying and addressing the heterophily issue. In this survey, we provide a comprehensive review of the latest progress on heterophilic graph learning, including an extensive summary of benchmark datasets and evaluation of homophily metrics on synthetic graphs, meticulous classification of the most updated supervised and unsupervised learning methods, thorough digestion of the theoretical analysis on homophily/heterophily, and broad exploration of the heterophily-related applications. Notably, through detailed experiments, we are the first to categorize benchmark heterophilic datasets into three sub-categories: malignant, benign and ambiguous heterophily. Malignant and ambiguous datasets are identified as the real challenging datasets to test the effectiveness of new models on the heterophily challenge. Finally, we propose several challenges and future directions for heterophilic graph representation learning.
What Is Missing In Homophily? Disentangling Graph Homophily For Graph Neural Networks
Jun 27, 2024



Graph homophily refers to the phenomenon that connected nodes tend to share similar characteristics. Understanding this concept and its related metrics is crucial for designing effective Graph Neural Networks (GNNs). The most widely used homophily metrics, such as edge or node homophily, quantify such "similarity" as label consistency across the graph topology. These metrics are believed to be able to reflect the performance of GNNs, especially on node-level tasks. However, many recent studies have empirically demonstrated that the performance of GNNs does not always align with homophily metrics, and how homophily influences GNNs still remains unclear and controversial. Then, a crucial question arises: What is missing in our current understanding of homophily? To figure out the missing part, in this paper, we disentangle the graph homophily into $3$ aspects: label, structural, and feature homophily, providing a more comprehensive understanding of GNN performance. To investigate their synergy, we propose a Contextual Stochastic Block Model with $3$ types of Homophily (CSBM-3H), where the topology and feature generation are controlled by the $3$ metrics. Based on the theoretical analysis of CSBM-3H, we derive a new composite metric, named Tri-Hom, that considers all $3$ aspects and overcomes the limitations of conventional homophily metrics. The theoretical conclusions and the effectiveness of Tri-Hom have been verified through synthetic experiments on CSBM-3H. In addition, we conduct experiments on $31$ real-world benchmark datasets and calculate the correlations between homophily metrics and model performance. Tri-Hom has significantly higher correlation values than $17$ existing metrics that only focus on a single homophily aspect, demonstrating its superiority and the importance of homophily synergy. Our code is available at \url{https://github.com/zylMozart/Disentangle_GraphHom}.
GCEPNet: Graph Convolution-Enhanced Expectation Propagation for Massive MIMO Detection
Apr 23, 2024


Massive MIMO (multiple-input multiple-output) detection is an important topic in wireless communication and various machine learning based methods have been developed recently for this task. Expectation propagation (EP) and its variants are widely used for MIMO detection and have achieved the best performance. However, EP-based solvers fail to capture the correlation between unknown variables, leading to loss of information, and in addition, they are computationally expensive. In this paper, we show that the real-valued system can be modeled as spectral signal convolution on graph, through which the correlation between unknown variables can be captured. Based on this analysis, we propose graph convolution-enhanced expectation propagation (GCEPNet), a graph convolution-enhanced EP detector. GCEPNet incorporates data-dependent attention scores into Chebyshev polynomial for powerful graph convolution with better generalization capacity. It enables a better estimation of the cavity distribution for EP and empirically achieves the state-of-the-art (SOTA) MIMO detection performance with much faster inference speed. To our knowledge, we are the first to shed light on the connection between the system model and graph convolution, and the first to design the data-dependent attention scores for graph convolution.