 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Objects to Anywhere: A Holistic Benchmark for Multi-level Visual Grounding in 3D Scenes
Jun 05, 2025
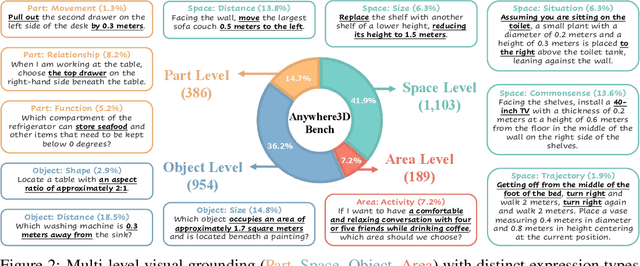

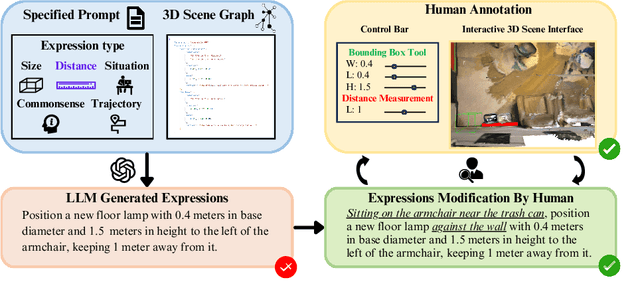
3D visual grounding has made notable progress in localizing objects within complex 3D scenes. However, grounding referring expressions beyond objects in 3D scenes remains unexplored. In this paper, we introduce Anywhere3D-Bench, a holistic 3D visual grounding benchmark consisting of 2,632 referring expression-3D bounding box pairs spanning four different grounding levels: human-activity areas, unoccupied space beyond objects, objects in the scene, and fine-grained object parts. We assess a range of state-of-the-art 3D visual grounding methods alongside large language models (LLMs) and multimodal LLMs (MLLMs) on Anywhere3D-Bench. Experimental results reveal that space-level and part-level visual grounding pose the greatest challenges: space-level tasks require a more comprehensive spatial reasoning ability, for example, modeling distances and spatial relations within 3D space, while part-level tasks demand fine-grained perception of object composition. Even the best performance model, OpenAI o4-mini, achieves only 23.57% accuracy on space-level tasks and 33.94% on part-level tasks, significantly lower than its performance on area-level and object-level tasks. These findings underscore a critical gap in current models' capacity to understand and reason about 3D scene beyond object-level semantics.
Rethinking Structure Learning For Graph Neural Networks
Nov 12, 2024
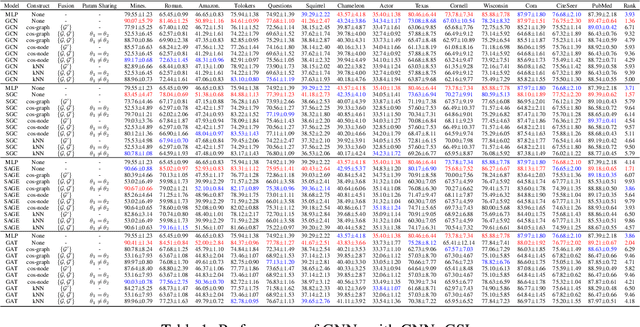
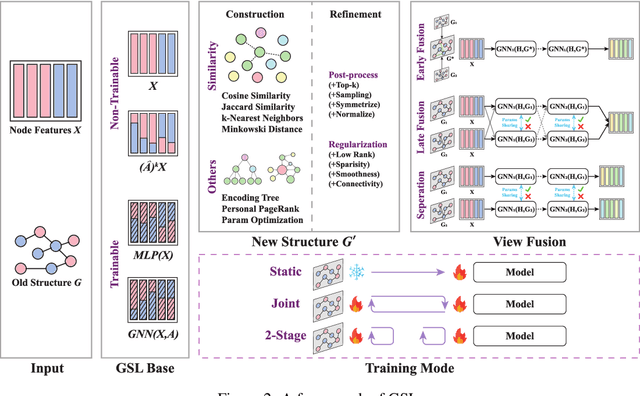

To improve the performance of Graph Neural Networks (GNNs), Graph Structure Learning (GSL) has been extensively applied to reconstruct or refine original graph structures, effectively addressing issues like heterophily, over-squashing, and noisy structures. While GSL is generally thought to improve GNN performance, it often leads to longer training times and more hyperparameter tuning. Besides, the distinctions among current GSL methods remain ambiguous from the perspective of GNN training, and there is a lack of theoretical analysis to quantify their effectiveness. Recent studies further suggest that, under fair comparisons with the same hyperparameter tuning, GSL does not consistently outperform baseline GNNs. This motivates us to ask a critical question: is GSL really useful for GNNs? To address this question, this paper makes two key contributions. First, we propose a new GSL framework, which includes three steps: GSL base (the representation used for GSL) construction, new structure construction, and view fusion, to better understand the effectiveness of GSL in GNNs. Second, after graph convolution, we analyze the differences in mutual information (MI) between node representations derived from the original topology and those from the newly constructed topology. Surprisingly, our empirical observations and theoretical analysis show that no matter which type of graph structure construction methods are used, after feeding the same GSL bases to the newly constructed graph, there is no MI gain compared to the original GSL bases. To fairly reassess the effectiveness of GSL, we conduct ablation experiments and find that it is the pretrained GSL bases that enhance GNN performance, and in most cases, GSL cannot improve GNN performance. This finding encourages us to rethink the essential components in GNNs, such as self-training and structural encoding, in GNN design rather than GSL.
Task-oriented Sequential Grounding in 3D Scenes
Aug 07, 2024


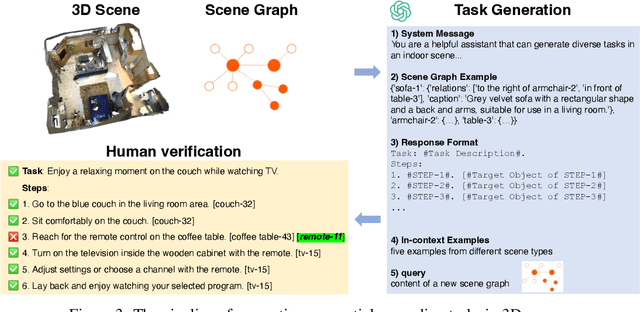
Grounding natural language in physical 3D environments is essential for the advancement of embodied artificial intelligence. Current datasets and models for 3D visual grounding predominantly focus on identifying and localizing objects from static, object-centric descriptions. These approaches do not adequately address the dynamic and sequential nature of task-oriented grounding necessary for practical applications. In this work, we propose a new task: Task-oriented Sequential Grounding in 3D scenes, wherein an agent must follow detailed step-by-step instructions to complete daily activities by locating a sequence of target objects in indoor scenes. To facilitate this task, we introduce SG3D, a large-scale dataset containing 22,346 tasks with 112,236 steps across 4,895 real-world 3D scenes. The dataset is constructed using a combination of RGB-D scans from various 3D scene datasets and an automated task generation pipeline, followed by human verification for quality assurance. We adapted three state-of-the-art 3D visual grounding models to the sequential grounding task and evaluated their performance on SG3D. Our results reveal that while these models perform well on traditional benchmarks, they face significant challenges with task-oriented sequential grounding, underscoring the need for further research in this area.
Unifying 3D Vision-Language Understanding via Promptable Queries
May 19, 2024



A unified model for 3D vision-language (3D-VL) understanding is expected to take various scene representations and perform a wide range of tasks in a 3D scene. However, a considerable gap exists between existing methods and such a unified model, due to the independent application of representation and insufficient exploration of 3D multi-task training. In this paper, we introduce PQ3D, a unified model capable of using Promptable Queries to tackle a wide range of 3D-VL tasks, from low-level instance segmentation to high-level reasoning and planning. This is achieved through three key innovations: (1) unifying various 3D scene representations (i.e., voxels, point clouds, multi-view images) into a shared 3D coordinate space by segment-level grouping, (2) an attention-based query decoder for task-specific information retrieval guided by prompts, and (3) universal output heads for different tasks to support multi-task training. Tested across ten diverse 3D-VL datasets, PQ3D demonstrates impressive performance on these tasks, setting new records on most benchmarks. Particularly, PQ3D improves the state-of-the-art on ScanNet200 by 1.8% (AP), ScanRefer by 5.4% (acc@0.5), Multi3DRefer by 11.7% (F1@0.5), and Scan2Cap by 13.4% (CIDEr@0.5). Moreover, PQ3D supports flexible inference with individual or combined forms of available 3D representations, e.g., solely voxel input.
Minimum Latency Deep Online Video Stabilization
Dec 05, 2022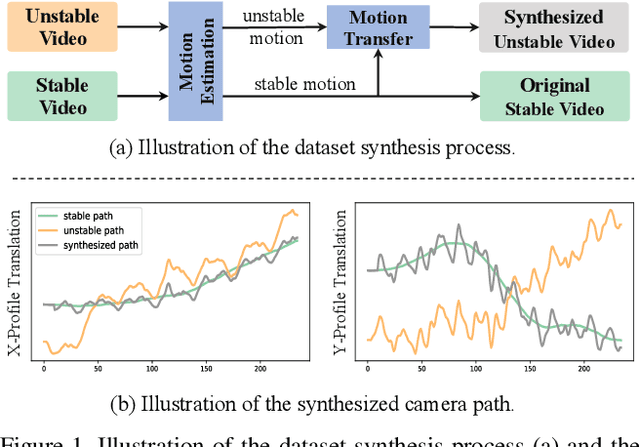



We present a novel camera path optimization framework for the task of online video stabilization. Typically, a stabilization pipeline consists of three steps: motion estimating, path smoothing, and novel view rendering. Most previous methods concentrate on motion estimation, proposing various global or local motion models. In contrast, path optimization receives relatively less attention, especially in the important online setting, where no future frames are available. In this work, we adopt recent off-the-shelf high-quality deep motion models for the motion estimation to recover the camera trajectory and focus on the latter two steps. Our network takes a short 2D camera path in a sliding window as input and outputs the stabilizing warp field of the last frame in the window, which warps the coming frame to its stabilized position. A hybrid loss is well-defined to constrain the spatial and temporal consistency. In addition, we build a motion dataset that contains stable and unstable motion pairs for the training. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art online methods both qualitatively and quantitatively and achieves comparable performance to offline methods.
The Effect of Training Parameters and Mechanisms on Decentralized Federated Learning based on MNIST Dataset
Aug 07, 2021

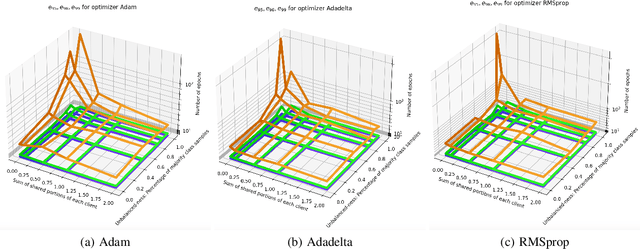

Federated Learning is an algorithm suited for training models on decentralized data, but the requirement of a central "server" node is a bottleneck. In this document, we first introduce the notion of Decentralized Federated Learning (DFL). We then perform various experiments on different setups, such as changing model aggregation frequency, switching from independent and identically distributed (IID) dataset partitioning to non-IID partitioning with partial global sharing, using different optimization methods across clients, and breaking models into segments with partial sharing. All experiments are run on the MNIST handwritten digits dataset. We observe that those altered training procedures are generally robust, albeit non-optimal. We also observe failures in training when the variance between model weights is too large. The open-source experiment code is accessible through GitHub\footnote{Code was uploaded at \url{https://github.com/zhzhang2018/DecentralizedFL}}.