 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeTAD: Spiking Neural Networks for End-to-End Temporal Action Detection
Jun 10, 2026Video understanding is a crucial part of computer vision, with numerous application scenarios. With the increasing popularity of mobile devices, an increasing number of efforts are trying to deploy video understanding models on them. However, existing video understanding models are difficult to deploy due to their large size and prohibitive power consumption. Spiking Neural Networks (SNNs) have shown bioplausibility and low power advantages over Artificial Neural Networks (ANNs), especially on neuromorphic chips which are regarded as essential components of future mobile devices. However, excessively long conversion time-steps and severe performance degradation problems limit their application. To solve the problems above, we explore the application of SNNs on temporal action detection (TAD), which is an important task in video understanding, and propose the first SNN-based end-to-end TAD architecture coined as SpikeTAD. While maintaining extremely low power consumption, SpikeTAD achieves an average mAP of 67.2% in THUMOS14 and 37.42% in ActivityNet-1.3, demonstrating the feasibility of a low-power TAD model. Our code is available at https://github.com/MCG-NJU/SpikeTAD.
Mixture of Style Experts for Diverse Image Stylization
Mar 17, 2026Diffusion-based stylization has advanced significantly, yet existing methods are limited to color-driven transformations, neglecting complex semantics and material details.We introduce StyleExpert, a semantic-aware framework based on the Mixture of Experts (MoE). Our framework employs a unified style encoder, trained on our large-scale dataset of content-style-stylized triplets, to embed diverse styles into a consistent latent space. This embedding is then used to condition a similarity-aware gating mechanism, which dynamically routes styles to specialized experts within the MoE architecture. Leveraging this MoE architecture, our method adeptly handles diverse styles spanning multiple semantic levels, from shallow textures to deep semantics. Extensive experiments show that StyleExpert outperforms existing approaches in preserving semantics and material details, while generalizing to unseen styles. Our code and collected images are available at the project page: https://hh-lg.github.io/StyleExpert-Page/.
ConsisSR: Delving Deep into Consistency in Diffusion-based Image Super-Resolution
Oct 17, 2024



Real-world image super-resolution (Real-ISR) aims at restoring high-quality (HQ) images from low-quality (LQ) inputs corrupted by unknown and complex degradations. In particular, pretrained text-to-image (T2I) diffusion models provide strong generative priors to reconstruct credible and intricate details. However, T2I generation focuses on semantic consistency while Real-ISR emphasizes pixel-level reconstruction, which hinders existing methods from fully exploiting diffusion priors. To address this challenge, we introduce ConsisSR to handle both semantic and pixel-level consistency. Specifically, compared to coarse-grained text prompts, we exploit the more powerful CLIP image embedding and effectively leverage both modalities through our Hybrid Prompt Adapter (HPA) for semantic guidance. Secondly, we introduce Time-aware Latent Augmentation (TALA) to mitigate the inherent gap between T2I generation and Real-ISR consistency requirements. By randomly mixing LQ and HQ latent inputs, our model not only handle timestep-specific diffusion noise but also refine the accumulated latent representations. Last but not least, our GAN-Embedding strategy employs the pretrained Real-ESRGAN model to refine the diffusion start point. This accelerates the inference process to 10 steps while preserving sampling quality, in a training-free manner. Our method demonstrates state-of-the-art performance among both full-scale and accelerated models. The code will be made publicly available.
Bias in Generative AI
Mar 05, 2024This study analyzed images generated by three popular generative artificial intelligence (AI) tools - Midjourney, Stable Diffusion, and DALLE 2 - representing various occupations to investigate potential bias in AI generators. Our analysis revealed two overarching areas of concern in these AI generators, including (1) systematic gender and racial biases, and (2) subtle biases in facial expressions and appearances. Firstly, we found that all three AI generators exhibited bias against women and African Americans. Moreover, we found that the evident gender and racial biases uncovered in our analysis were even more pronounced than the status quo when compared to labor force statistics or Google images, intensifying the harmful biases we are actively striving to rectify in our society. Secondly, our study uncovered more nuanced prejudices in the portrayal of emotions and appearances. For example, women were depicted as younger with more smiles and happiness, while men were depicted as older with more neutral expressions and anger, posing a risk that generative AI models may unintentionally depict women as more submissive and less competent than men. Such nuanced biases, by their less overt nature, might be more problematic as they can permeate perceptions unconsciously and may be more difficult to rectify. Although the extent of bias varied depending on the model, the direction of bias remained consistent in both commercial and open-source AI generators. As these tools become commonplace, our study highlights the urgency to identify and mitigate various biases in generative AI, reinforcing the commitment to ensuring that AI technologies benefit all of humanity for a more inclusive future.
Decoupling Degradation and Content Processing for Adverse Weather Image Restoration
Dec 08, 2023



Adverse weather image restoration strives to recover clear images from those affected by various weather types, such as rain, haze, and snow. Each weather type calls for a tailored degradation removal approach due to its unique impact on images. Conversely, content reconstruction can employ a uniform approach, as the underlying image content remains consistent. Although previous techniques can handle multiple weather types within a single network, they neglect the crucial distinction between these two processes, limiting the quality of restored images. This work introduces a novel adverse weather image restoration method, called DDCNet, which decouples the degradation removal and content reconstruction process at the feature level based on their channel statistics. Specifically, we exploit the unique advantages of the Fourier transform in both these two processes: (1) the degradation information is mainly located in the amplitude component of the Fourier domain, and (2) the Fourier domain contains global information. The former facilitates channel-dependent degradation removal operation, allowing the network to tailor responses to various adverse weather types; the latter, by integrating Fourier's global properties into channel-independent content features, enhances network capacity for consistent global content reconstruction. We further augment the degradation removal process with a degradation mapping loss function. Extensive experiments demonstrate our method achieves state-of-the-art performance in multiple adverse weather removal benchmarks.
Optimal path planning of multi-agent cooperative systems with rigid formation
Sep 15, 2023

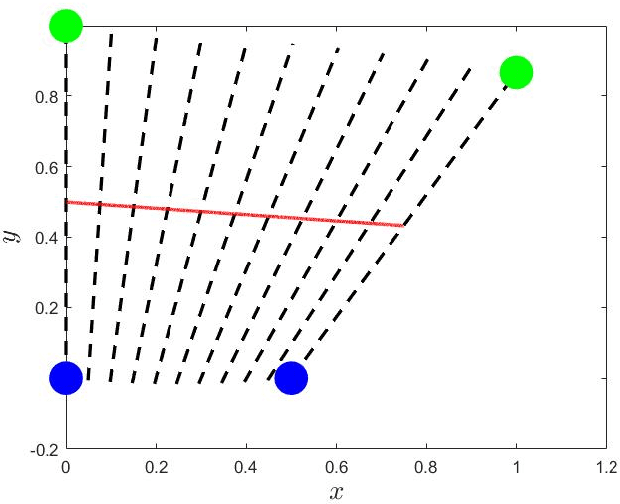

In this article, we consider the path-planning problem of a cooperative homogeneous robotic system with rigid formation. An optimal controller is designed for each agent in such rigid systems based on Pontryagin's minimum principle theory. We found that the optimal control for each agent is equivalent to the optimal control for the Center of Mass (CoM). This equivalence is then proved by using some analytical mechanics. Three examples are finally simulated to illustrate our theoretical results. One application could be utilizing this equivalence to simplify the original multi-agent optimal control problem.
Deep transfer learning for system identification using long short-term memory neural networks
Apr 06, 2022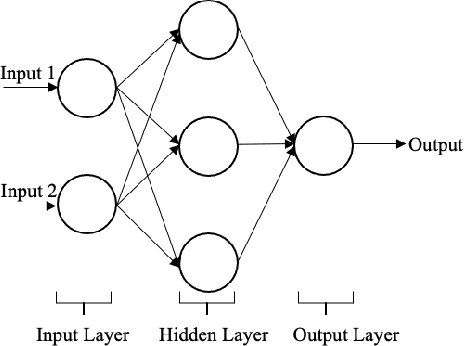
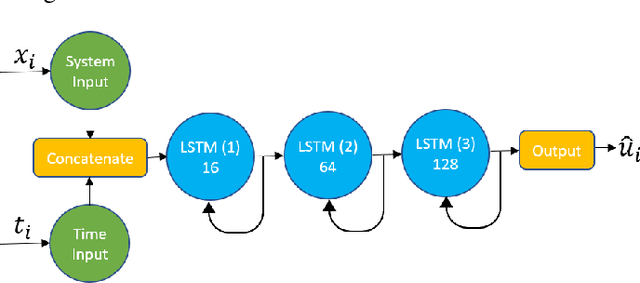
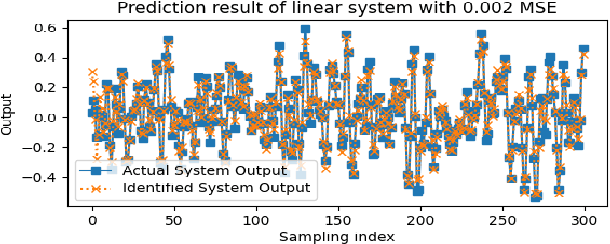
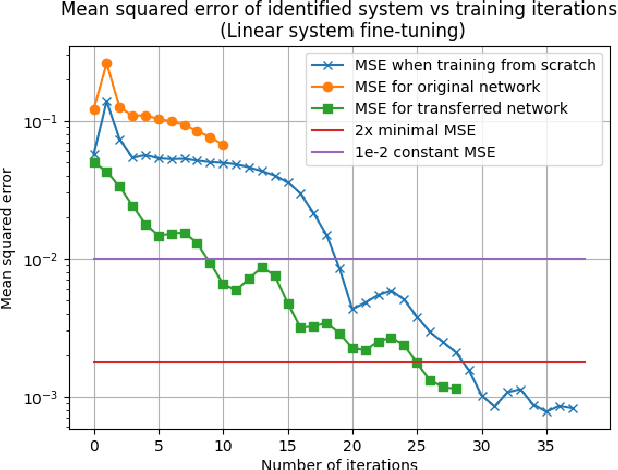
Recurrent neural networks (RNNs) have many advantages over more traditional system identification techniques. They may be applied to linear and nonlinear systems, and they require fewer modeling assumptions. However, these neural network models may also need larger amounts of data to learn and generalize. Furthermore, neural networks training is a time-consuming process. Hence, building upon long-short term memory neural networks (LSTM), this paper proposes using two types of deep transfer learning, namely parameter fine-tuning and freezing, to reduce the data and computation requirements for system identification. We apply these techniques to identify two dynamical systems, namely a second-order linear system and a Wiener-Hammerstein nonlinear system. Results show that compared with direct learning, our method accelerates learning by 10% to 50%, which also saves data and computing resources.
Motion-Aware Transformer For Occluded Person Re-identification
Feb 10, 2022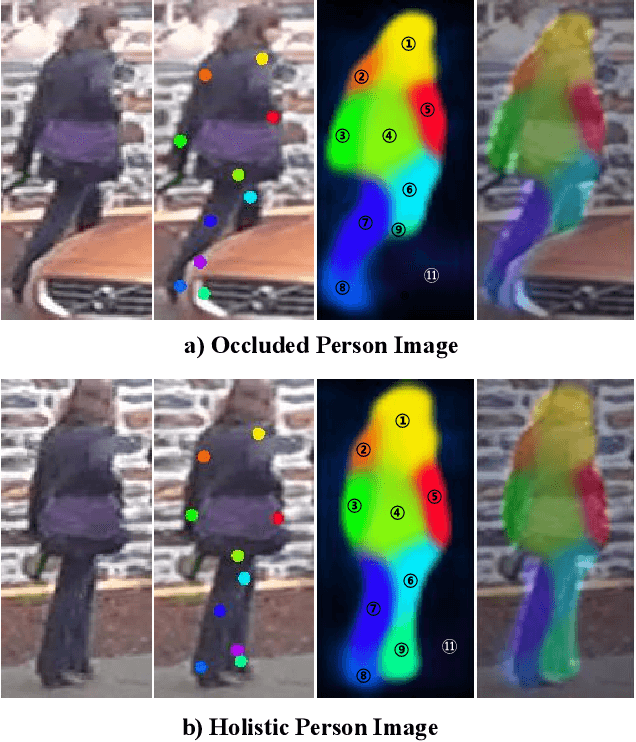
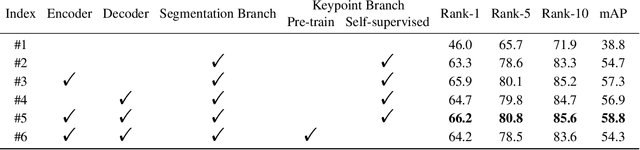
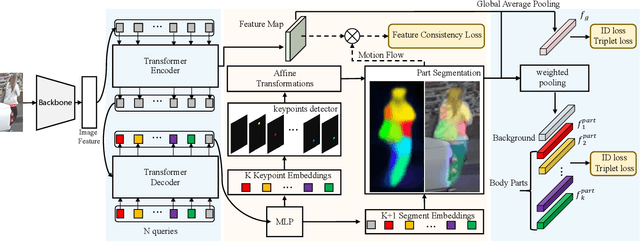
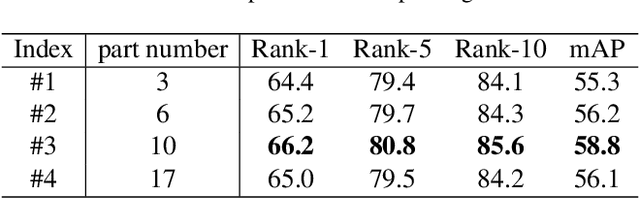
Recently, occluded person re-identification(Re-ID) remains a challenging task that people are frequently obscured by other people or obstacles, especially in a crowd massing situation. In this paper, we propose a self-supervised deep learning method to improve the location performance for human parts through occluded person Re-ID. Unlike previous works, we find that motion information derived from the photos of various human postures can help identify major human body components. Firstly, a motion-aware transformer encoder-decoder architecture is designed to obtain keypoints heatmaps and part-segmentation maps. Secondly, an affine transformation module is utilized to acquire motion information from the keypoint detection branch. Then the motion information will support the segmentation branch to achieve refined human part segmentation maps, and effectively divide the human body into reasonable groups. Finally, several cases demonstrate the efficiency of the proposed model in distinguishing different representative parts of the human body, which can avoid the background and occlusion disturbs. Our method consistently achieves state-of-the-art results on several popular datasets, including occluded, partial, and holistic.
The Effect of Training Parameters and Mechanisms on Decentralized Federated Learning based on MNIST Dataset
Aug 07, 2021

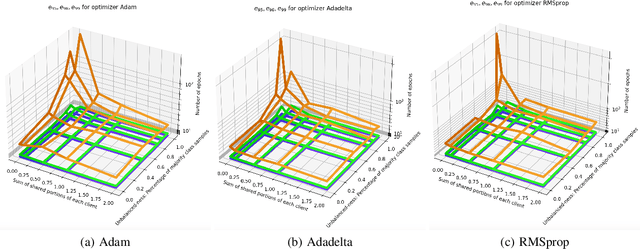

Federated Learning is an algorithm suited for training models on decentralized data, but the requirement of a central "server" node is a bottleneck. In this document, we first introduce the notion of Decentralized Federated Learning (DFL). We then perform various experiments on different setups, such as changing model aggregation frequency, switching from independent and identically distributed (IID) dataset partitioning to non-IID partitioning with partial global sharing, using different optimization methods across clients, and breaking models into segments with partial sharing. All experiments are run on the MNIST handwritten digits dataset. We observe that those altered training procedures are generally robust, albeit non-optimal. We also observe failures in training when the variance between model weights is too large. The open-source experiment code is accessible through GitHub\footnote{Code was uploaded at \url{https://github.com/zhzhang2018/DecentralizedFL}}.
What Makes a Star Teacher? A Hierarchical BERT Model for Evaluating Teacher's Performance in Online Education
Dec 03, 2020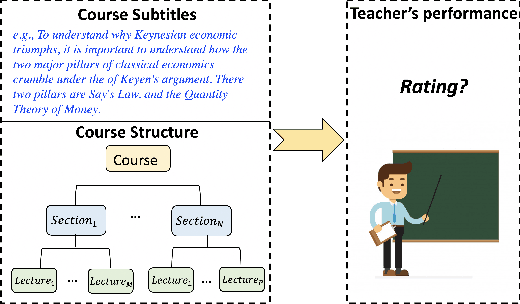
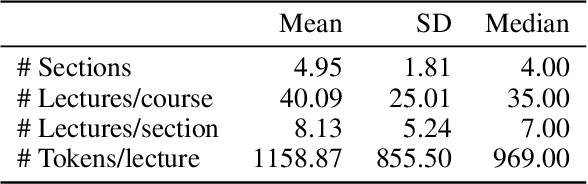
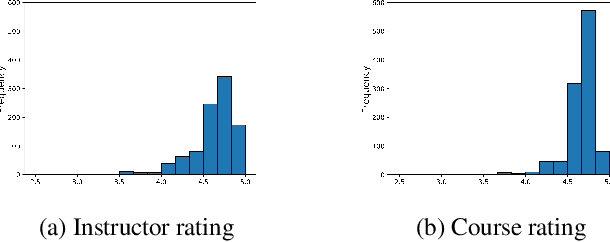
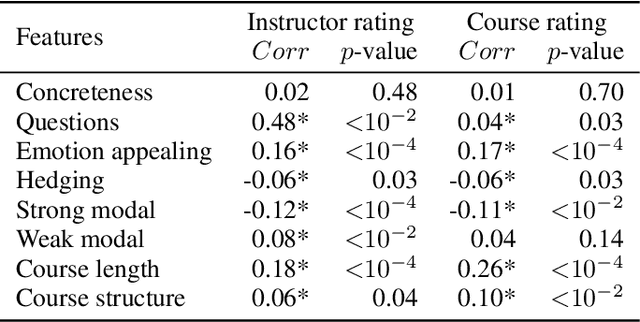
Education has a significant impact on both society and personal life. With the development of technology, online education has been growing rapidly over the past decade. While there are several online education studies on student behavior analysis, the course concept mining, and course recommendations (Feng, Tang, and Liu 2019; Pan et al. 2017), there is little research on evaluating teachers' performance in online education. In this paper, we conduct a systematic study to understand and effectively predict teachers' performance using the subtitles of 1,085 online courses. Our model-free analysis shows that teachers' verbal cues (e.g., question strategy, emotional appealing, and hedging) and their course structure design are both significantly correlated with teachers' performance evaluation. Based on these insights, we then propose a hierarchical course BERT model to predict teachers' performance in online education. Our proposed model can capture the hierarchical structure within each course as well as the deep semantic features extracted from the course content. Experiment results show that our proposed method achieves significant gain over several state-of-the-art methods. Our study provides a significant social impact in helping teachers improve their teaching style and enhance their instructional material design for more effective online teaching in the future.