 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Return-to-Go for Efficient Decision Transformer
Jan 22, 2026The Decision Transformer (DT) has established a powerful sequence modeling approach to offline reinforcement learning. It conditions its action predictions on Return-to-Go (RTG), using it both to distinguish trajectory quality during training and to guide action generation at inference. In this work, we identify a critical redundancy in this design: feeding the entire sequence of RTGs into the Transformer is theoretically unnecessary, as only the most recent RTG affects action prediction. We show that this redundancy can impair DT's performance through experiments. To resolve this, we propose the Decoupled DT (DDT). DDT simplifies the architecture by processing only observation and action sequences through the Transformer, using the latest RTG to guide the action prediction. This streamlined approach not only improves performance but also reduces computational cost. Our experiments show that DDT significantly outperforms DT and establishes competitive performance against state-of-the-art DT variants across multiple offline RL tasks.
FOD-Diff: 3D Multi-Channel Patch Diffusion Model for Fiber Orientation Distribution
Dec 18, 2025Diffusion MRI (dMRI) is a critical non-invasive technique to estimate fiber orientation distribution (FOD) for characterizing white matter integrity. Estimating FOD from single-shell low angular resolution dMRI (LAR-FOD) is limited by accuracy, whereas estimating FOD from multi-shell high angular resolution dMRI (HAR-FOD) requires a long scanning time, which limits its applicability. Diffusion models have shown promise in estimating HAR-FOD based on LAR-FOD. However, using diffusion models to efficiently generate HAR-FOD is challenging due to the large number of spherical harmonic (SH) coefficients in FOD. Here, we propose a 3D multi-channel patch diffusion model to predict HAR-FOD from LAR-FOD. We design the FOD-patch adapter by introducing the prior brain anatomy for more efficient patch-based learning. Furthermore, we introduce a voxel-level conditional coordinating module to enhance the global understanding of the model. We design the SH attention module to effectively learn the complex correlations of the SH coefficients. Our experimental results show that our method achieves the best performance in HAR-FOD prediction and outperforms other state-of-the-art methods.
Motus: A Unified Latent Action World Model
Dec 15, 2025While a general embodied agent must function as a unified system, current methods are built on isolated models for understanding, world modeling, and control. This fragmentation prevents unifying multimodal generative capabilities and hinders learning from large-scale, heterogeneous data. In this paper, we propose Motus, a unified latent action world model that leverages existing general pretrained models and rich, sharable motion information. Motus introduces a Mixture-of-Transformer (MoT) architecture to integrate three experts (i.e., understanding, video generation, and action) and adopts a UniDiffuser-style scheduler to enable flexible switching between different modeling modes (i.e., world models, vision-language-action models, inverse dynamics models, video generation models, and video-action joint prediction models). Motus further leverages the optical flow to learn latent actions and adopts a recipe with three-phase training pipeline and six-layer data pyramid, thereby extracting pixel-level "delta action" and enabling large-scale action pretraining. Experiments show that Motus achieves superior performance against state-of-the-art methods in both simulation (a +15% improvement over X-VLA and a +45% improvement over Pi0.5) and real-world scenarios(improved by +11~48%), demonstrating unified modeling of all functionalities and priors significantly benefits downstream robotic tasks.
Generative AI Meets Wireless Sensing: Towards Wireless Foundation Model
Sep 18, 2025



Generative Artificial Intelligence (GenAI) has made significant advancements in fields such as computer vision (CV) and natural language processing (NLP), demonstrating its capability to synthesize high-fidelity data and improve generalization. Recently, there has been growing interest in integrating GenAI into wireless sensing systems. By leveraging generative techniques such as data augmentation, domain adaptation, and denoising, wireless sensing applications, including device localization, human activity recognition, and environmental monitoring, can be significantly improved. This survey investigates the convergence of GenAI and wireless sensing from two complementary perspectives. First, we explore how GenAI can be integrated into wireless sensing pipelines, focusing on two modes of integration: as a plugin to augment task-specific models and as a solver to directly address sensing tasks. Second, we analyze the characteristics of mainstream generative models, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models, and discuss their applicability and unique advantages across various wireless sensing tasks. We further identify key challenges in applying GenAI to wireless sensing and outline a future direction toward a wireless foundation model: a unified, pre-trained design capable of scalable, adaptable, and efficient signal understanding across diverse sensing tasks.
RoboMatch: A Mobile-Manipulation Teleoperation Platform with Auto-Matching Network Architecture for Long-Horizon Manipulation
Sep 10, 2025



This paper presents RoboMatch, a novel unified teleoperation platform for mobile manipulation with an auto-matching network architecture, designed to tackle long-horizon tasks in dynamic environments. Our system enhances teleoperation performance, data collection efficiency, task accuracy, and operational stability. The core of RoboMatch is a cockpit-style control interface that enables synchronous operation of the mobile base and dual arms, significantly improving control precision and data collection. Moreover, we introduce the Proprioceptive-Visual Enhanced Diffusion Policy (PVE-DP), which leverages Discrete Wavelet Transform (DWT) for multi-scale visual feature extraction and integrates high-precision IMUs at the end-effector to enrich proprioceptive feedback, substantially boosting fine manipulation performance. Furthermore, we propose an Auto-Matching Network (AMN) architecture that decomposes long-horizon tasks into logical sequences and dynamically assigns lightweight pre-trained models for distributed inference. Experimental results demonstrate that our approach improves data collection efficiency by over 20%, increases task success rates by 20-30% with PVE-DP, and enhances long-horizon inference performance by approximately 40% with AMN, offering a robust solution for complex manipulation tasks.
HaDM-ST: Histology-Assisted Differential Modeling for Spatial Transcriptomics Generation
Aug 10, 2025Spatial transcriptomics (ST) reveals spatial heterogeneity of gene expression, yet its resolution is limited by current platforms. Recent methods enhance resolution via H&E-stained histology, but three major challenges persist: (1) isolating expression-relevant features from visually complex H&E images; (2) achieving spatially precise multimodal alignment in diffusion-based frameworks; and (3) modeling gene-specific variation across expression channels. We propose HaDM-ST (Histology-assisted Differential Modeling for ST Generation), a high-resolution ST generation framework conditioned on H&E images and low-resolution ST. HaDM-ST includes: (i) a semantic distillation network to extract predictive cues from H&E; (ii) a spatial alignment module enforcing pixel-wise correspondence with low-resolution ST; and (iii) a channel-aware adversarial learner for fine-grained gene-level modeling. Experiments on 200 genes across diverse tissues and species show HaDM-ST consistently outperforms prior methods, enhancing spatial fidelity and gene-level coherence in high-resolution ST predictions.
USAD: An Unsupervised Data Augmentation Spatio-Temporal Attention Diffusion Network
Jul 03, 2025The primary objective of human activity recognition (HAR) is to infer ongoing human actions from sensor data, a task that finds broad applications in health monitoring, safety protection, and sports analysis. Despite proliferating research, HAR still faces key challenges, including the scarcity of labeled samples for rare activities, insufficient extraction of high-level features, and suboptimal model performance on lightweight devices. To address these issues, this paper proposes a comprehensive optimization approach centered on multi-attention interaction mechanisms. First, an unsupervised, statistics-guided diffusion model is employed to perform data augmentation, thereby alleviating the problems of labeled data scarcity and severe class imbalance. Second, a multi-branch spatio-temporal interaction network is designed, which captures multi-scale features of sequential data through parallel residual branches with 3*3, 5*5, and 7*7 convolutional kernels. Simultaneously, temporal attention mechanisms are incorporated to identify critical time points, while spatial attention enhances inter-sensor interactions. A cross-branch feature fusion unit is further introduced to improve the overall feature representation capability. Finally, an adaptive multi-loss function fusion strategy is integrated, allowing for dynamic adjustment of loss weights and overall model optimization. Experimental results on three public datasets, WISDM, PAMAP2, and OPPORTUNITY, demonstrate that the proposed unsupervised data augmentation spatio-temporal attention diffusion network (USAD) achieves accuracies of 98.84%, 93.81%, and 80.92% respectively, significantly outperforming existing approaches. Furthermore, practical deployment on embedded devices verifies the efficiency and feasibility of the proposed method.
Confidence-driven Gradient Modulation for Multimodal Human Activity Recognition: A Dynamic Contrastive Dual-Path Learning Approach
Jul 03, 2025Sensor-based Human Activity Recognition (HAR) is a core technology that enables intelligent systems to perceive and interact with their environment. However, multimodal HAR systems still encounter key challenges, such as difficulties in cross-modal feature alignment and imbalanced modality contributions. To address these issues, we propose a novel framework called the Dynamic Contrastive Dual-Path Network (DCDP-HAR). The framework comprises three key components. First, a dual-path feature extraction architecture is employed, where ResNet and DenseNet branches collaboratively process multimodal sensor data. Second, a multi-stage contrastive learning mechanism is introduced to achieve progressive alignment from local perception to semantic abstraction. Third, we present a confidence-driven gradient modulation strategy that dynamically monitors and adjusts the learning intensity of each modality branch during backpropagation, effectively alleviating modality competition. In addition, a momentum-based gradient accumulation strategy is adopted to enhance training stability. We conduct ablation studies to validate the effectiveness of each component and perform extensive comparative experiments on four public benchmark datasets.
Enhancing the Efficiency of Complex Systems Crystal Structure Prediction by Active Learning Guided Machine Learning Potential
May 13, 2025Understanding multicomponent complex material systems is essential for design of advanced materials for a wide range of technological applications. While state-of-the-art crystal structure prediction (CSP) methods effectively identify new structures and assess phase stability, they face fundamental limitations when applied to complex systems. This challenge stems from the combinatorial explosion of atomic configurations and the vast stoichiometric space, both of which contribute to computational demands that rapidly exceed practical feasibility. In this work, we propose a flexible and automated workflow to build a highly generalizable and data-efficient machine learning potential (MLP), effectively unlocking the full potential of CSP algorithms. The workflow is validated on both Mg-Ca-H ternary and Be-P-N-O quaternary systems, demonstrating substantial machine learning acceleration in high-throughput structural optimization and enabling the efficient identification of promising compounds. These results underscore the effectiveness of our approach in exploring complex material systems and accelerating the discovery of new multicomponent materials.
Redundant feature screening method for human activity recognition based on attention purification mechanism
Mar 30, 2025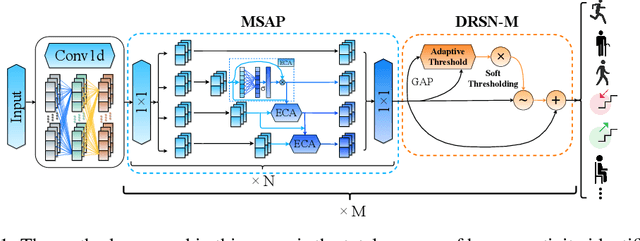
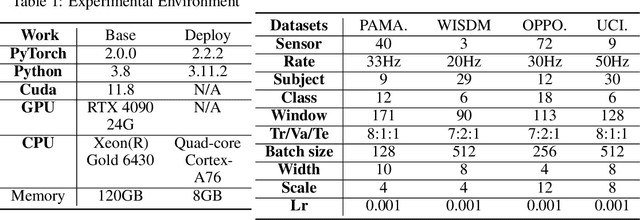
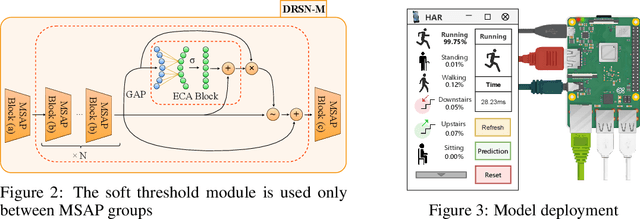
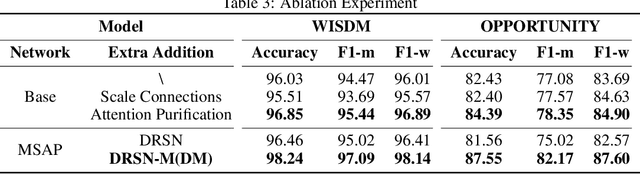
In the field of sensor-based Human Activity Recognition (HAR), deep neural networks provide advanced technical support. Many studies have proven that recognition accuracy can be improved by increasing the depth or width of the network. However, for wearable devices, the balance between network performance and resource consumption is crucial. With minimum resource consumption as the basic principle, we propose a universal attention feature purification mechanism, called MSAP, which is suitable for multi-scale networks. The mechanism effectively solves the feature redundancy caused by the superposition of multi-scale features by means of inter-scale attention screening and connection method. In addition, we have designed a network correction module that integrates seamlessly between layers of individual network modules to mitigate inherent problems in deep networks. We also built an embedded deployment system that is in line with the current level of wearable technology to test the practical feasibility of the HAR model, and further prove the efficiency of the method. Extensive experiments on four public datasets show that the proposed method model effectively reduces redundant features in filtered data and provides excellent performance with little resource consumption.