 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Closer! An Adversarial Parametric Editing Framework for Hallucination Mitigation in VLMs
Dec 26, 2025While Vision-Language Models (VLMs) have garnered increasing attention in the AI community due to their promising practical applications, they exhibit persistent hallucination issues, generating outputs misaligned with visual inputs. Recent studies attribute these hallucinations to VLMs' over-reliance on linguistic priors and insufficient visual feature integration, proposing heuristic decoding calibration strategies to mitigate them. However, the non-trainable nature of these strategies inherently limits their optimization potential. To this end, we propose an adversarial parametric editing framework for Hallucination mitigation in VLMs, which follows an \textbf{A}ctivate-\textbf{L}ocate-\textbf{E}dit \textbf{A}dversarially paradigm. Specifically, we first construct an activation dataset that comprises grounded responses (positive samples attentively anchored in visual features) and hallucinatory responses (negative samples reflecting LLM prior bias and internal knowledge artifacts). Next, we identify critical hallucination-prone parameter clusters by analyzing differential hidden states of response pairs. Then, these clusters are fine-tuned using prompts injected with adversarial tuned prefixes that are optimized to maximize visual neglect, thereby forcing the model to prioritize visual evidence over inherent parametric biases. Evaluations on both generative and discriminative VLM tasks demonstrate the significant effectiveness of ALEAHallu in alleviating hallucinations. Our code is available at https://github.com/hujiayu1223/ALEAHallu.
The geomagnetic storm and Kp prediction using Wasserstein transformer
Mar 29, 2025The accurate forecasting of geomagnetic activity is important. In this work, we present a novel multimodal Transformer based framework for predicting the 3 days and 5 days planetary Kp index by integrating heterogeneous data sources, including satellite measurements, solar images, and KP time series. A key innovation is the incorporation of the Wasserstein distance into the transformer and the loss function to align the probability distributions across modalities. Comparative experiments with the NOAA model demonstrate performance, accurately capturing both the quiet and storm phases of geomagnetic activity. This study underscores the potential of integrating machine learning techniques with traditional models for improved real time forecasting.
Semantic Gaussian Mixture Variational Autoencoder for Sequential Recommendation
Feb 22, 2025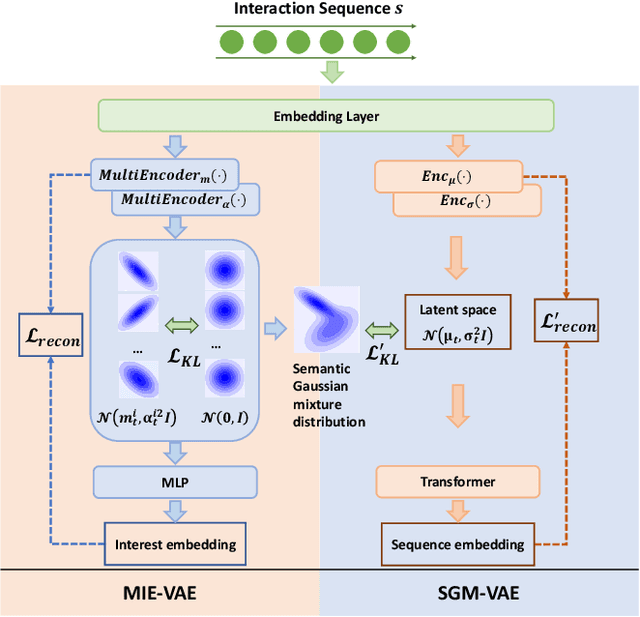
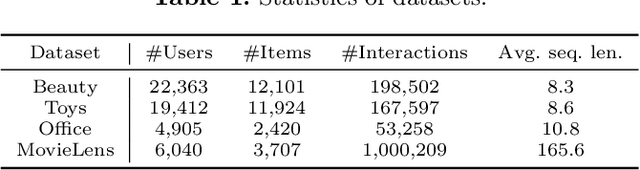
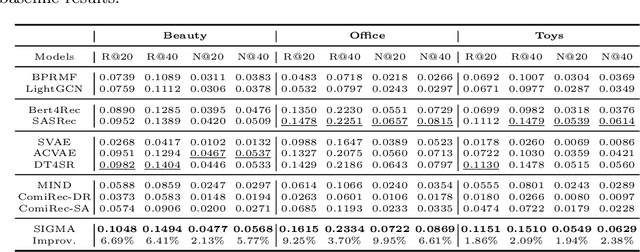
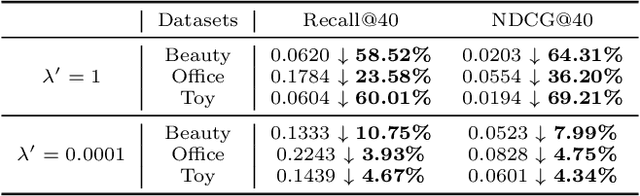
Variational AutoEncoder (VAE) for Sequential Recommendation (SR), which learns a continuous distribution for each user-item interaction sequence rather than a determinate embedding, is robust against data deficiency and achieves significant performance. However, existing VAE-based SR models assume a unimodal Gaussian distribution as the prior distribution of sequence representations, leading to restricted capability to capture complex user interests and limiting recommendation performance when users have more than one interest. Due to that it is common for users to have multiple disparate interests, we argue that it is more reasonable to establish a multimodal prior distribution in SR scenarios instead of a unimodal one. Therefore, in this paper, we propose a novel VAE-based SR model named SIGMA. SIGMA assumes that the prior of sequence representation conforms to a Gaussian mixture distribution, where each component of the distribution semantically corresponds to one of multiple interests. For multi-interest elicitation, SIGMA includes a probabilistic multi-interest extraction module that learns a unimodal Gaussian distribution for each interest according to implicit item hyper-categories. Additionally, to incorporate the multimodal interests into sequence representation learning, SIGMA constructs a multi-interest-aware ELBO, which is compatible with the Gaussian mixture prior. Extensive experiments on public datasets demonstrate the effectiveness of SIGMA. The code is available at https://github.com/libeibei95/SIGMA.
Multi-Pair Temporal Sentence Grounding via Multi-Thread Knowledge Transfer Network
Dec 20, 2024



Given some video-query pairs with untrimmed videos and sentence queries, temporal sentence grounding (TSG) aims to locate query-relevant segments in these videos. Although previous respectable TSG methods have achieved remarkable success, they train each video-query pair separately and ignore the relationship between different pairs. We observe that the similar video/query content not only helps the TSG model better understand and generalize the cross-modal representation but also assists the model in locating some complex video-query pairs. Previous methods follow a single-thread framework that cannot co-train different pairs and usually spends much time re-obtaining redundant knowledge, limiting their real-world applications. To this end, in this paper, we pose a brand-new setting: Multi-Pair TSG, which aims to co-train these pairs. In particular, we propose a novel video-query co-training approach, Multi-Thread Knowledge Transfer Network, to locate a variety of video-query pairs effectively and efficiently. Firstly, we mine the spatial and temporal semantics across different queries to cooperate with each other. To learn intra- and inter-modal representations simultaneously, we design a cross-modal contrast module to explore the semantic consistency by a self-supervised strategy. To fully align visual and textual representations between different pairs, we design a prototype alignment strategy to 1) match object prototypes and phrase prototypes for spatial alignment, and 2) align activity prototypes and sentence prototypes for temporal alignment. Finally, we develop an adaptive negative selection module to adaptively generate a threshold for cross-modal matching. Extensive experiments show the effectiveness and efficiency of our proposed method.
Grimm: A Plug-and-Play Perturbation Rectifier for Graph Neural Networks Defending against Poisoning Attacks
Dec 11, 2024

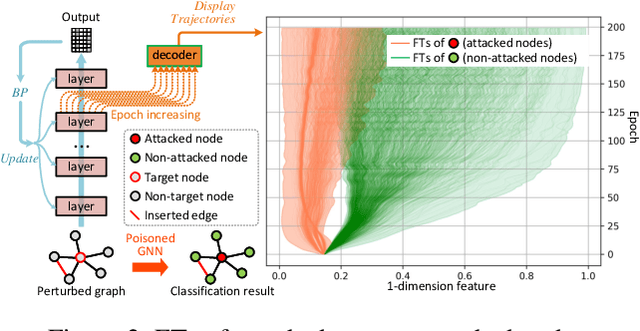

End-to-end training with global optimization have popularized graph neural networks (GNNs) for node classification, yet inadvertently introduced vulnerabilities to adversarial edge-perturbing attacks. Adversaries can exploit the inherent opened interfaces of GNNs' input and output, perturbing critical edges and thus manipulating the classification results. Current defenses, due to their persistent utilization of global-optimization-based end-to-end training schemes, inherently encapsulate the vulnerabilities of GNNs. This is specifically evidenced in their inability to defend against targeted secondary attacks. In this paper, we propose the Graph Agent Network (GAgN) to address the aforementioned vulnerabilities of GNNs. GAgN is a graph-structured agent network in which each node is designed as an 1-hop-view agent. Through the decentralized interactions between agents, they can learn to infer global perceptions to perform tasks including inferring embeddings, degrees and neighbor relationships for given nodes. This empowers nodes to filtering adversarial edges while carrying out classification tasks. Furthermore, agents' limited view prevents malicious messages from propagating globally in GAgN, thereby resisting global-optimization-based secondary attacks. We prove that single-hidden-layer multilayer perceptrons (MLPs) are theoretically sufficient to achieve these functionalities. Experimental results show that GAgN effectively implements all its intended capabilities and, compared to state-of-the-art defenses, achieves optimal classification accuracy on the perturbed datasets.
An Unbiased Risk Estimator for Partial Label Learning with Augmented Classes
Sep 29, 2024Partial Label Learning (PLL) is a typical weakly supervised learning task, which assumes each training instance is annotated with a set of candidate labels containing the ground-truth label. Recent PLL methods adopt identification-based disambiguation to alleviate the influence of false positive labels and achieve promising performance. However, they require all classes in the test set to have appeared in the training set, ignoring the fact that new classes will keep emerging in real applications. To address this issue, in this paper, we focus on the problem of Partial Label Learning with Augmented Class (PLLAC), where one or more augmented classes are not visible in the training stage but appear in the inference stage. Specifically, we propose an unbiased risk estimator with theoretical guarantees for PLLAC, which estimates the distribution of augmented classes by differentiating the distribution of known classes from unlabeled data and can be equipped with arbitrary PLL loss functions. Besides, we provide a theoretical analysis of the estimation error bound of the estimator, which guarantees the convergence of the empirical risk minimizer to the true risk minimizer as the number of training data tends to infinity. Furthermore, we add a risk-penalty regularization term in the optimization objective to alleviate the influence of the over-fitting issue caused by negative empirical risk. Extensive experiments on benchmark, UCI and real-world datasets demonstrate the effectiveness of the proposed approach.
AsyCo: An Asymmetric Dual-task Co-training Model for Partial-label Learning
Jul 21, 2024

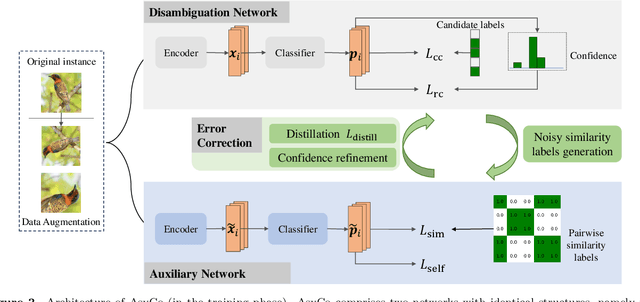
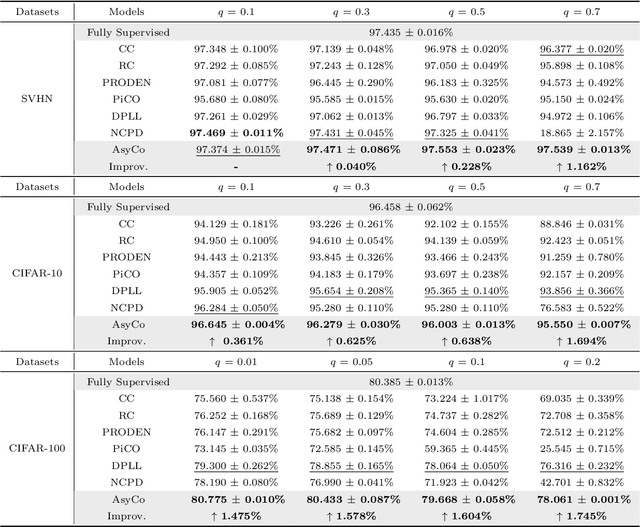
Partial-Label Learning (PLL) is a typical problem of weakly supervised learning, where each training instance is annotated with a set of candidate labels. Self-training PLL models achieve state-of-the-art performance but suffer from error accumulation problem caused by mistakenly disambiguated instances. Although co-training can alleviate this issue by training two networks simultaneously and allowing them to interact with each other, most existing co-training methods train two structurally identical networks with the same task, i.e., are symmetric, rendering it insufficient for them to correct each other due to their similar limitations. Therefore, in this paper, we propose an asymmetric dual-task co-training PLL model called AsyCo, which forces its two networks, i.e., a disambiguation network and an auxiliary network, to learn from different views explicitly by optimizing distinct tasks. Specifically, the disambiguation network is trained with self-training PLL task to learn label confidence, while the auxiliary network is trained in a supervised learning paradigm to learn from the noisy pairwise similarity labels that are constructed according to the learned label confidence. Finally, the error accumulation problem is mitigated via information distillation and confidence refinement. Extensive experiments on both uniform and instance-dependent partially labeled datasets demonstrate the effectiveness of AsyCo. The code is available at https://github.com/libeibeics/AsyCo.
Denoising Long- and Short-term Interests for Sequential Recommendation
Jul 20, 2024



User interests can be viewed over different time scales, mainly including stable long-term preferences and changing short-term intentions, and their combination facilitates the comprehensive sequential recommendation. However, existing work that focuses on different time scales of user modeling has ignored the negative effects of different time-scale noise, which hinders capturing actual user interests and cannot be resolved by conventional sequential denoising methods. In this paper, we propose a Long- and Short-term Interest Denoising Network (LSIDN), which employs different encoders and tailored denoising strategies to extract long- and short-term interests, respectively, achieving both comprehensive and robust user modeling. Specifically, we employ a session-level interest extraction and evolution strategy to avoid introducing inter-session behavioral noise into long-term interest modeling; we also adopt contrastive learning equipped with a homogeneous exchanging augmentation to alleviate the impact of unintentional behavioral noise on short-term interest modeling. Results of experiments on two public datasets show that LSIDN consistently outperforms state-of-the-art models and achieves significant robustness.
Orthogonal Hyper-category Guided Multi-interest Elicitation for Micro-video Matching
Jul 20, 2024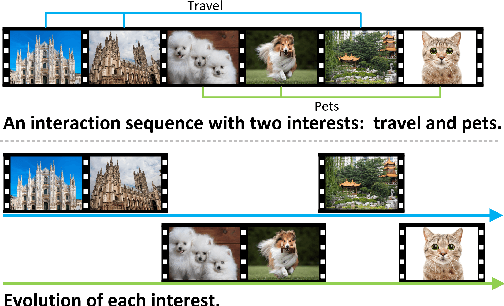
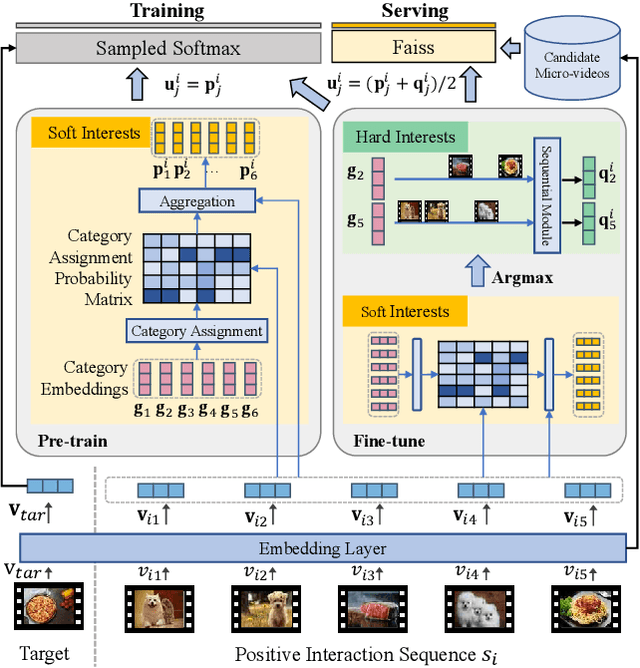
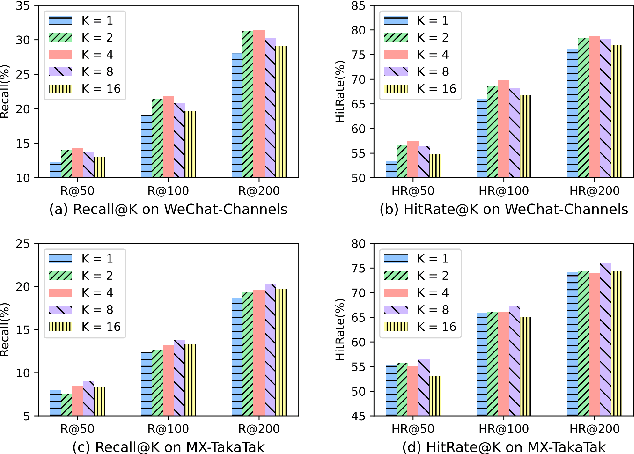
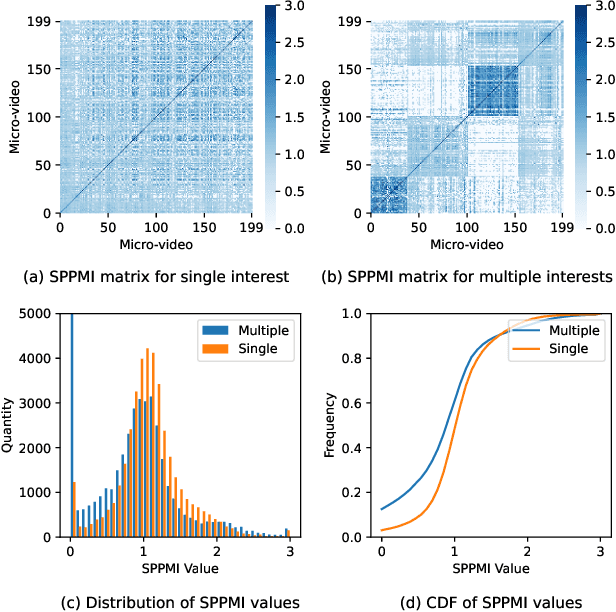
Watching micro-videos is becoming a part of public daily life. Usually, user watching behaviors are thought to be rooted in their multiple different interests. In the paper, we propose a model named OPAL for micro-video matching, which elicits a user's multiple heterogeneous interests by disentangling multiple soft and hard interest embeddings from user interactions. Moreover, OPAL employs a two-stage training strategy, in which the pre-train is to generate soft interests from historical interactions under the guidance of orthogonal hyper-categories of micro-videos and the fine-tune is to reinforce the degree of disentanglement among the interests and learn the temporal evolution of each interest of each user. We conduct extensive experiments on two real-world datasets. The results show that OPAL not only returns diversified micro-videos but also outperforms six state-of-the-art models in terms of recall and hit rate.
Tuning Vision-Language Models with Candidate Labels by Prompt Alignment
Jul 11, 2024



Vision-language models (VLMs) can learn high-quality representations from a large-scale training dataset of image-text pairs. Prompt learning is a popular approach to fine-tuning VLM to adapt them to downstream tasks. Despite the satisfying performance, a major limitation of prompt learning is the demand for labelled data. In real-world scenarios, we may only obtain candidate labels (where the true label is included) instead of the true labels due to data privacy or sensitivity issues. In this paper, we provide the first study on prompt learning with candidate labels for VLMs. We empirically demonstrate that prompt learning is more advantageous than other fine-tuning methods, for handling candidate labels. Nonetheless, its performance drops when the label ambiguity increases. In order to improve its robustness, we propose a simple yet effective framework that better leverages the prior knowledge of VLMs to guide the learning process with candidate labels. Specifically, our framework disambiguates candidate labels by aligning the model output with the mixed class posterior jointly predicted by both the learnable and the handcrafted prompt. Besides, our framework can be equipped with various off-the-shelf training objectives for learning with candidate labels to further improve their performance. Extensive experiments demonstrate the effectiveness of our proposed framework.