 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Sparse Attention on Long-term Behaviors for CTR Prediction
Jan 25, 2026In recent years, the success of large language models (LLMs) has driven the exploration of scaling laws in recommender systems. However, models that demonstrate scaling laws are actually challenging to deploy in industrial settings for modeling long sequences of user behaviors, due to the high computational complexity of the standard self-attention mechanism. Despite various sparse self-attention mechanisms proposed in other fields, they are not fully suited for recommendation scenarios. This is because user behaviors exhibit personalization and temporal characteristics: different users have distinct behavior patterns, and these patterns change over time, with data from these users differing significantly from data in other fields in terms of distribution. To address these challenges, we propose SparseCTR, an efficient and effective model specifically designed for long-term behaviors of users. To be precise, we first segment behavior sequences into chunks in a personalized manner to avoid separating continuous behaviors and enable parallel processing of sequences. Based on these chunks, we propose a three-branch sparse self-attention mechanism to jointly identify users' global interests, interest transitions, and short-term interests. Furthermore, we design a composite relative temporal encoding via learnable, head-specific bias coefficients, better capturing sequential and periodic relationships among user behaviors. Extensive experimental results show that SparseCTR not only improves efficiency but also outperforms state-of-the-art methods. More importantly, it exhibits an obvious scaling law phenomenon, maintaining performance improvements across three orders of magnitude in FLOPs. In online A/B testing, SparseCTR increased CTR by 1.72\% and CPM by 1.41\%. Our source code is available at https://github.com/laiweijiang/SparseCTR.
Semantic Gaussian Mixture Variational Autoencoder for Sequential Recommendation
Feb 22, 2025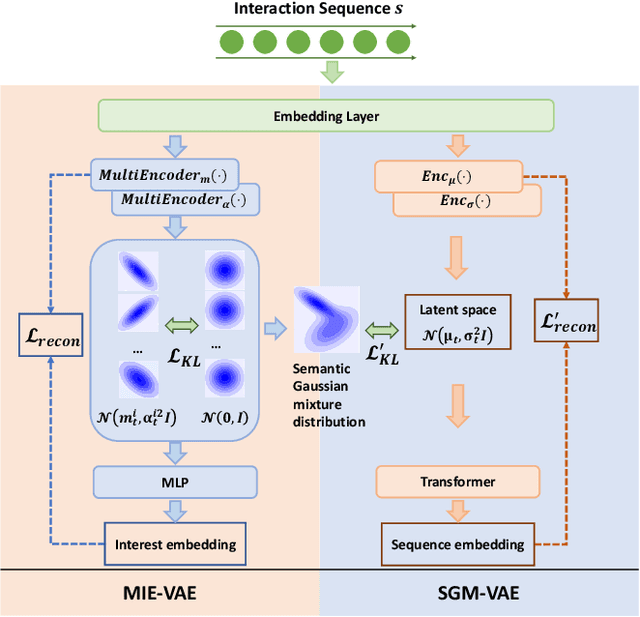
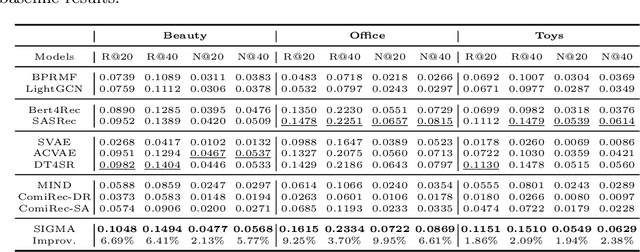
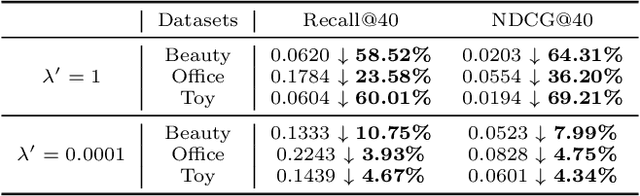
Variational AutoEncoder (VAE) for Sequential Recommendation (SR), which learns a continuous distribution for each user-item interaction sequence rather than a determinate embedding, is robust against data deficiency and achieves significant performance. However, existing VAE-based SR models assume a unimodal Gaussian distribution as the prior distribution of sequence representations, leading to restricted capability to capture complex user interests and limiting recommendation performance when users have more than one interest. Due to that it is common for users to have multiple disparate interests, we argue that it is more reasonable to establish a multimodal prior distribution in SR scenarios instead of a unimodal one. Therefore, in this paper, we propose a novel VAE-based SR model named SIGMA. SIGMA assumes that the prior of sequence representation conforms to a Gaussian mixture distribution, where each component of the distribution semantically corresponds to one of multiple interests. For multi-interest elicitation, SIGMA includes a probabilistic multi-interest extraction module that learns a unimodal Gaussian distribution for each interest according to implicit item hyper-categories. Additionally, to incorporate the multimodal interests into sequence representation learning, SIGMA constructs a multi-interest-aware ELBO, which is compatible with the Gaussian mixture prior. Extensive experiments on public datasets demonstrate the effectiveness of SIGMA. The code is available at https://github.com/libeibei95/SIGMA.
AsyCo: An Asymmetric Dual-task Co-training Model for Partial-label Learning
Jul 21, 2024

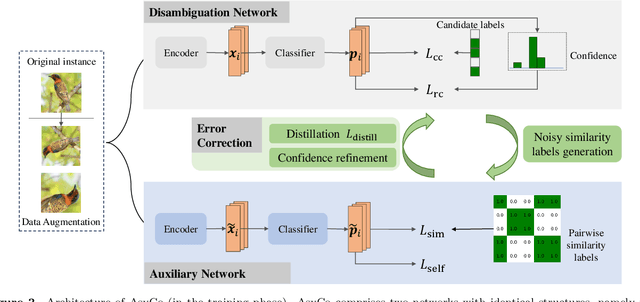
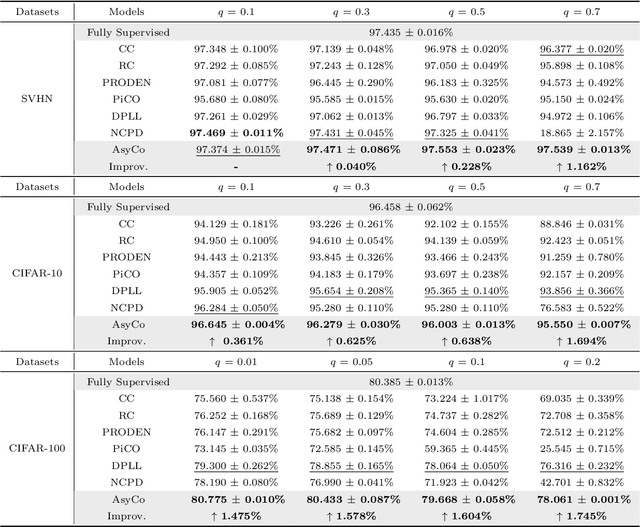
Partial-Label Learning (PLL) is a typical problem of weakly supervised learning, where each training instance is annotated with a set of candidate labels. Self-training PLL models achieve state-of-the-art performance but suffer from error accumulation problem caused by mistakenly disambiguated instances. Although co-training can alleviate this issue by training two networks simultaneously and allowing them to interact with each other, most existing co-training methods train two structurally identical networks with the same task, i.e., are symmetric, rendering it insufficient for them to correct each other due to their similar limitations. Therefore, in this paper, we propose an asymmetric dual-task co-training PLL model called AsyCo, which forces its two networks, i.e., a disambiguation network and an auxiliary network, to learn from different views explicitly by optimizing distinct tasks. Specifically, the disambiguation network is trained with self-training PLL task to learn label confidence, while the auxiliary network is trained in a supervised learning paradigm to learn from the noisy pairwise similarity labels that are constructed according to the learned label confidence. Finally, the error accumulation problem is mitigated via information distillation and confidence refinement. Extensive experiments on both uniform and instance-dependent partially labeled datasets demonstrate the effectiveness of AsyCo. The code is available at https://github.com/libeibeics/AsyCo.
Orthogonal Hyper-category Guided Multi-interest Elicitation for Micro-video Matching
Jul 20, 2024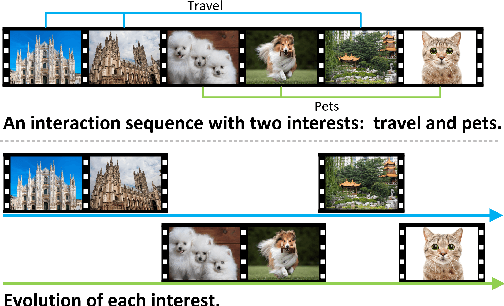
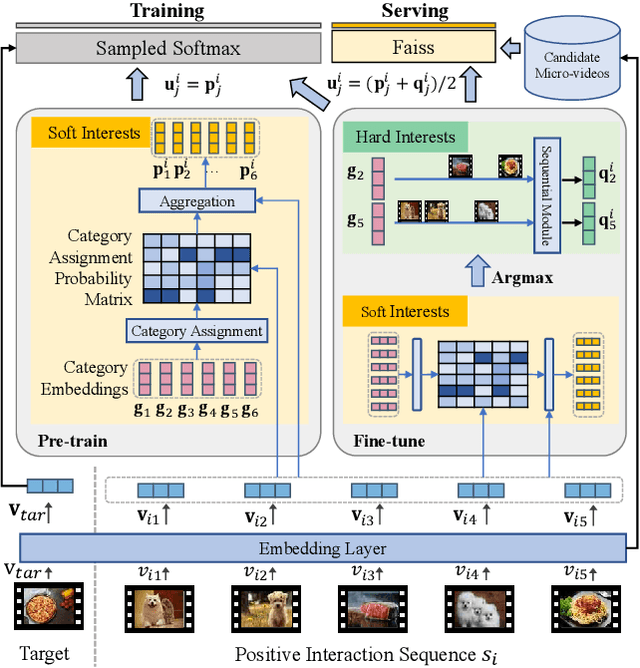
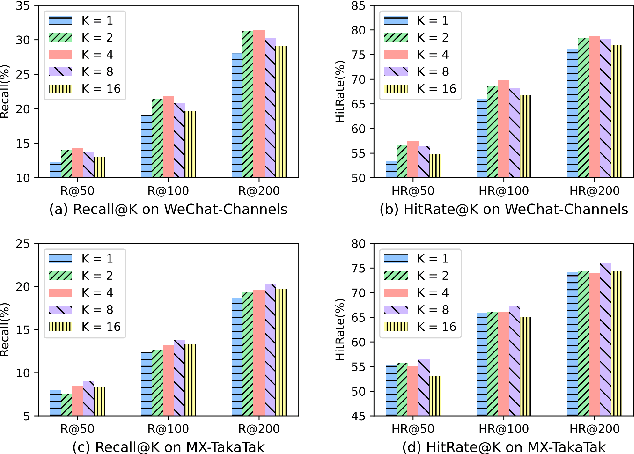
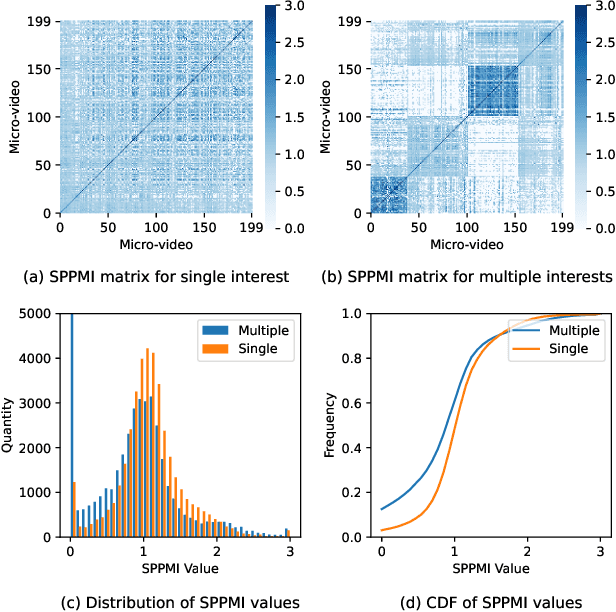
Watching micro-videos is becoming a part of public daily life. Usually, user watching behaviors are thought to be rooted in their multiple different interests. In the paper, we propose a model named OPAL for micro-video matching, which elicits a user's multiple heterogeneous interests by disentangling multiple soft and hard interest embeddings from user interactions. Moreover, OPAL employs a two-stage training strategy, in which the pre-train is to generate soft interests from historical interactions under the guidance of orthogonal hyper-categories of micro-videos and the fine-tune is to reinforce the degree of disentanglement among the interests and learn the temporal evolution of each interest of each user. We conduct extensive experiments on two real-world datasets. The results show that OPAL not only returns diversified micro-videos but also outperforms six state-of-the-art models in terms of recall and hit rate.
Denoising Long- and Short-term Interests for Sequential Recommendation
Jul 20, 2024



User interests can be viewed over different time scales, mainly including stable long-term preferences and changing short-term intentions, and their combination facilitates the comprehensive sequential recommendation. However, existing work that focuses on different time scales of user modeling has ignored the negative effects of different time-scale noise, which hinders capturing actual user interests and cannot be resolved by conventional sequential denoising methods. In this paper, we propose a Long- and Short-term Interest Denoising Network (LSIDN), which employs different encoders and tailored denoising strategies to extract long- and short-term interests, respectively, achieving both comprehensive and robust user modeling. Specifically, we employ a session-level interest extraction and evolution strategy to avoid introducing inter-session behavioral noise into long-term interest modeling; we also adopt contrastive learning equipped with a homogeneous exchanging augmentation to alleviate the impact of unintentional behavioral noise on short-term interest modeling. Results of experiments on two public datasets show that LSIDN consistently outperforms state-of-the-art models and achieves significant robustness.
A Vlogger-augmented Graph Neural Network Model for Micro-video Recommendation
May 28, 2024Existing micro-video recommendation models exploit the interactions between users and micro-videos and/or multi-modal information of micro-videos to predict the next micro-video a user will watch, ignoring the information related to vloggers, i.e., the producers of micro-videos. However, in micro-video scenarios, vloggers play a significant role in user-video interactions, since vloggers generally focus on specific topics and users tend to follow the vloggers they are interested in. Therefore, in the paper, we propose a vlogger-augmented graph neural network model VA-GNN, which takes the effect of vloggers into consideration. Specifically, we construct a tripartite graph with users, micro-videos, and vloggers as nodes, capturing user preferences from different views, i.e., the video-view and the vlogger-view. Moreover, we conduct cross-view contrastive learning to keep the consistency between node embeddings from the two different views. Besides, when predicting the next user-video interaction, we adaptively combine the user preferences for a video itself and its vlogger. We conduct extensive experiments on two real-world datasets. The experimental results show that VA-GNN outperforms multiple existing GNN-based recommendation models.
A Deep Behavior Path Matching Network for Click-Through Rate Prediction
Feb 01, 2023



User behaviors on an e-commerce app not only contain different kinds of feedback on items but also sometimes imply the cognitive clue of the user's decision-making. For understanding the psychological procedure behind user decisions, we present the behavior path and propose to match the user's current behavior path with historical behavior paths to predict user behaviors on the app. Further, we design a deep neural network for behavior path matching and solve three difficulties in modeling behavior paths: sparsity, noise interference, and accurate matching of behavior paths. In particular, we leverage contrastive learning to augment user behavior paths, provide behavior path self-activation to alleviate the effect of noise, and adopt a two-level matching mechanism to identify the most appropriate candidate. Our model shows excellent performance on two real-world datasets, outperforming the state-of-the-art CTR model. Moreover, our model has been deployed on the Meituan food delivery platform and has accumulated 1.6% improvement in CTR and 1.8% improvement in advertising revenue.
A New Approach to Training Multiple Cooperative Agents for Autonomous Driving
Sep 05, 2022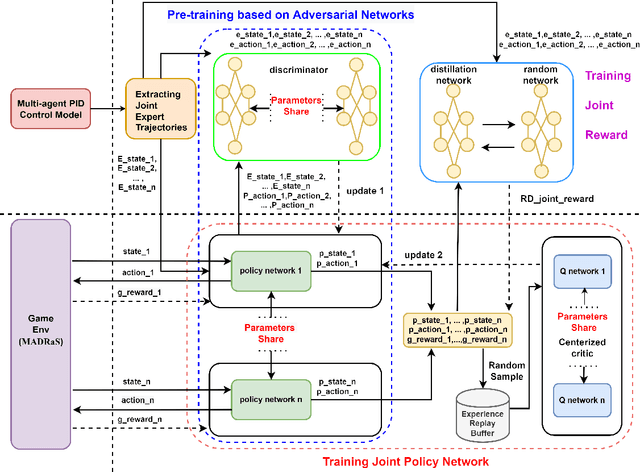
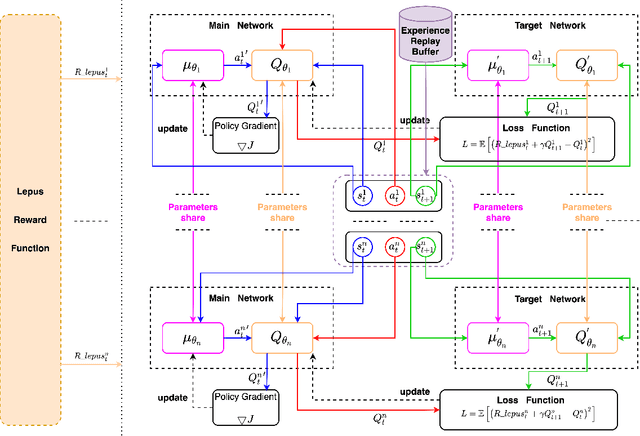
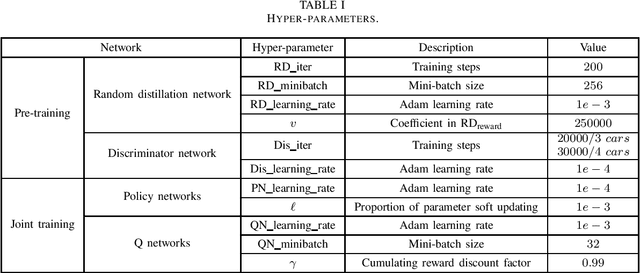
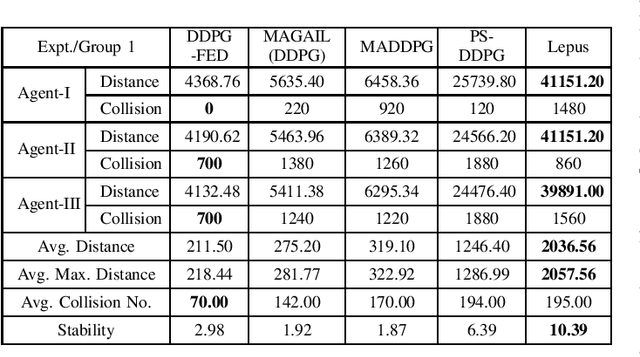
Training multiple agents to perform safe and cooperative control in the complex scenarios of autonomous driving has been a challenge. For a small fleet of cars moving together, this paper proposes Lepus, a new approach to training multiple agents. Lepus adopts a pure cooperative manner for training multiple agents, featured with the shared parameters of policy networks and the shared reward function of multiple agents. In particular, Lepus pre-trains the policy networks via an adversarial process, improving its collaborative decision-making capability and further the stability of car driving. Moreover, for alleviating the problem of sparse rewards, Lepus learns an approximate reward function from expert trajectories by combining a random network and a distillation network. We conduct extensive experiments on the MADRaS simulation platform. The experimental results show that multiple agents trained by Lepus can avoid collisions as many as possible while driving simultaneously and outperform the other four methods, that is, DDPG-FDE, PSDDPG, MADDPG, and MAGAIL(DDPG) in terms of stability.
Improving Micro-video Recommendation by Controlling Position Bias
Aug 09, 2022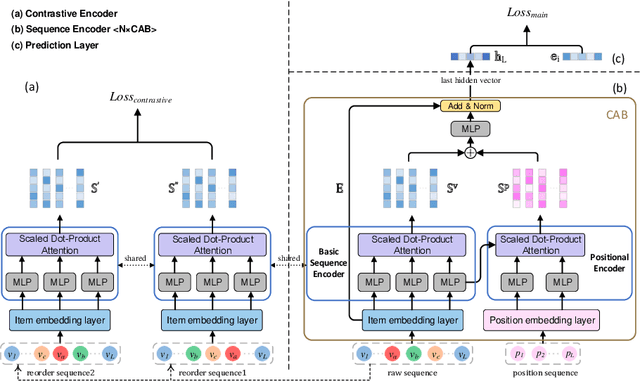
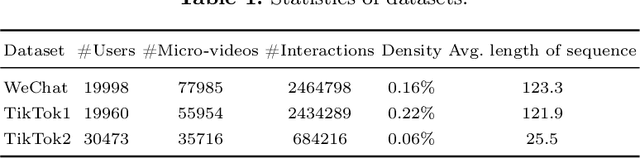
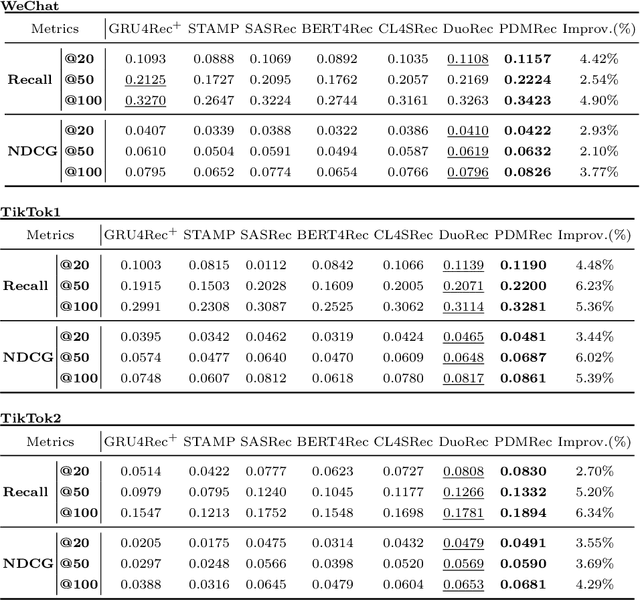
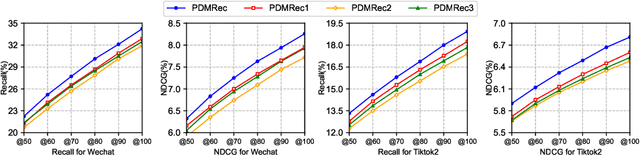
As the micro-video apps become popular, the numbers of micro-videos and users increase rapidly, which highlights the importance of micro-video recommendation. Although the micro-video recommendation can be naturally treated as the sequential recommendation, the previous sequential recommendation models do not fully consider the characteristics of micro-video apps, and in their inductive biases, the role of positions is not in accord with the reality in the micro-video scenario. Therefore, in the paper, we present a model named PDMRec (Position Decoupled Micro-video Recommendation). PDMRec applies separate self-attention modules to model micro-video information and the positional information and then aggregate them together, avoid the noisy correlations between micro-video semantics and positional information being encoded into the sequence embeddings. Moreover, PDMRec proposes contrastive learning strategies which closely match with the characteristics of the micro-video scenario, thus reducing the interference from micro-video positions in sequences. We conduct the extensive experiments on two real-world datasets. The experimental results shows that PDMRec outperforms existing multiple state-of-the-art models and achieves significant performance improvements.
Improving Micro-video Recommendation via Contrastive Multiple Interests
May 19, 2022

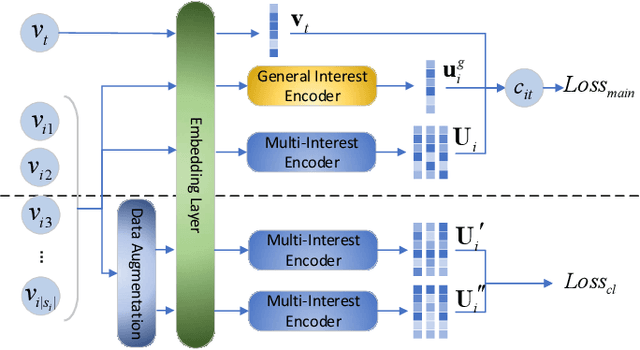
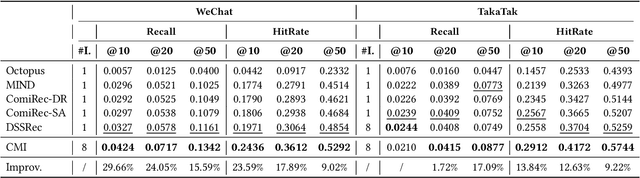
With the rapid increase of micro-video creators and viewers, how to make personalized recommendations from a large number of candidates to viewers begins to attract more and more attention. However, existing micro-video recommendation models rely on expensive multi-modal information and learn an overall interest embedding that cannot reflect the user's multiple interests in micro-videos. Recently, contrastive learning provides a new opportunity for refining the existing recommendation techniques. Therefore, in this paper, we propose to extract contrastive multi-interests and devise a micro-video recommendation model CMI. Specifically, CMI learns multiple interest embeddings for each user from his/her historical interaction sequence, in which the implicit orthogonal micro-video categories are used to decouple multiple user interests. Moreover, it establishes the contrastive multi-interest loss to improve the robustness of interest embeddings and the performance of recommendations. The results of experiments on two micro-video datasets demonstrate that CMI achieves state-of-the-art performance over existing baselines.