 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Micro-video Recommendation by Controlling Position Bias
Paper and Code
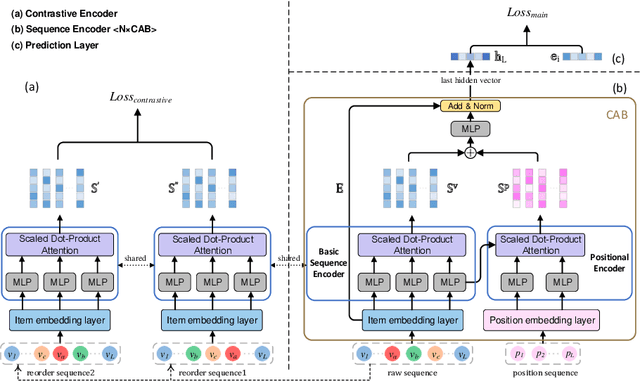
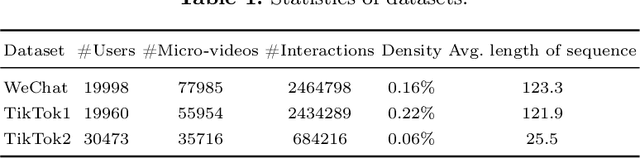
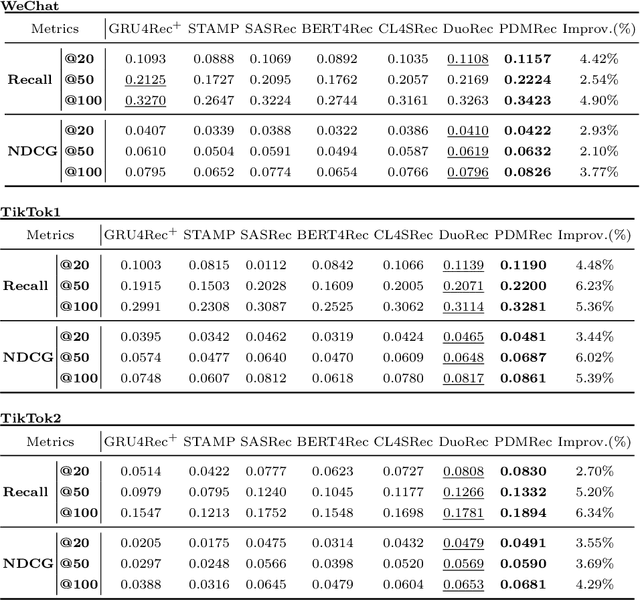
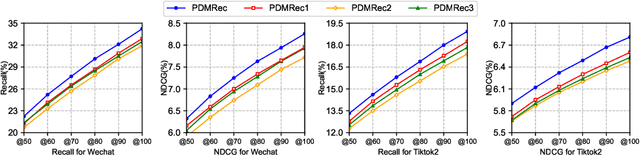
As the micro-video apps become popular, the numbers of micro-videos and users increase rapidly, which highlights the importance of micro-video recommendation. Although the micro-video recommendation can be naturally treated as the sequential recommendation, the previous sequential recommendation models do not fully consider the characteristics of micro-video apps, and in their inductive biases, the role of positions is not in accord with the reality in the micro-video scenario. Therefore, in the paper, we present a model named PDMRec (Position Decoupled Micro-video Recommendation). PDMRec applies separate self-attention modules to model micro-video information and the positional information and then aggregate them together, avoid the noisy correlations between micro-video semantics and positional information being encoded into the sequence embeddings. Moreover, PDMRec proposes contrastive learning strategies which closely match with the characteristics of the micro-video scenario, thus reducing the interference from micro-video positions in sequences. We conduct the extensive experiments on two real-world datasets. The experimental results shows that PDMRec outperforms existing multiple state-of-the-art models and achieves significant performance improvements.